-
-
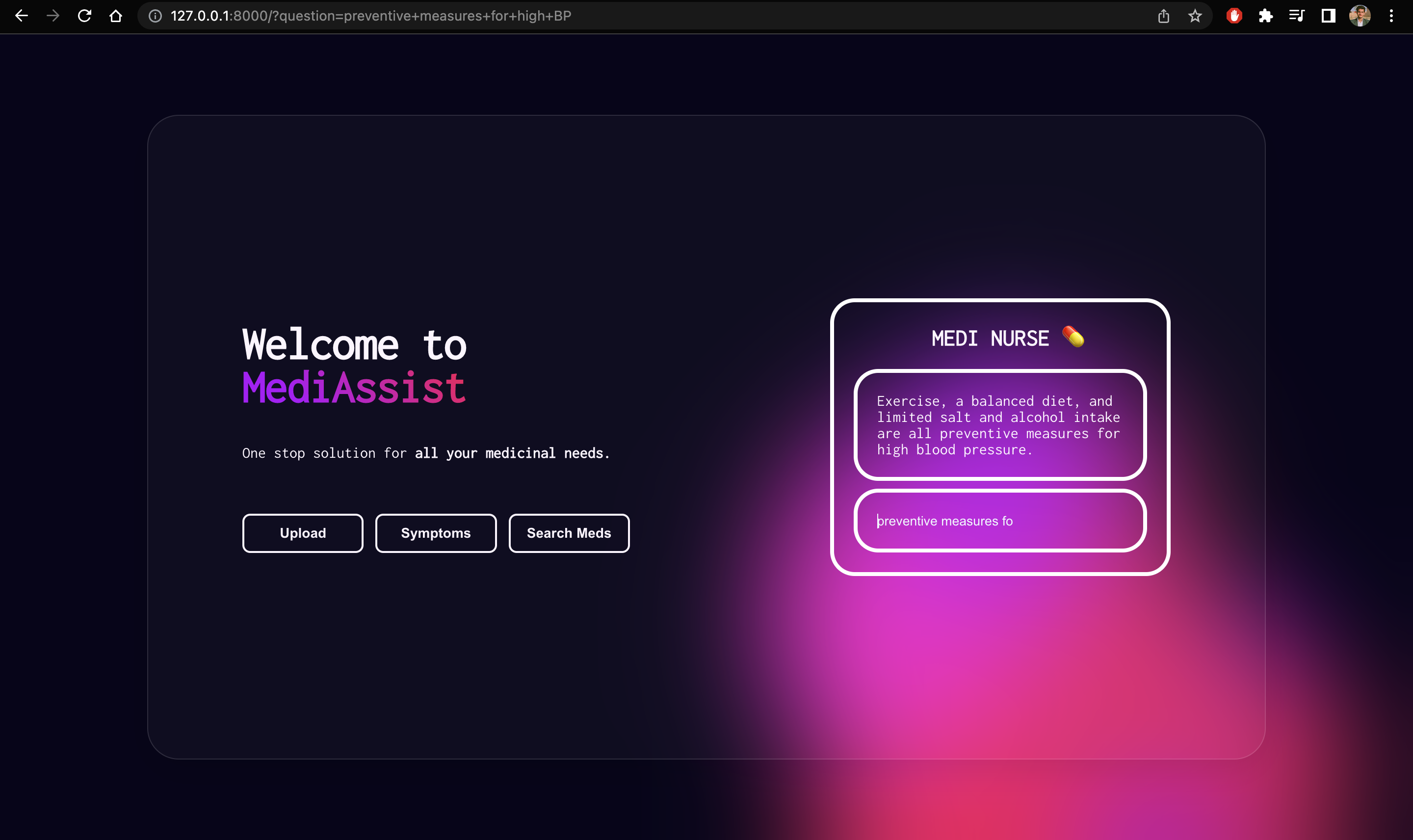
Home | Chatbot
-
Upload
-
Select Image
-
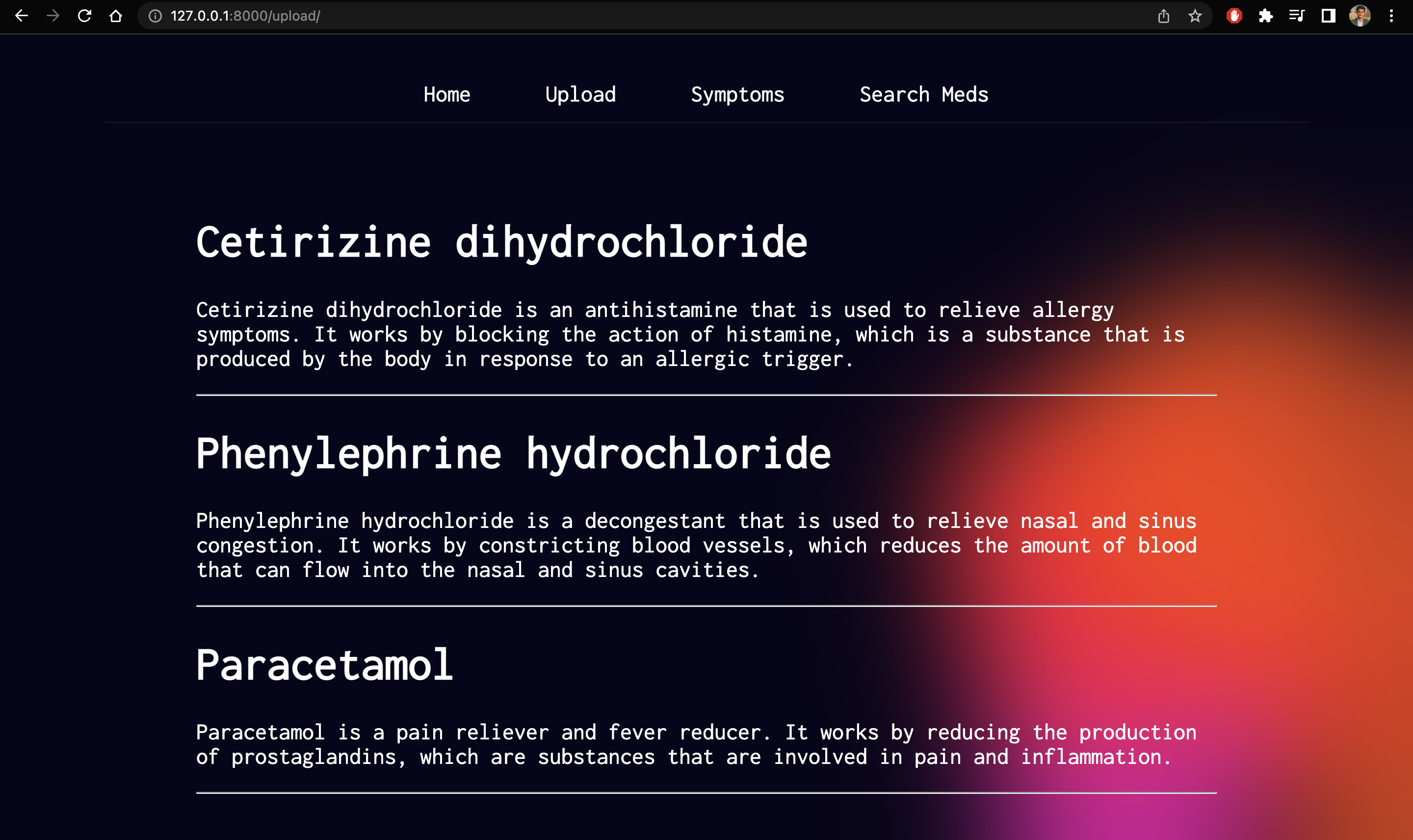
Parsed Active pharmaceutical ingredients
-
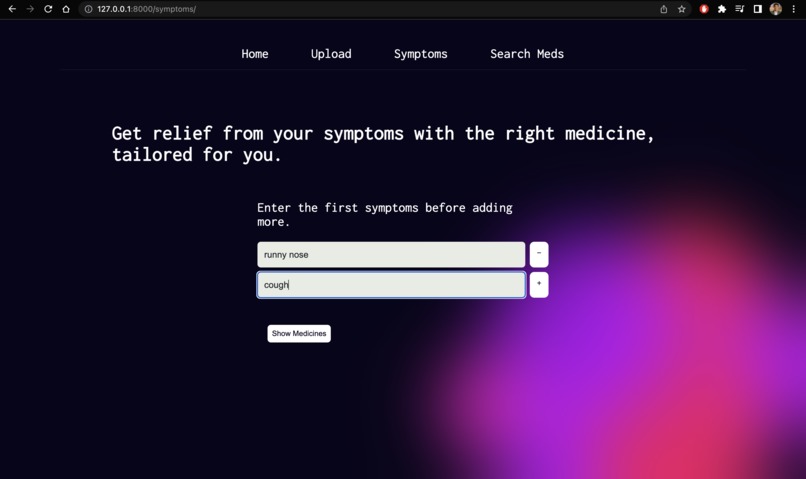
Symptoms
-
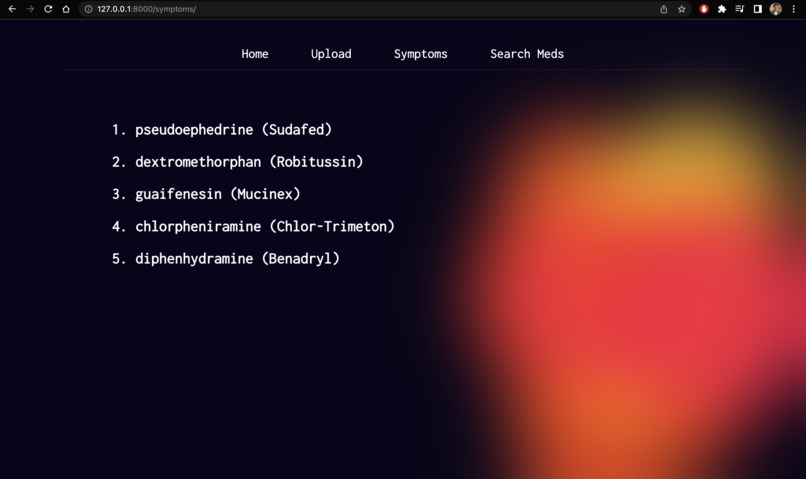
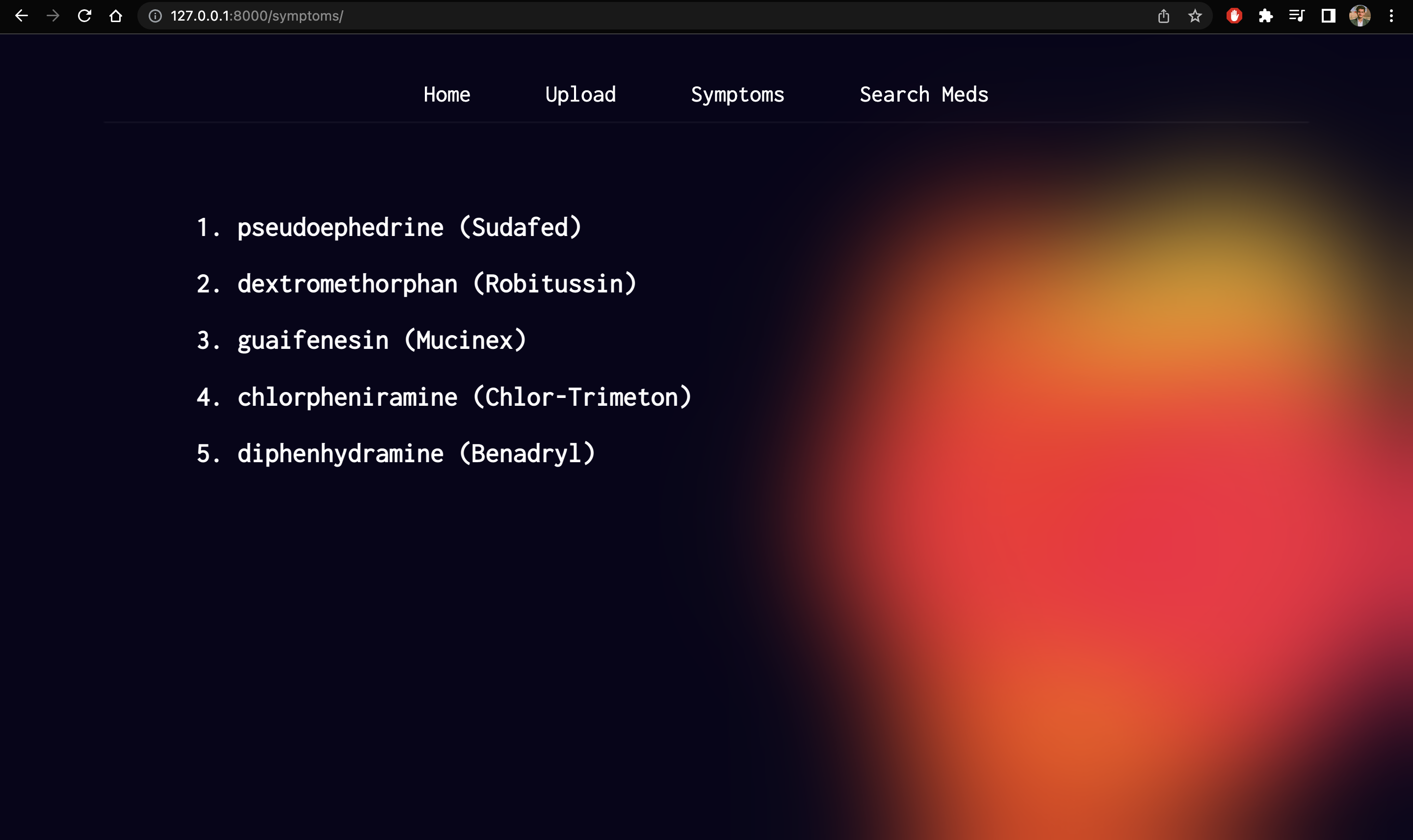
Medicines based on symptoms
-
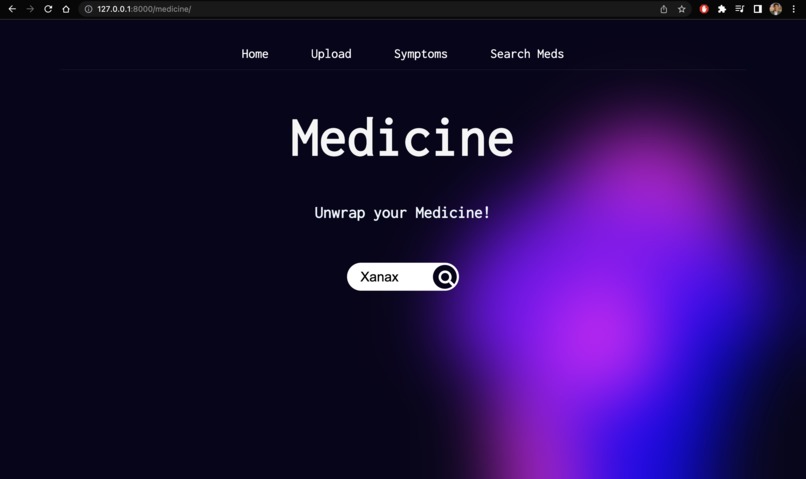
Search Medicines
-
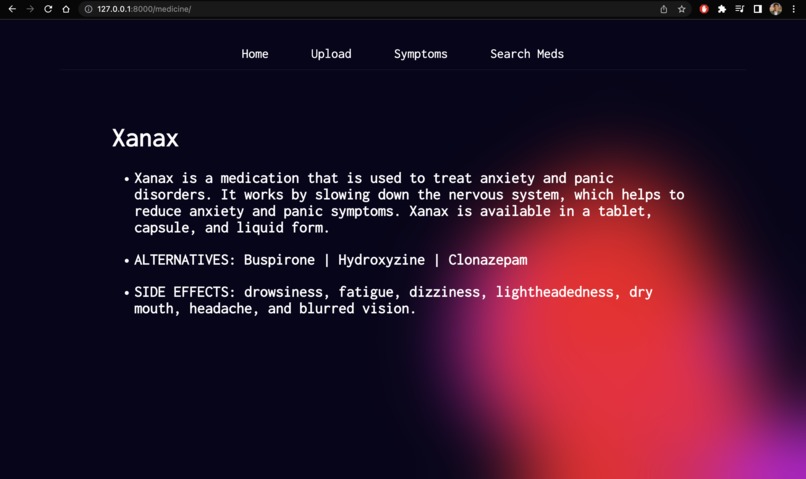
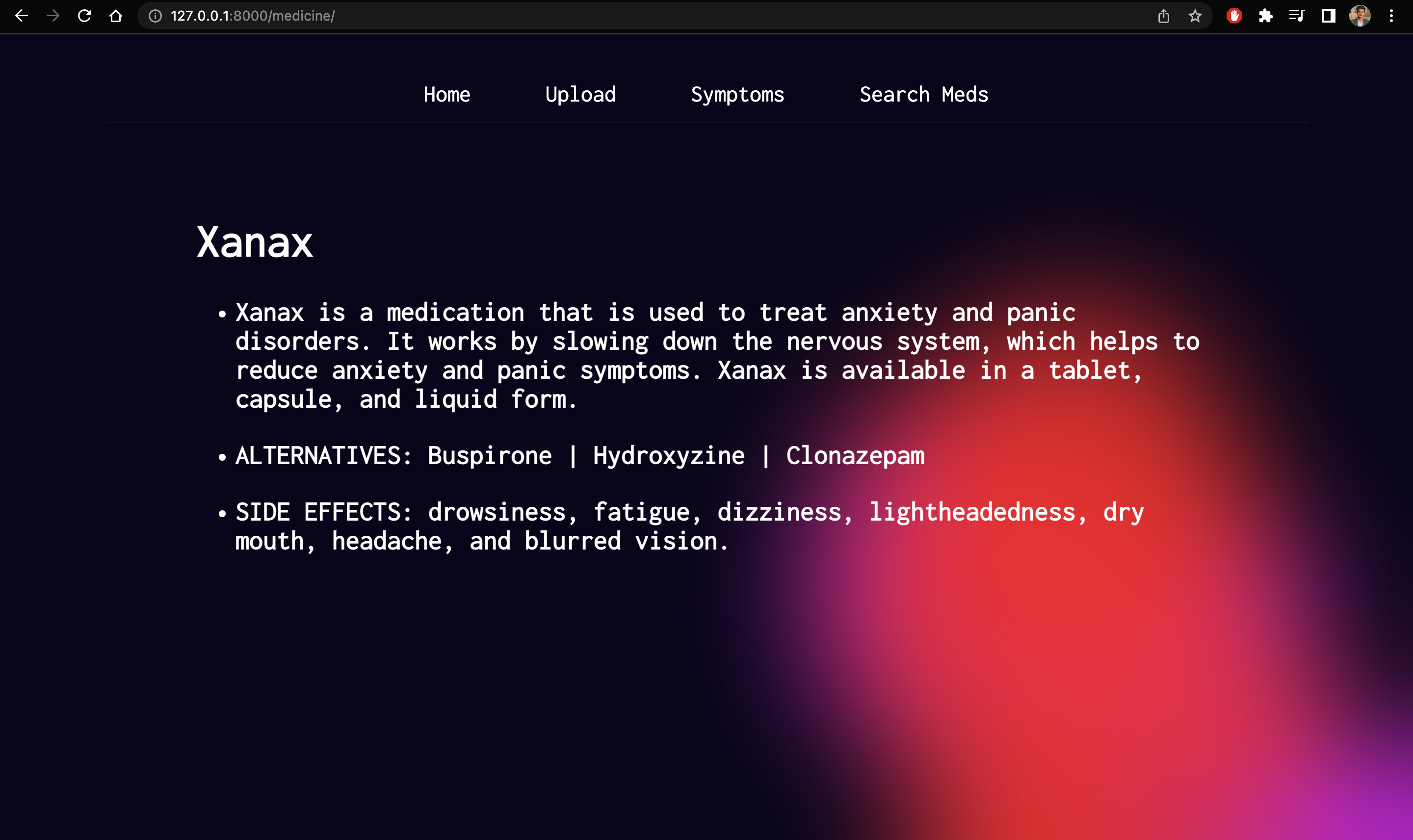
Info about Medicines
Inspiration
Since the names of medicines aren't very layman-friendly, it leads to a lot of confusion in keeping track of what each medication does and how it affects our bodies and health. This can have fatal consequences too if mistaken. Every year around 8-9 thousand people die accidentally taking the wrong medication. Many times, we face situations where we have medicines at home but we don't know what it does and what their side effects are and sometimes we also need alternatives to that. Thus we felt it was really important to develop a way to solve this problem and ensure we can provide easily accessible information about medication in a well-defined format to the users. And here comes our MediAssist.
What it does
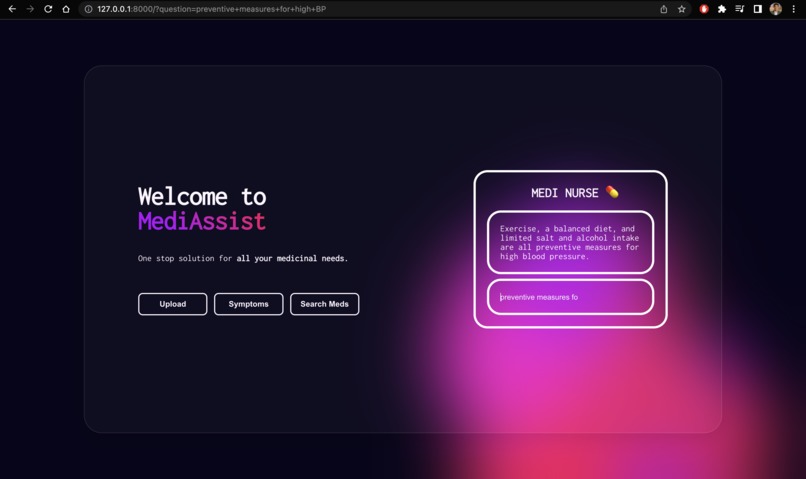
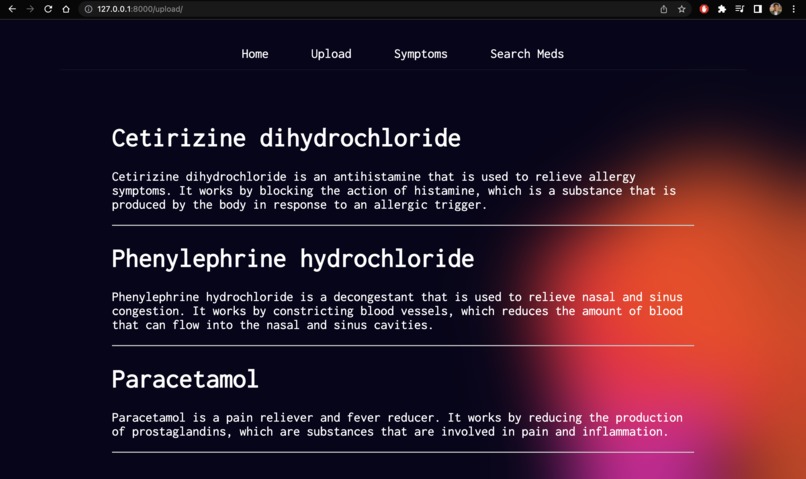
Upload: We’ve built an active pharmaceutical ingredient parser, all you’ve to do is take a photo of your medicine and then, it will parse each active pharmaceutical ingredient and give a brief description of them, so people are aware of what they’re consuming and they can have easy to understand information about their medicines.Symptoms: It allows users to enter their symptoms and allergies and provides medication based on that.Search Meds: Also, we have the option to look up information about medicines. Users can simply enter the name of any medicine and get easy-to-understand information, side effects, and alternatives of that particular medicine.ChatBot: Finally, we have integrated a chatbotMediNursewhich acts as your health assistant and answers all your queries regarding medicine and health.
How we built it
We built the frontend using HTML, CSS, and Javascript, we also used webGL for animations. In the backend, we used a python-based framework, Django. We leveraged Open AI's gpt-3, an LLM, and primed it iteratively to develop the various features of our application.
Challenges we ran into
- We figured out that gpt-3 works on the principle of garbage in - garbage out. That means, for yielding suitable/appropriate results, we had to find just one or two GOOD examples which are robust and versatile enough to train the gpt-3, instead of feeding tons and tons of data.
- The most difficult part was to implement the pipeline where we had to extract the text out of the medicine image label using Pytesseract and pass the text (which had lots of unnecessary data) to the trained gpt-3 model, in order to filter out only the required text(active pharmaceutical ingredients) and simultaneously write a description of each ingredient on the go. We also had to take care that this process doesn't end up taking more time than it would've been feasible.
- Also, integrating the gpt-3 model into our web app was a bit tricky, as the model worked fine separately but ran into errors and didn't fetch results when integrated into the web app.
Accomplishments that we're proud of
Proud to have completed a fully-fledged application in a relatively short duration of time.
What we learned
We learned how to collaborate effectively in a relatively short duration and deliver a full-fledged webapp. We also learned some CSS and animation tricks. Finally, we learned and quite a lot about GPT-3 and Large Language Models in general and also about Prompt Engineering.
What's next for MediAssist
We pretty much-completed everything we initially planned. We could've possibly added a feature if we had time, where users could add their prescriptions, and based on that they would get reminders to take their medicines.


Log in or sign up for Devpost to join the conversation.