-
Homepage
-
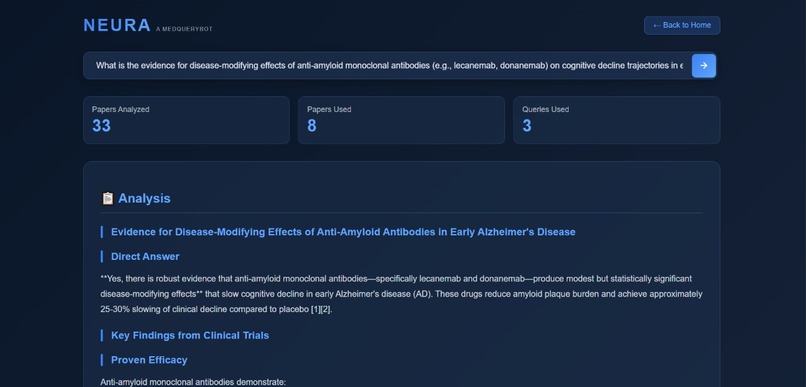
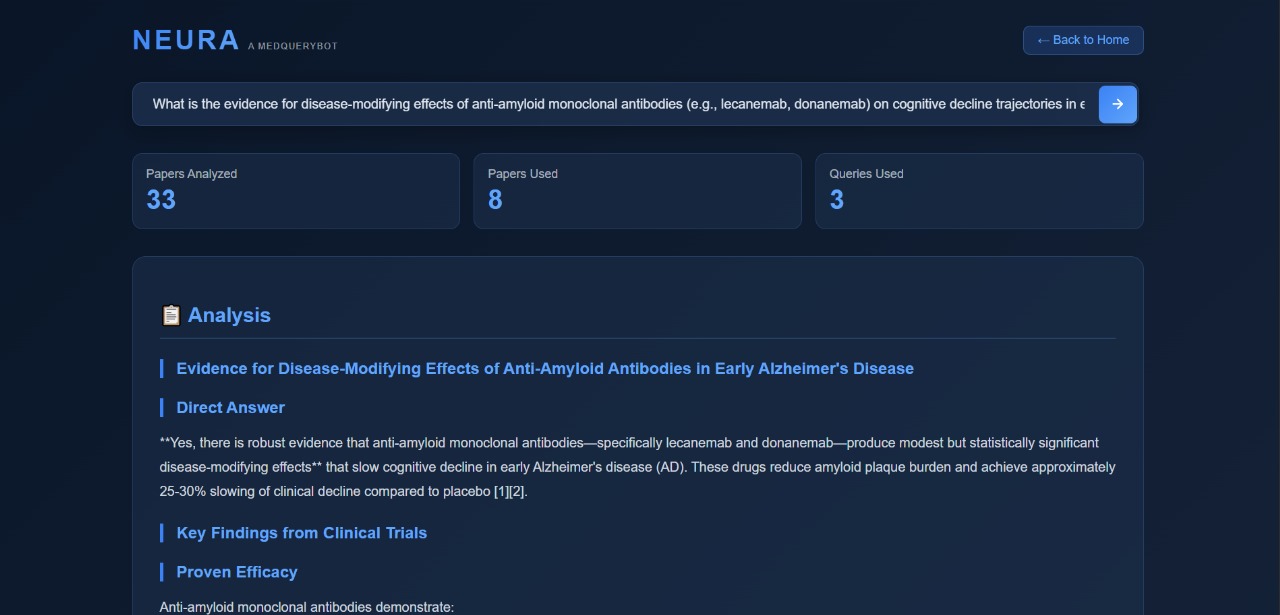
Retrieval stats
-
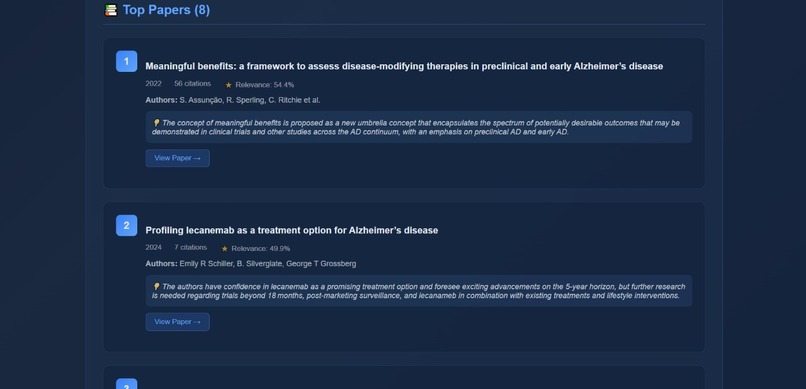
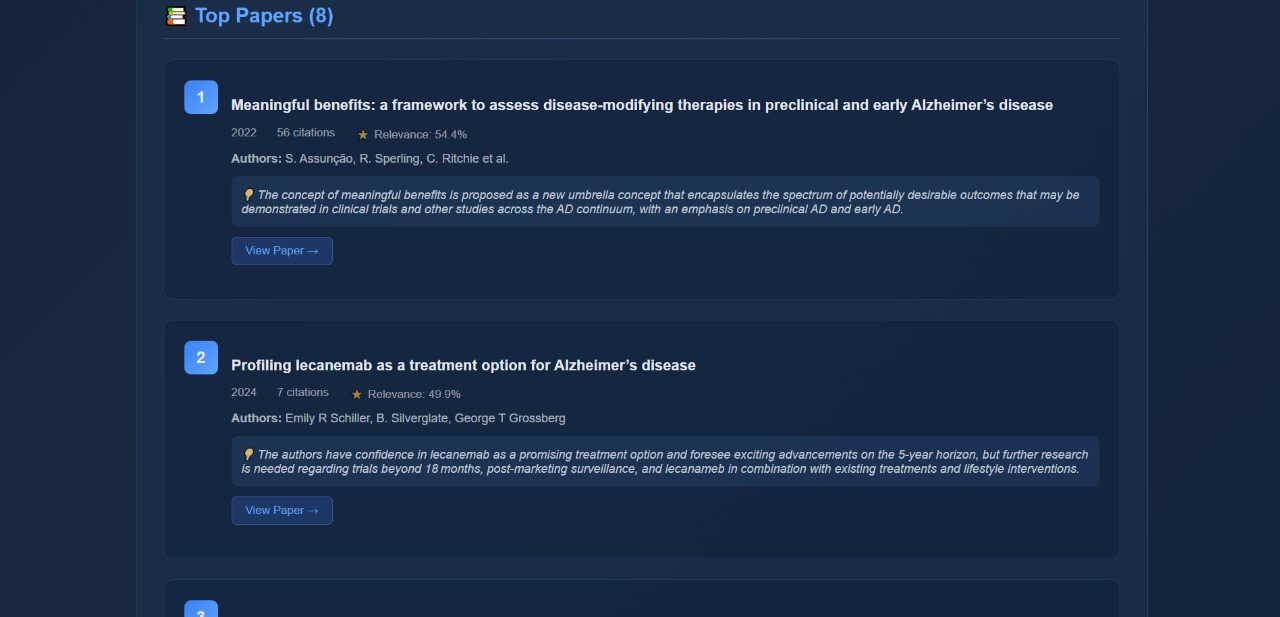
Recommended papers
Inspiration
We all come from scientific backgrounds and are greatly involved with academic literature on a regular basis. In turn, finding relevant literature about information we wanted would often prove difficult due to it being widely inaccessible to layman. This LLM would help find accessible articles with relevant articles with more ease and this would help other people like us as well as experts in thee field who could use technology in the field in order to expedite their research.
What it does
The LLM allows users to ask complex medical questions which would usually require copious amounts of collective research and synoptic linkage. It uses the Semantic Scholar API with a RAG pipeline to retrieve relevant, recent academic papers and will critique and highlight contradictory research. This is basically a fully functioning AI-assistant for medical students who are looking for thoroughly researched and well-concluded answers to their queries, no matter how broad.
How we built it
We started with querying the results fetched from the Semantic Scholar API. Query processing was our first step in being in a position to parse user questions. Once we did this, we were able to generate suitable search queries for a range of example questions. Using these queries we were then able to fetch any relevant papers using the Semantic Scholar API based on citation count, publication date, etc. With the API having such a large collection for the model to get data from meant we could not just leave the model to decide which paper was most relevant as this would not be consistent nor optimal. For this reason we decided to use vector embeddings and retrieval for semantic search. So instead of relating two pieces of text together lazily, which misses synonyms or other ways of saying phrases, would use vector embeddings to better relate the information together through a vector space e.g. diabetes as blood sugar disorder. Then we got into the use of sentence transformers which takes text as input and can be run through a neural network which would be our trained AI model to output a list of numbers thus creating a 384-dimensional vector to help understand meaning through learned patterns as opposed to human interpretation. This creates a strong link between the data we fetch and our generated queries. We then refined this by ensuring the model's answers were clearly synthesised and smart ranking was implemented. The main focus was to be able to fetch and process this data in a way the model could draw trustworthy and readable conclusions to otherwise convoluted and highly technical language and methods. ## Inspiration We all come from scientific backgrounds and are greatly involved with academic literature on a regular basis. In turn, finding relevant literature about information we wanted would often prove difficult due to it being widely inaccessible to layman. This LLM would help find accessible articles with relevant articles with more ease and this would help other people like us as well as experts in thee field who could use technology in the field in order to expedite their research.
Challenges we ran into
Initially we used Semantic Scholar SPECTER to generate embeddings of the scientific papers but had to switch to sentence transformers we kept getting 502 error returns due to limited free usage. This worked out better for us as sentence transformers proved to be a better option for local embedding of the model as we do not need API calls, making it more reliable. Another issue we experienced was the difference in responses if the same question was asked twice. We had some changes in the ordering and recommendations of papers provided due to the LLM’s non-determinism causing a randomness in responses. This could have also been caused by the Semantic Scholar API variability which would be affected by updated ranking algorithms and new papers indexed, etc.
Accomplishments that we're proud of
We implemented a caching system of most recent queries and results to prevent unnecessary processing of frequently or recently accessed data. This resulted in consistency within the model’s responses which already helps to assist with how it learns from given data. This reduces response time and minimises the load on data sources.
What we learned
We learned how to better test and train a LLM using various methods such as vector embeddings, caching systems and sentence transformers. All of which we haven’t had any experience with implementing into a model before. As well as this we were able to refine and organise very complex papers and data into much more manageable, coherent conclusions and analysis.
What next for MedicalQueryBot
To scale this further we would add functionality for other heavily research based areas, maybe Quantum Mechanics and then bridging into Quantum Computing as Quantum error correcting is become a larger area of research. Also we would keep training this model so that instead of just detailed questions we can start refining information but we would need a lot more time to actually do this as the query search will vary heavily and will affect everything the model does in terms of the embeddings and evaluation.
Built With
- claude
- javascript
- python
- semantic-scholar



Log in or sign up for Devpost to join the conversation.