-
-
AI Agent for Elastic Hackathon: creates normalized patient cohorts from 4 sources using LLM, kNN search, and Elastic workflows.
Inspiration
We work with one of Israel's largest HMOs — an organization serving millions of patients across hundreds of facilities. Researchers there need to build patient cohorts for clinical studies: "find all diabetic patients over 60 who smoke." Simple question. Nightmarish execution.
Every facility stores data differently. Age is an integer in one hospital, a string range ("60-70") in a clinic network, and a Hebrew field name (גיל) in another. Dates come in 4 formats. Patient IDs are strings with leading zeros in one system and floats in another. OCR-scanned documents corrupt Hebrew clinical terms — סוכדת instead of סוכרת (diabetes). Some facilities track smoking status; others don't mention it at all.
Researchers spend weeks on manual chart review. Over 80% of clinical trials fail to meet enrollment deadlines — not because of medicine, but because finding the right patients across fragmented records is manual, error-prone, and slow.
When Elastic announced Agent Builder GA alongside this hackathon, we saw the opportunity to solve this problem properly: an agent that reasons about schema variance, paired with a deterministic workflow that normalizes data at scale.
What it does
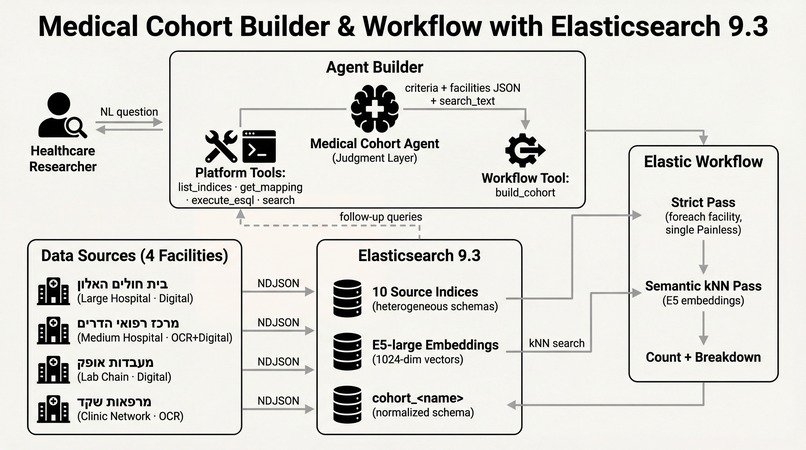
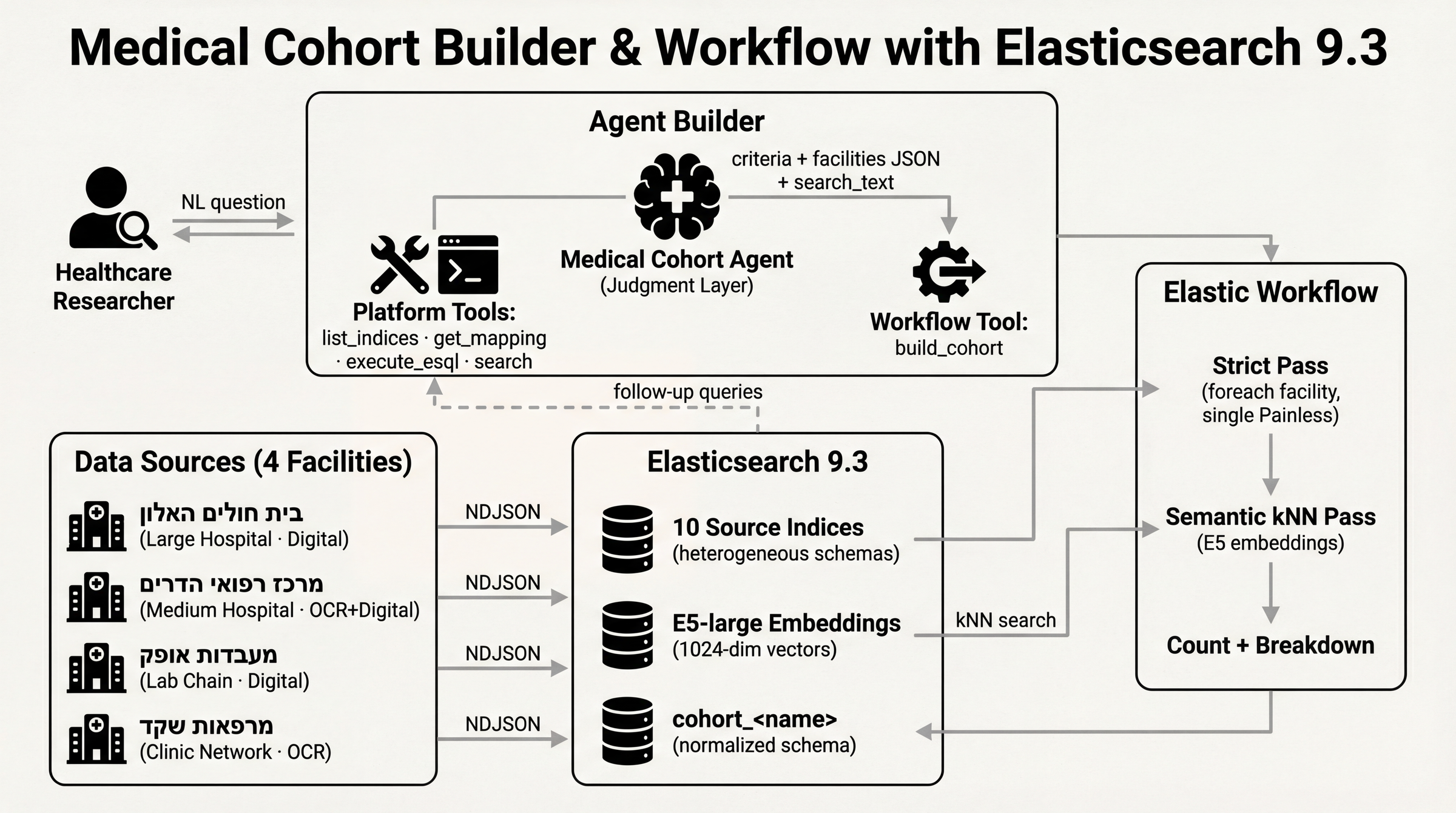
Medical Cohort Agent turns a natural language research question into a normalized, queryable patient cohort — a persistent Elasticsearch index, not a chat response.
A researcher types (in Hebrew or English):
"Find diabetic patients over 60 who smoke"
The agent:
- Discovers all facility schemas via
list_indices,get_index_mapping,search - Maps which field holds "age", "conditions", "smoking" at each facility
- Plans structured criteria from the natural language question
- Explains data availability caveats — "Facility B doesn't track smoking; matches from there will be semantic only"
- Triggers the
build_cohortworkflow with criteria + field maps as parameters
The workflow creates cohort_diabetes_smokers_over_60 with:
- Strict matches (36 patients): structured field match via parameterized Painless
- Probable matches (60 patients): semantic kNN match via E5-large embeddings — catches OCR artifacts, synonyms, negation
- Per-match provenance: source facility, field aliases used, evidence snippet, kNN score, match explanation
The researcher then asks follow-up questions — "Which departments were they treated in?" — and the agent queries the cohort index directly with ES|QL. No re-processing of raw data.
How we built it
Two-layer architecture — judgment separated from execution.
The agent (Layer 1) handles everything that requires reasoning: schema discovery, field mapping, criteria planning, data gap explanation, result interpretation. It uses Agent Builder's platform tools: list_indices, get_index_mapping, execute_esql, search.
The workflow (Layer 2) handles everything that must be deterministic: data normalization across facilities, kNN search, index creation. The build_cohort workflow is 6 steps in YAML:
- Delete existing cohort index (if re-running)
- Create cohort index with normalized mapping (including dense_vector for embeddings)
- Strict pass —
foreachover agent-provided facility configs. A single parameterized Painless script normalizes any facility's data usingparams.f_*(source field names) andparams.t_*(type hints). No facility-specific code. - Semantic kNN pass —
foreachover facilities. E5-large embeddings find patients whose clinical text is semantically similar to the research question. This catches what structured matching misses: OCR corruption, medical synonyms, negation. - Count strict + probable matches
- Return breakdown per facility and confidence level
The agent passes criteria and per-facility field maps as JSON. The workflow normalizes generically. Adding a new facility requires zero code changes — only the agent discovering and mapping its schema.
Data layer: 10 source indices across 4 synthetic facilities (generated by MedSynth), each with intentionally different schemas, field names, data types, date formats, and OCR artifacts.
Inference: E5-large via Ollama through Elasticsearch's inference API (e5_embedder endpoint). Used for both indexing (text_embedding field) and kNN search in the workflow.
Deployment: Air-gapped, single VM. Elasticsearch 9.3 + Kibana + Ollama (Llama 4 for agent LLM, E5-large for embeddings). Zero cloud dependency.
Challenges we ran into
Workflow Liquid templates don't support array operations. The strict pass normalizes conditions, medications, and icd10_codes — which are arrays in source documents. Liquid can't iterate arrays into new arrays, so we concatenate values with a delimiter in the Painless script and store them as concatenated strings in the strict pass. The normalized cohort schema documents this.
Agent schema discovery is non-trivial. Facilities use Hebrew field names (מחלות_רקע, שם_מטופל), English field names (conditions, patient_name), and abbreviations (tz for Teudat Zehut). The agent instructions include a DISCOVER phase with explicit guidance on mapping Hebrew medical terminology to normalized field names.
OCR artifacts break exact matching silently. סוכדת (OCR corruption of סוכרת / diabetes) looks like a valid Hebrew word to a keyword search — it just returns zero results. No error, no warning. The kNN semantic pass was specifically designed for this: E5 embeddings are robust to character-level noise.
Kibana internal APIs. The Workflow import endpoint (POST /api/workflows) requires an x-elastic-internal-origin: Kibana header that isn't documented. The Agent Builder API body structure (requiring both id and configuration.tools) took trial and error to get right. We documented all gotchas in the repo's troubleshooting section.
Accomplishments we're proud of
The two-layer pattern works. LLM for judgment, workflow for execution — this separation means the normalization is reproducible and auditable regardless of which LLM is used. The same workflow produces identical cohorts whether the agent runs on Llama 4, GPT-4o, or Claude.
Generic normalization via foreach. One Painless script handles all 4 facilities. The agent discovers schemas; the workflow normalizes generically. This isn't a demo trick — it's the architecture that would scale to hundreds of facilities.
MedSynth as a standalone tool. We couldn't share real patient data, so we built e2llm-medsynth — a synthetic medical record generator with realistic OCR artifacts per script (Hebrew ר↔ד, Arabic ب↔ت, Latin rn→m), schema variance across facilities, and 6 locale support. Published on PyPI, MIT licensed, useful beyond this hackathon.
Strict vs probable classification. Every match has an auditable confidence level and provenance. A researcher knows why a patient was included and can challenge probable matches — critical for clinical research integrity.
What we learned
Elastic Workflows are more powerful than they first appear. The foreach + parameterized steps pattern enables generic data processing that would otherwise require custom code. We initially planned to write a Python normalization script — the workflow replaced it entirely.
Agent Builder's platform tools are the right abstraction. Having list_indices, get_index_mapping, and search as built-in tools meant the agent could discover schemas without us writing custom tooling. The agent's judgment layer is pure instructions — no custom code.
Semantic search on Hebrew medical text works remarkably well. E5-large handles Hebrew clinical notes, OCR artifacts, and mixed Hebrew/English medical terminology without fine-tuning. The kNN pass consistently catches 15-20% of relevant records that structured matching misses in OCR-heavy facilities.
What's next
More facilities, more locales. MedSynth already supports 6 locales. The cohort agent architecture is locale-agnostic — the agent discovers schemas regardless of language. Arabic and Spanish healthcare systems have the same fragmentation problem.
Workflow chaining. A cohort index could trigger downstream workflows — automated eligibility pre-screening, longitudinal analysis, or cross-cohort comparison.
Evaluation framework. Systematic measurement of cohort quality: precision/recall of strict vs probable classification against known ground truth from MedSynth's generation metadata.
Built With
- agent-builder
- e5-embeddings
- elastic-workflows
- elasticsearch
- es|ql
- kibana
- ollama
- painless
- python



Log in or sign up for Devpost to join the conversation.