-
-

Solution Architecture
-

Option 1: Plain text
-

Option 2: Plain text summarised
-
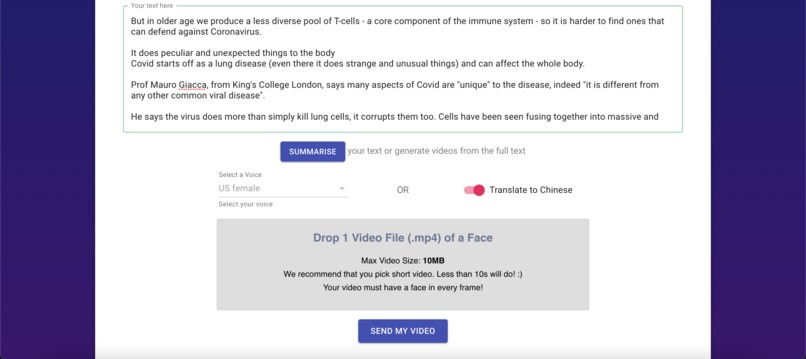
Option 3: Text translated to Chinese
-

Submit your video file, and you're ready to go!
-

Mediate - Media to Educate




Inspiration ✨
The COVID19 pandemic has limited the frequency of face-to-face interactions. The lack of physical lessons may make it harder for students to be engaged in learning. MediaTE aims to bring a "people element" to a digitised education, increasing engagement by turning mundane walls of text into exciting videos narrated by any person of your choice. We hope to MediaTE between the physical limitations of a pandemic and the advantages of online learning, thereby making an impact on both education and social interactions!
What it does 🔥
MediaTE (Media To Educate) addresses three problems:
- Reading walls of text can be boring. MediaTE will convert a plain wall of text into an entertaining video voiced by your favourite characters or idols.
- Large walls of text are hard to digest. MediaTE distills the essence of tedious paragraphs in an instant by generating concise content summaries.
- The Internet is largely written in English, presenting a language barrier to many people. MediaTE offers the option to create videos translated into another language, in this case, Chinese!
How we built it 🛠
We built the frontend using React and deployed the app on Vercel. The backend is written in Python, with the text-to-speech done by AWS Polly and video generation using a pre-trained machine learning model, Wav2Lip. To tie up the services involved, we are using AWS Lambda and Amazon API GateWay to support the automation of the file uploads to Amazon S3 and to run our model on Amazon SageMaker.
View our AWS Architecture here.
Handling of user data: After receiving and processing uploaded media, we immediately delete it from S3. Any media uploaded is not stored anywhere and is removed once the output video is generated and sent back to the user.
Tips on How to Use 💁♂️
- To get the most natural results, the media used should be cropped such that mainly the head is visible. This is so that the facial features can be more accurately recognised.
- Movement of the body should be minimised so that the head portion is more or less in the same position. This is to ensure that when the video is looped, the transition will be smoother and more seamless.
- As for the duration of the video, a short video of 5 to 10 seconds should suffice, and remember the file size limit of 10MB! If you are taking a selfie with your phone and it is too large, one way to fix this is to reduce the video quality to 720p or lower, or simply crop the video duration. We hope this helps!
Invalid Inputs:
- Rotated images or videos of faces: For example, the model does not seem to work on upside-down faces. It is unlikely to have been trained on such faces
- Media where the face is too small on the screen: The model might not been able to detect the face if it is not clear enough
- Videos not in .mp4 format: For video inputs, we restrict to only .mp4 videos as we have not tested our model extensively on other file types to allow them in production.
Challenges we ran into 🧗
Limited Time - As we only had 24 hours to work on our hack, we were only able to implement adequate functionality to tackle the problem. If not for the tight deadline, we would have been able to implement additional features into our hack such that it would be better equipped to address the issue. Along the way, we had to also scale down our expectations significantly, such as making do without an authentication system which would have allowed us to manage users more effectively.
Limited Budget - Due to the fact that we do not have a budget to work with, we were only able to support the creation of 1 video at any one time. In order to minimise the cost that we will incur, we are only able to turn the features on while we're developing. If you'd like to test the features out, please reach out to us at mediate.official@gmail.com to make arrangements with us.
Accomplishments that we're proud of 🏆
- We are proud that our hack can potentially brighten things up in the age of virtual classrooms and help to minimise zoom fatigue.
- We are also quite impressed by how versatile our solution can be. For instance, the translation feature that we have included makes our hack Boomer-friendly as well as seniors would be able to consume typical Western media (e.g. BBC news, etc.) in their preferred language.
- We are confident that the concept of our hack will not only attract students and educators, but also deliver value to seniors who may want to understand some text written in English. With Mediate, we are not simply Google Translate, but more as we actually generate a real human who can speak the text!
- We are also quite amazed at how we managed to stay alive for so long without coffee
What we learned 🎓
- Working in a team using Git and GitHub
- Our team members have never worked in groups before and we are mostly used to solo or pair projects at best
- We ran into many conflicts while trying to sync our changes together, but with a fair bit of googling and endurance, we managed to pick up a few important pointers to take note of when working with other developers
- To help with the syncing of our changes on GitHub, we also learnt to use VSCode Live Share to work together as well. This turned out to be surprisingly useful since we were unable to meet up in real life to work on the project together
- Amazon Web Services
- Only one of our team members was familiar with AWS so it took awhile for us to understand how the different cloud services would work together in a pipeline to ultimately deliver the output we wanted
- In summary, we learned about Lambda, S3, API GateWay, SageMaker and not to forget IAM policies!
- A big part of using cloud services is also security, and with that we had to learn how to keep our data stored secure and to grant least privilege access as much as we could
- APIs
- We gained familiarity with using a variety of natural language APIs while we were sourcing for a suitable candidate for our application, and also had some fun along the way!
- In addition, we had to work with a variety of AWS-related APIs to bring our solution together and we learnt about the risks of managing API keys securely.
Disclaimers 🙊
- Please only make 1 submission at a time. Only your latest request will be processed, provided there are no other requests currently in progress. This is because our operations cost real money and we have a limited budget. Additionally, this will allow more users the chance to get to use this application. That is also why there is a maximum file size of 10MB imposed.
- If you do not receive an email after submitting a request, it could likely be due to other users already using the application. Feel free to reach out to us at mediate.official@gmail.com if you have any issues.
- Note that the quality of the generated video may be reduced to speed up our processing and reduce consumption of our limited resources. We seek your understanding on these matters. Thank you!
What's next for MediaTE 🏃♂️
- Support for more languages; currently we have only implemented translation to Chinese due to time constraints, but it is certainly possible for us to extend our application to enable a greater variety of translations
- With the advancements in natural language processing and computer vision, we believe that the quality of output generated can only get better. Additionally, with sufficient financial backing, we would also be able to build an even more robust and scalable solution
- Improve the concurrency of our system; right now, our hack is only able to support the creation of 1 such video at any one time and only the latest requests will be processed, provided that there are no other users using it at that time.
Built With
- amazon-api-gateway
- amazon-polly
- amazon-web-services
- aws-lambda
- react
- sagemaker
- vercel





{kind=link}
Log in or sign up for Devpost to join the conversation.