-
-
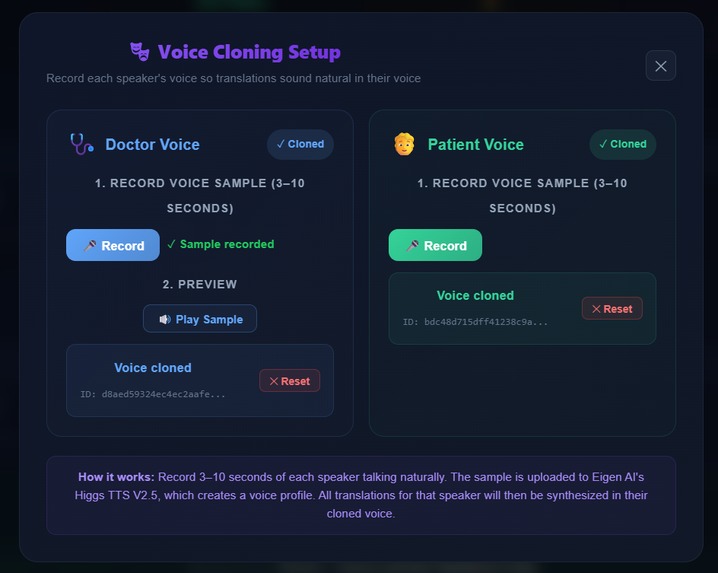
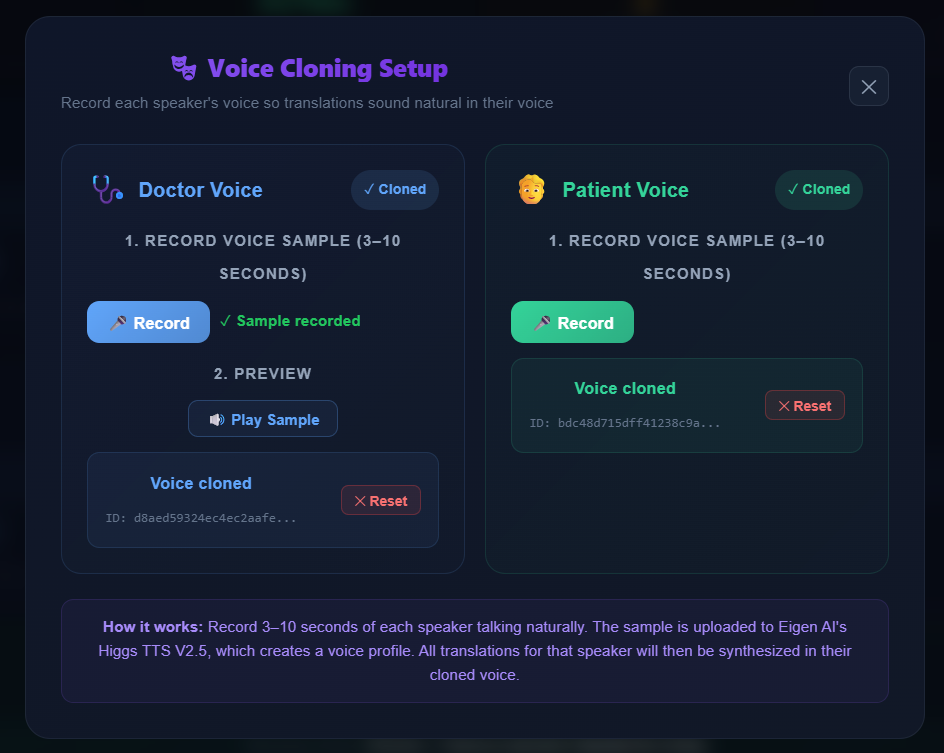
User-exposed voice cloning UI
-
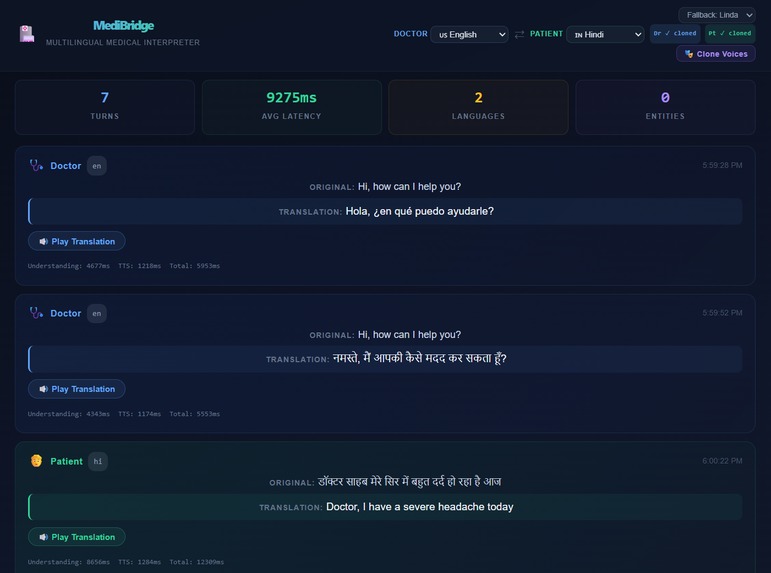
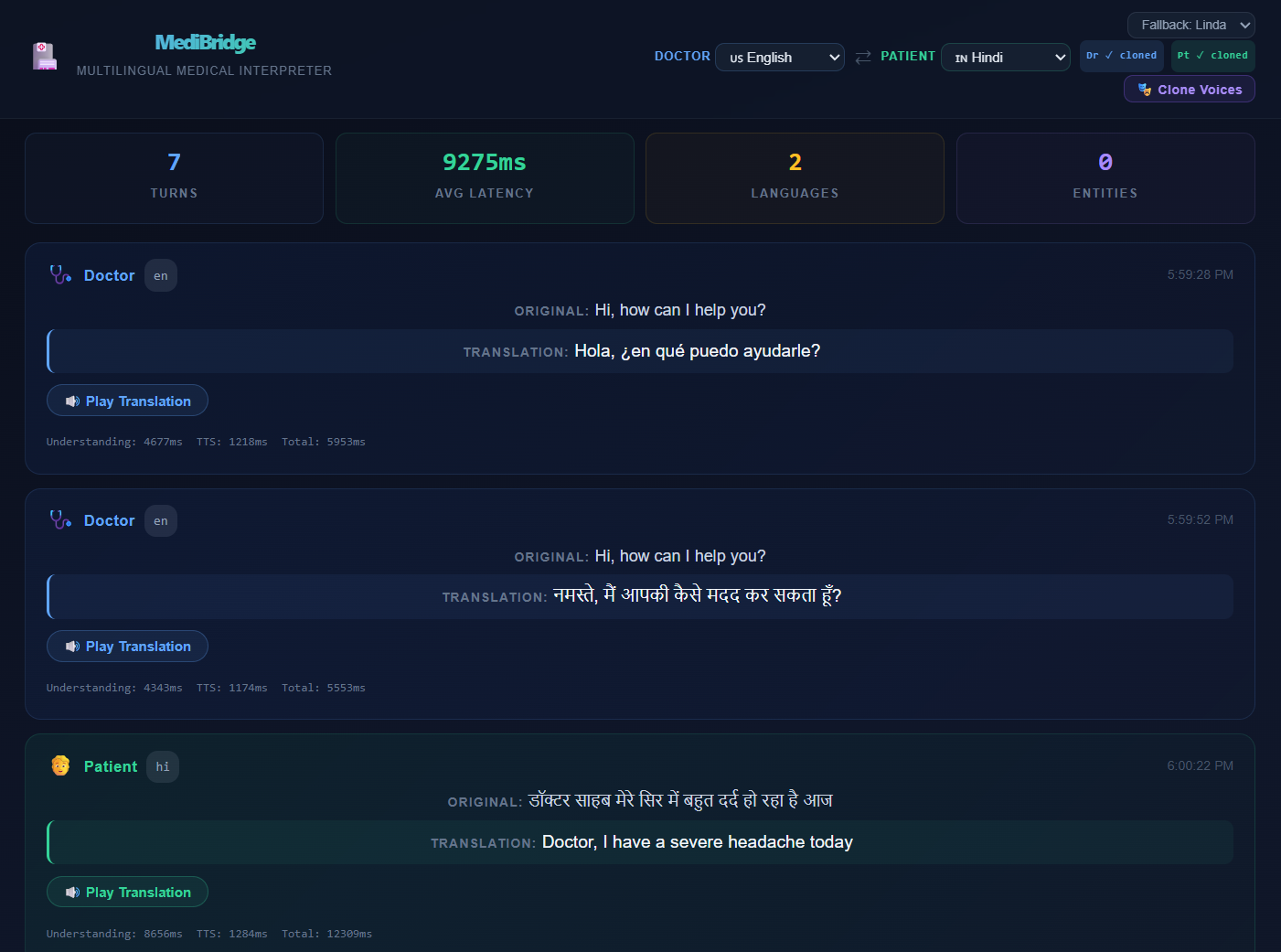
Example conversation between Doctor (English) and Patient (Hindi)
Inspiration
Language barriers in healthcare have measurable consequences. Studies show that patients with limited English proficiency experience 35% more adverse safety events than English-speaking patients, and medical interpreter services are unavailable or delayed in the majority of emergency encounters.
What it does
MediBridge is a real-time voice-to-voice medical interpreter that sits between a doctor and patient who speak different languages. In a single turn, it:
- Listens — records the speaker's audio from the browser microphone
- Transcribes — uses Higgs Audio Understanding V3.5 with automatic language detection across 12+ languages
- Reasons — activates Thinking Mode to disambiguate medical terminology before translating (e.g., distinguishing "discharge" as hospital release vs. wound drainage based on conversation context)
- Extracts — uses Tool Calling to pull structured medical entities: symptoms, medications, allergies, vital signs, diagnoses, procedures, and urgency level — displayed as a real-time clinical dashboard
- Translates — renders the spoken content into the other party's language with medical precision
- Speaks — synthesizes the translation using Higgs Audio TTS V2.5 with voice cloning, so the patient hears the doctor's translation in the doctor's own voice
The app includes a dedicated Voice Cloning Setup panel where each speaker records a 3–10 second voice sample. This sample is uploaded to Eigen AI, which returns a reusable voice profile.
How we built it
- Frontend: React (Vite)
- Backend: Python
- MediaRecorder: for audio capture
- Web Audio API: for resampling to 16kHz
- Manual WAV encoding/chunking to meet the Higgs API's 4-second chunk requirement
- Backend proxy: Express.js proxy server that routes browser requests to the Boson AI and Eigen AI APIs, bypassing CORS restrictions
Challenges we ran into
- CORS blocking: The Eigen AI API doesn't set CORS headers, so direct browser-to-API calls failed with "Failed to fetch.
- The browser's MediaRecorder outputs WebM/Opus, but the Higgs API expects 16kHz WAV in 4-second chunks. We had to build a full client-side pipeline: MediaRecorder → ArrayBuffer → AudioContext.decodeAudioData → OfflineAudioContext resampling to 16kHz → manual WAV header construction → base64 encoding → chunking with indexed MIME types.
- Tool call parsing variability: The Higgs V3.5 model returns tool calls in
<tool_call>XML tags, but the JSON structure inside varies — sometimes{"name": "...", "arguments": {...}}, sometimes {"function": {"name": "...", "arguments": {...}}}. - The Eigen AI voice upload endpoint expects a WAV or MP3 file, but we were sending a resampled 16kHz WAV blob. Getting the correct multipart form-data boundary, filename, and MIME type through the proxy required careful passthrough of raw request bodies
Accomplishments that we're proud of
- Every Higgs Audio feature exercised in a single API call. One turn through MediBridge hits ASR, language detection, Thinking Mode, Tool Calling, and translation.
- Real voice cloning UI: manage cloned voice profiles with a user-facing workflow
What we learned
- Audio preprocessing matters more than prompting. We spent more time getting the 16kHz WAV chunking pipeline right than writing the system prompt. The model is remarkably good at following complex instructions, but it can't recover from malformed audio input.
- Tool calling is not consistent
- Thinking Mode is worth the latency but won't work well in real-time conversations.
What's next for MediBridge
- Currently the user manually switches between doctor and patient. Adding automatic speaker identification from a shared microphone would make this hands-free.
- Clinical integration. The structured medical entity extraction (symptoms, meds, allergies, vitals) could feed directly into EHR systems
- Higgs Audio V2.5 at 1B parameters can run on an NVIDIA Jetson Orin Nano. Imagine embedding an Orin in every check-in kiosk in every clinic.
- We would like to build the benchmark for publishing WER, BLEU, and entity extraction F1 scores across language pairs
Built With
- express.js
- mediarecorder
- python
- react
- webaudio

Log in or sign up for Devpost to join the conversation.