-
-

Sample Note
-
User Interface
-

Final PDF

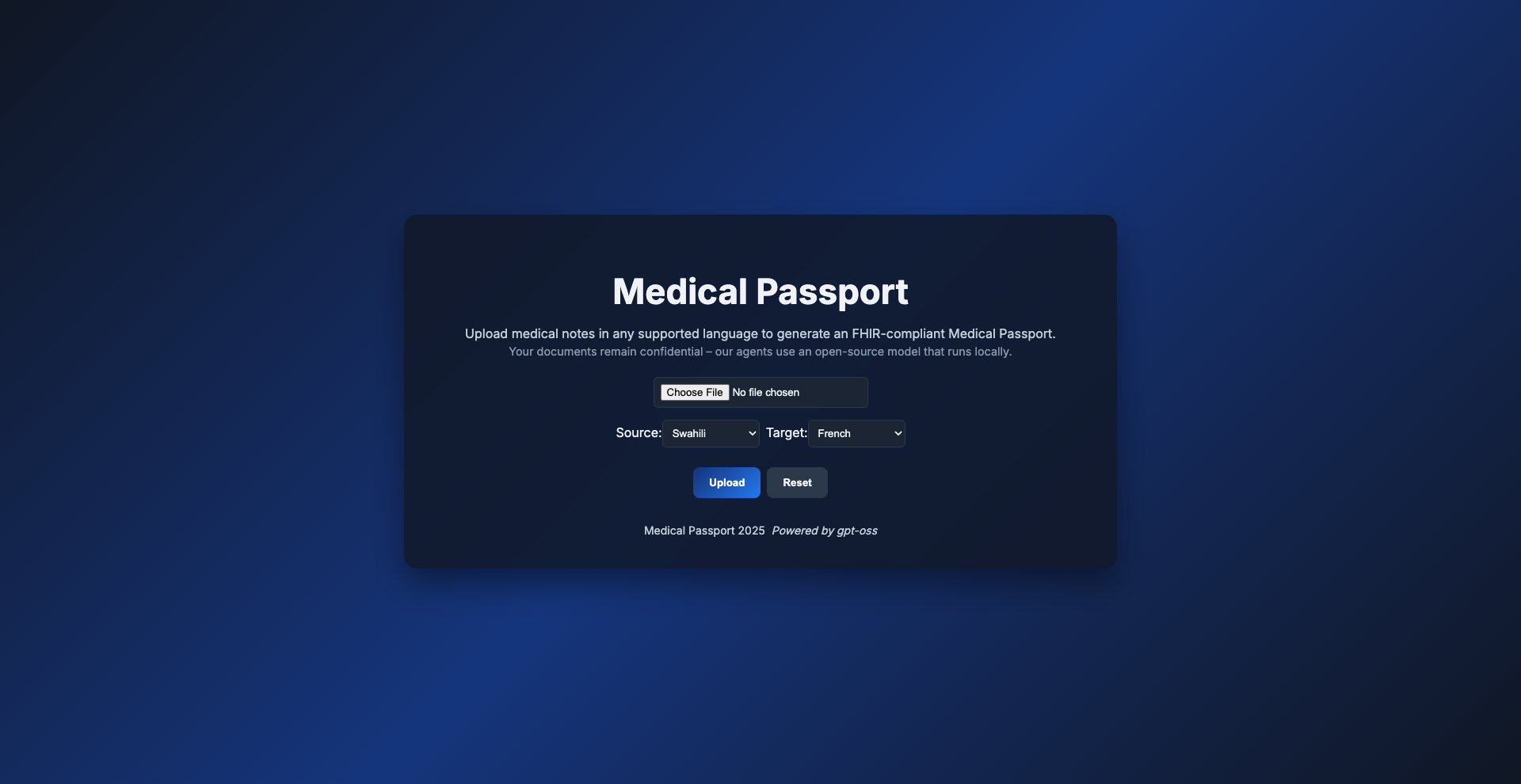

Medical Passport
This project implements a fully functional medical passport system with OpenAI's OSS models, Model Context Protocol (MCP), and Google's Agent-to-Agent Protocol (A2A). The system takes handwritten or scanned patient notes, digitizes them with OCR, translates them across languages, maps them into structured FHIR/HL7 resources, summarizes key clinical risks, and generates bilingual referral packets - end-to-end, offline-capable, and ready for field use.
This addresses a pressing issue faced by organizations like Médecins Sans Frontières: patients often have fragmented, paper-based, multilingual records that disrupt continuity of care, especially when crossing borders or moving between clinics. By combining specialized autonomous agents with shared tools and open protocols - and by relying on gpt-oss running locally via Ollama - the system demonstrates how agentic AI can make patient information more reliable, portable, and accessible where it is needed most.
In practice, this could mean a patient arriving with only a messy handwritten note having their medical information recorded into a structured, bilingual format that follows them across clinics. These records could be stored online in a standardized system, making it easier for different organizations and providers – even across borders – to access up-to-date patient information and coordinate care.
Overview
- Open Source LLM: Agents use gpt-oss locally via Ollama for offline functionality and patient privacy.
- Agentic architecture: Multi-agent pipeline (Intake -> Translation -> Structuring -> Summarizer -> Referral) coordinated over Google A2A; shared tools via MCP server.
- Licensed FHIR coding: ETL pipeline maps to SNOMED CT, LOINC, and RxNorm coding with online fallback.
- 20+ languages supported: OCR (Tesseract with language packs), translation, script-aware PDF shaping.
- Web frontend (Next.js): File upload, language selection, live progress across agents, inline PDF preview and download.
- Bilingual, clinician-ready output: Clear summary, key risks, and structured data section with visible codes.
Multi-agent architecture
Emergency coordination and skill discovery via Google A2A:
- Intake Agent - OCR + language detection (Tesseract + langdetect)
- Translation Agent - bidirectional translation
- Structuring Agent - narrative -> FHIR structuring(SNOMED CT, LOINC, and RxNorm)
- Summarizer Agent - clinician summary + risk bullets
- Referral Agent - bilingual PDF/TXT packaging with script-aware fonts via Google's Noto project
An Orchestrator Agent bootstraps coordination, enabling agents to discover each other’s capabilities and pass structured outputs downstream. All agents share MCP tools and inherit from a common Base Agent, making the system modular and easily scalable.
Why gpt-oss?
Running gpt-oss keeps all processing local - ensuring security of sensitive medical documents while enabling offline use in crisis or low-resource settings.
What is FHIR?
FHIR (Fast Healthcare Interoperability Resources) is the global standard for structuring healthcare data. By encoding notes into FHIR Bundles, this project makes patient records interoperable and portable across clinics and borders.
Tech Stack
Frontend: Next.js (React), TypeScript, Tailwind CSS
- Calls the Orchestrator Agent over HTTP (A2A) and streams per-stage updates.
Agents (Python): Starlette/Uvicorn services implementing A2A; all call into shared MCP tools.
MCP tools (Python):
- OCR (Tesseract), language detection, GPT-OSS translation/summarization/structuring, PDF generation (ReportLab), terminology enrichment (SNOMED/LOINC/RxNorm).
LLM runtime: Ollama with gpt-oss model family (20B recommended).
Terminology sources:
- SNOMED via Snowstorm FHIR
- LOINC FHIR (with credentials)
- RxNorm (RxNav REST)
PDF: Script-aware shaping (Arabic, Farsi, Urdu, etc.) with Noto fonts.
Challenges
Getting autonomous agents to "behave" and coordinate over MCP + A2A, handling OCR across diverse scripts, and keeping LLM outputs reliably within FHIR schemas were all tough. Building secure offline ETL pipelines that ingest millions of terminology records while navigating their respective licensing barriers pushed me to deal with both scale and compliance together.
Reflections
This project showed me how much impact agentic AI can have when paired with global standards and open protocols. I learned that getting the “plumbing” right - from OCR and fonts to terminology enrichment - is as important as the model itself. Most importantly, I saw how technical design decisions can directly shape whether these systems have utility in the real-world conditions they’re intended for.
⚠️ When testing locally, please ensure to set OLLAMA_MODEL=gpt-oss:20b in your .env, (not gpt-oss-20b)
Built With
- apt
- arabic-reshaper
- docker
- fastapi
- git
- google-agent-to-agent-(a2a)
- google-noto-fonts
- gpt-oss-20b
- gpt-oss-20b-via-ollama
- homebrew
- httpx
- json
- langdetect
- loinc
- loinc-(fhir-api)
- model-context-protocol-(mcp)
- next.js
- node.js
- ollama
- python-3.10+
- python-bidi
- react
- reportlab
- reportlab-(pdf)
- requests
- rest
- rxnav-rest
- rxnorm
- snomed-ct
- snomed-ct-(snowstorm-fhir)
- snowstorm-fhir
- tailwind
- tesseract-ocr
- uvicorn

Log in or sign up for Devpost to join the conversation.