Inspiration
Health planners can't trust web-scraped facility data at face value: it skews private/urban regions, over-claims specialties, and quickly becomes stale. A planner can't tell which listings are real, which services are actually available, or whether an "empty" district is a true care desert or just a data gap. Truth Atlas is a copilot that earns trust by showing its work.
Truth Atlas' architecture works as a patient referral system or facility registry auditor. Patients find up-to-date, verified facilities and government authorities can track regions that need the most assistance without over relying on messy data. Our product introduces gap scoring, multi-source reconciliation, live verification, scheme-aware recommendations, and uncertainty communication. Every decision turns from a bet on uncertain data into an informed pick based on realtime evidence.
What it does
Truth Atlas is an evidence-backed medical-desert planner with end-to-end trust visibility.
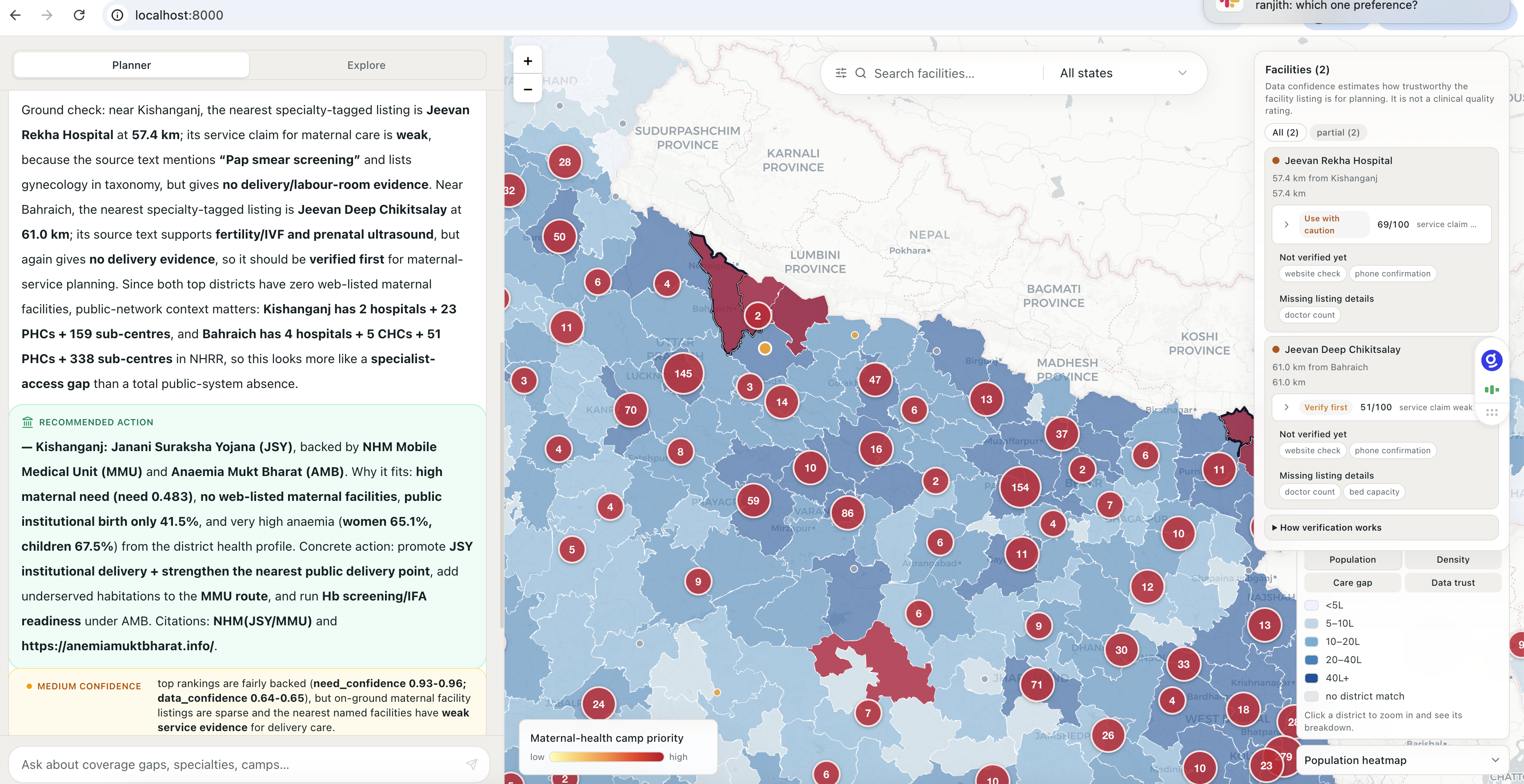
We offer two main mdoes: Planner -> natural-language questions across gap analysis, facility verification, and scheme targeting. An agent orchestrates 10+ governed tools, live-verifies facilities on a three levels (identity / service-claim / freshness), and recommends the government scheme that fits, with an expandable evidence chain. Explore -> Crafted datasets of facilities colored by trust tier, care-gap choropleths, a 227k government-network overlay proving which "deserts" are real, and a data-trust heatmap.
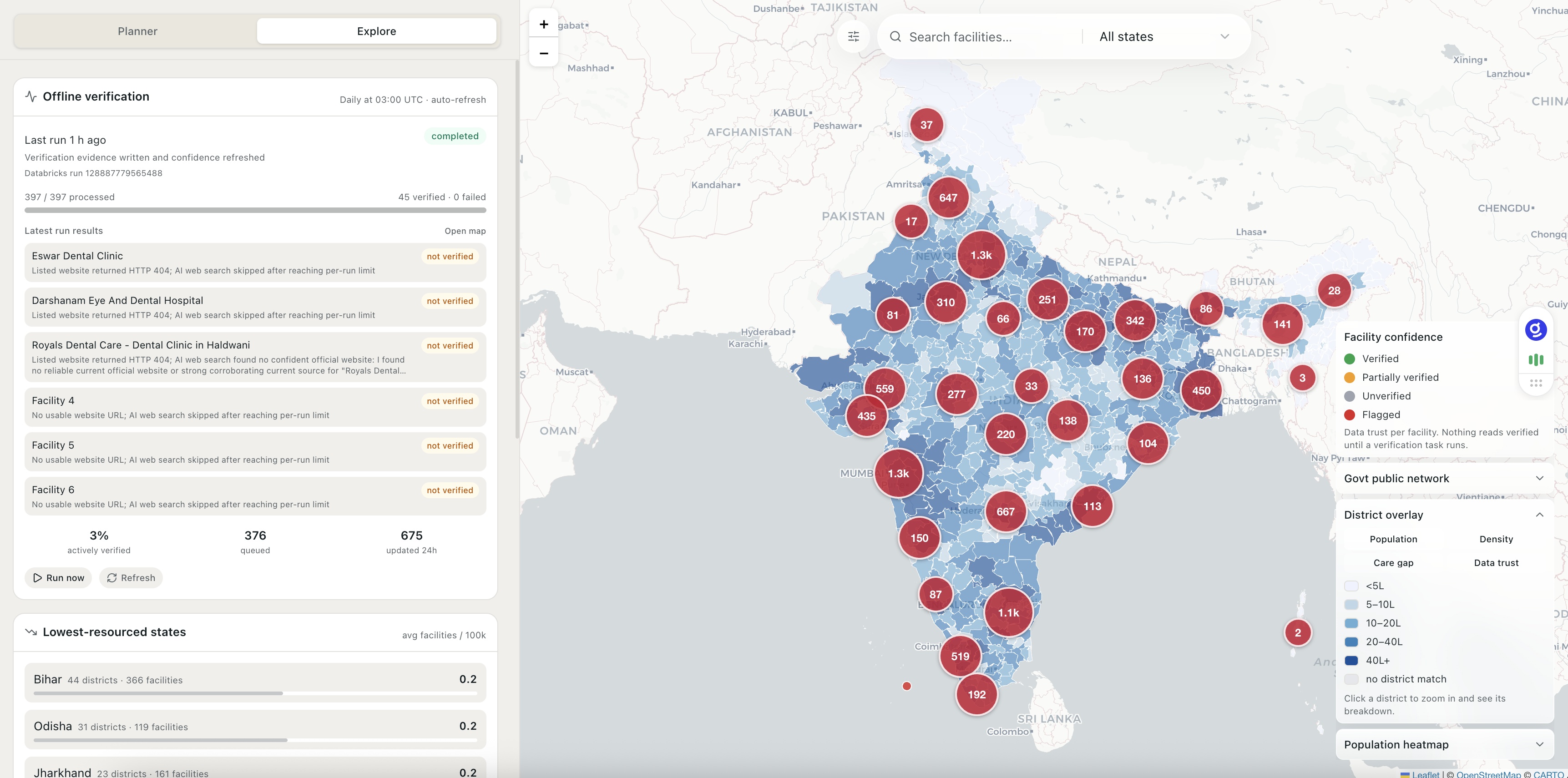
We emphasize confidence from the data, not the source. Every answer cites its tool, datasource, and live-check result. Live verifications (when old ones get stale) + scheduled offline Databricks job write to the same verification sink. The catalog gets more trustworthy with use(online) and overtime(offline).
How we built it
Data foundation. We started with the Virtue Foundation's 10,088 web-scraped facilities. It was incomplete. We pulled in 5 external datasets (WorldPop 2026 population, NFHS-5 district health indicators, geoBoundaries ADM2 polygons, Census 2011, and the 227k-facility NHRR/Esri government public network), then reconciled them on a single consistent district key using PostGIS point-in-polygon assignment. This helped us enrich the data: 183 of 185 apparent "deserts" were data artifacts, not real gaps. Every cleaning step is measured before/after (704/706 district names had trailing whitespace; 2,475 NFHS cells needed parsing; nearest-centroid was attributing supply to the wrong district).
More breakdown of each data foundation step is our Github readme: https://github.com/ranjithkumar-glean/databricks-hack#medicare-lens
Scoring model: We built a transparent, explainable care-gap formula (need × scarcity × reach) with empirical-Bayes shrinkage for thin surveys, log-compressed reach so large districts don't dominate linearly, and rank uncertainty separated from the score itself (stable / uncertain / estimated). All 735 districts scored, including 183 imputed from nearest-surveyed districts (flagged openly as estimates).
Trust layer: Per-facility confidence is a three-component score (completeness 40% + validity 20% + verification 40%), materialized in Lakebase. Verification writes come from two producers — the live Planner agent (OpenStreetMap checks) and a scheduled offline Databricks Job (batch website-liveness + NHRR corroboration + ai_query adjudication) — into the same facility_verification sink. The verification ladder separates identity, service-claim, and freshness into independent, traceable rungs with a composite planning-readiness label.
Agent architecture: 10+ MCP tools - governed Unity Catalog table functions (gap ranking, specialty shortages, camp targets, nearest facilities, service-claim evidence, public supply, health profile, scheme levers, verification profile, low-confidence worklist) exposed as mcp tools via Databricks managed MCP. The agent calls these — it never writes SQL or invents data. A scheme-aware action layer maps each gap to a real government program (MMU, eSanjeevani, Anaemia Mukt Bharat, Mission Indradhanush, PM-JAY) with official citations.
Stack: Databricks Apps (AppKit: React/TypeScript/Tailwind + Express), Lakebase Postgres with PostGIS, Unity Catalog + managed MCP, Databricks Model Serving (GPT, OpenAI-compatible), AI Functions (ai_classify/ai_query) for in-warehouse LLM data prep, Spark jobs for offline scheduled verifications workflows and OpenStreetMap for free live verification.
Challenges we ran into
The Virtue Foundation feed is web-scraped, so a lot of rows looked usable on a map but weren’t trustworthy for planning. Names and locations had artifacts, facilities over-claimed specialties, and doctor counts were almost entirely imputed. We couldn’t treat “listed” as “has capacity,” so we built a facility confidence model and made the Planner separate existence, service claims, and freshness. That meant capping how “verified” anything could look until we had real evidence from OSM, registry matches, or offline enrichment.
Furthermore, our 10k web-listed facilities skew private/urban, so 185 districts looked like deserts until we reconciled them with India’s 227k NHRR public network. 183 were data artifacts (govt sub-centres/PHCs with no web presence); only 2 were true deserts. That forced a split architecture: trust-weighted gap scoring stays on curated supply, while public-network context lives in a parallel layer so we misrepresent scarcity by dumping 184k sub-centres into one number.
What we learned
- Trust is a ladder, not a number. Separate labels with separate evidence let the user decide.
- Databricks platform is super easy to use!
- The agent should never invent facts. Tools return governed data; the agent does reasoning.
- Data reconciliation > model sophistication. Joining two independent sources proved more impactful than any LLM prompt change.
- Surfacing uncertainty builds more trust than hiding it behind confidence.
- Significant potential in AI for social good and we are just at the surface of how deeply AI can influence humanity
Built With
- databricksaifunctions
- databricksmanagedmcpserver
- databricksmodelserving
- express.js
- lakebase
- particle
- python
- react
- sql
- typescript
- unitycatalog


Log in or sign up for Devpost to join the conversation.