-
-
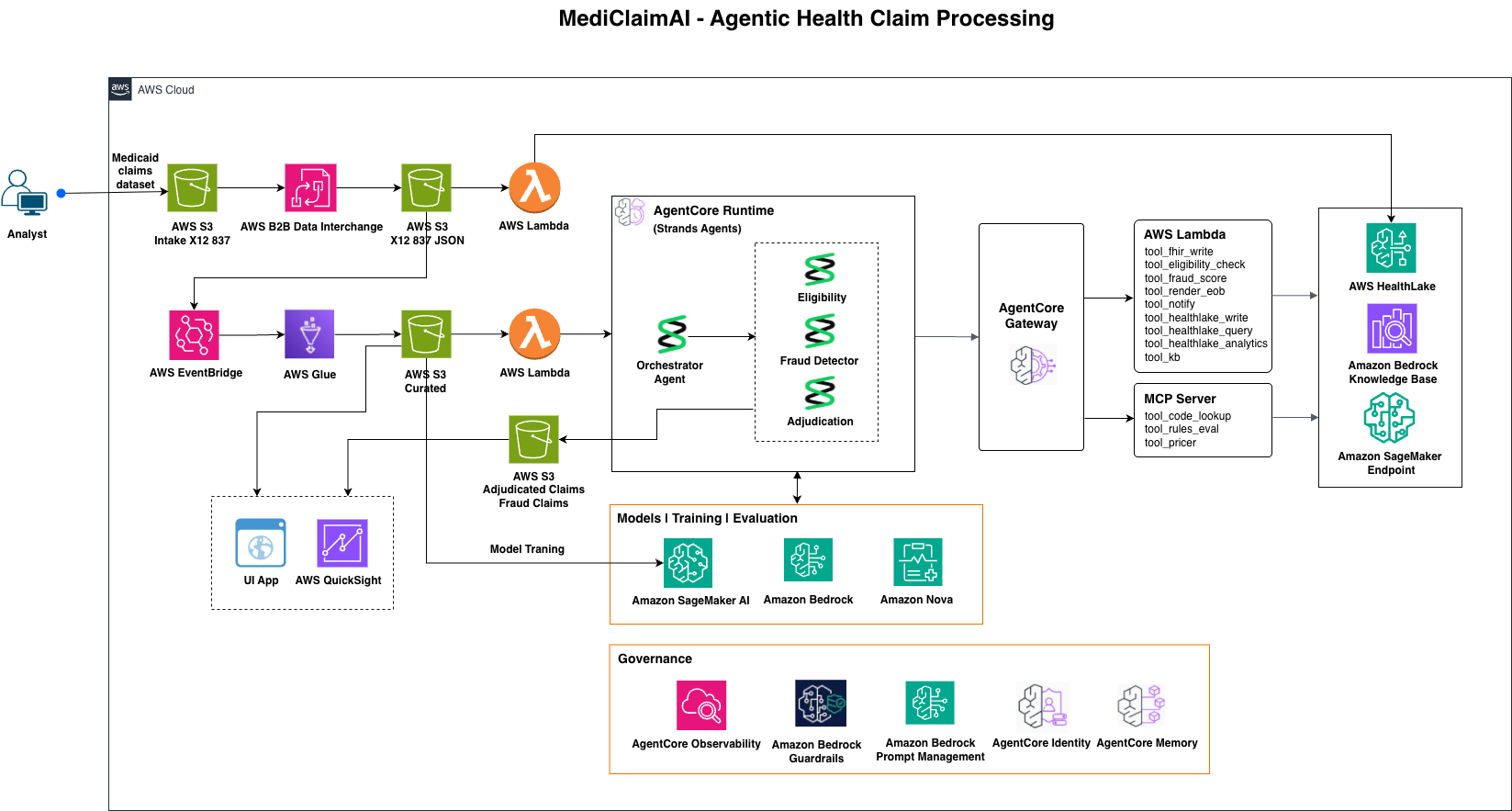
Architecture Diagram
Inspiration
We were inspired by the significant inefficiencies that exist across the Medicaid claims process — from intake to adjudication to fraud review. One of the largest pain points we identified was the volume of fraudulent or improper claims that are paid before detection. We wanted to design a solution that not only improves efficiency but also delivers real-time fraud insights to prevent these payments proactively. We also chose to integrate FHIR standards to align with the future direction of CMS interoperability and simplify downstream reporting, data sharing, and compliance.
What it does
Our solution automates the full lifecycle of Medicaid claims — from ingestion and eligibility verification to fraud detection and final adjudication. Claims are received in X12 format via AWS B2B Data Interchange, converted into FHIR-based JSON, and securely stored in Amazon HealthLake. Three AWS Agents then orchestrate the process:
- A Fraud Detection Agent identifies suspicious claims using a SageMaker model and routes them for human review.
- An Eligibility Agent validates member and provider information in real time.
- An Adjudication Agent applies policy logic and submits approved claims to the state for payment. All data is managed within a HIPAA-eligible AWS environment, ensuring security, transparency, and auditability.
How we built it
We built our solution entirely on AWS Cloud, leveraging:
- AWS B2B Data Interchange helps with EDI format for converting ingested claims dataset in 837P to JSON and JSON/FHIR format.
- AWS Glue and Lambda for data transformation
- Amazon HealthLake and S3 for structured storage
- Amazon SageMaker for fraud prediction
- AWS Step Functions for workflow orchestration
- Amazon Bedrock Guardrails to implement safeguards FHIR served as our data backbone, enabling seamless integration between services and future interoperability with CMS and state systems.
Challenges we ran into
One of our biggest challenges identifying the right features for our fraud model. Determining which claim attributes most accurately signal fraudulent behavior required significant data exploration and tuning. In addition, enforcing a dedicated S3 bucket with restrictive bucket policies for claim storage proved difficult to configure with AWS B2B Data Interchange, which required careful permission management and testing to maintain secure, automated data flow. Finally, normalizing X12 to FHIR formats and balancing automation with human oversight were critical design hurdles to ensure both accuracy and trust.
Accomplishments that we're proud of
We successfully demonstrated an end-to-end claims workflow powered by AI and automation — including real-time fraud detection integrated with eligibility and adjudication. We also implemented FHIR-based data integration with HealthLake, positioning the system for long-term scalability and CMS interoperability. Most importantly, we built a secure, compliant pipeline that could realistically reduce fraud review time by 75% and save thousands of staff hours per month.
What we learned
Throughout this project, we learned how to render clean, properly formatted claim files using AWS B2B Data Interchange, ensuring smooth conversion from X12 to JSON and FHIR formats. We also gained hands-on experience in orchestrating seamless connections between AWS services — including S3, HealthLake, Glue, Lambda, and SageMaker — to create an integrated, secure, and scalable workflow.
What's next for MediClaimAI
Next, we plan to expand our agent framework to include:
- An Intake Agent to handle document uploads and pre-processing,
- An ICD Coding Agent to automate diagnosis and procedure coding, and
- Integration with MLflow pipelines for continuous model retraining and evaluation. We also aim to pilot MediClaimAI with a state Medicaid program, focusing on measurable outcomes in fraud reduction and claims efficiency.
Built With
- amazon-bedrock-agentcore
- amazon-bedrock-guardrails
- amazon-healthlake
- amazon-lambda
- amazon-web-services
- aws-b2b-data-interchange
- aws-glue
- fhir
- sagemaker

Log in or sign up for Devpost to join the conversation.