-
-
Home Page
-
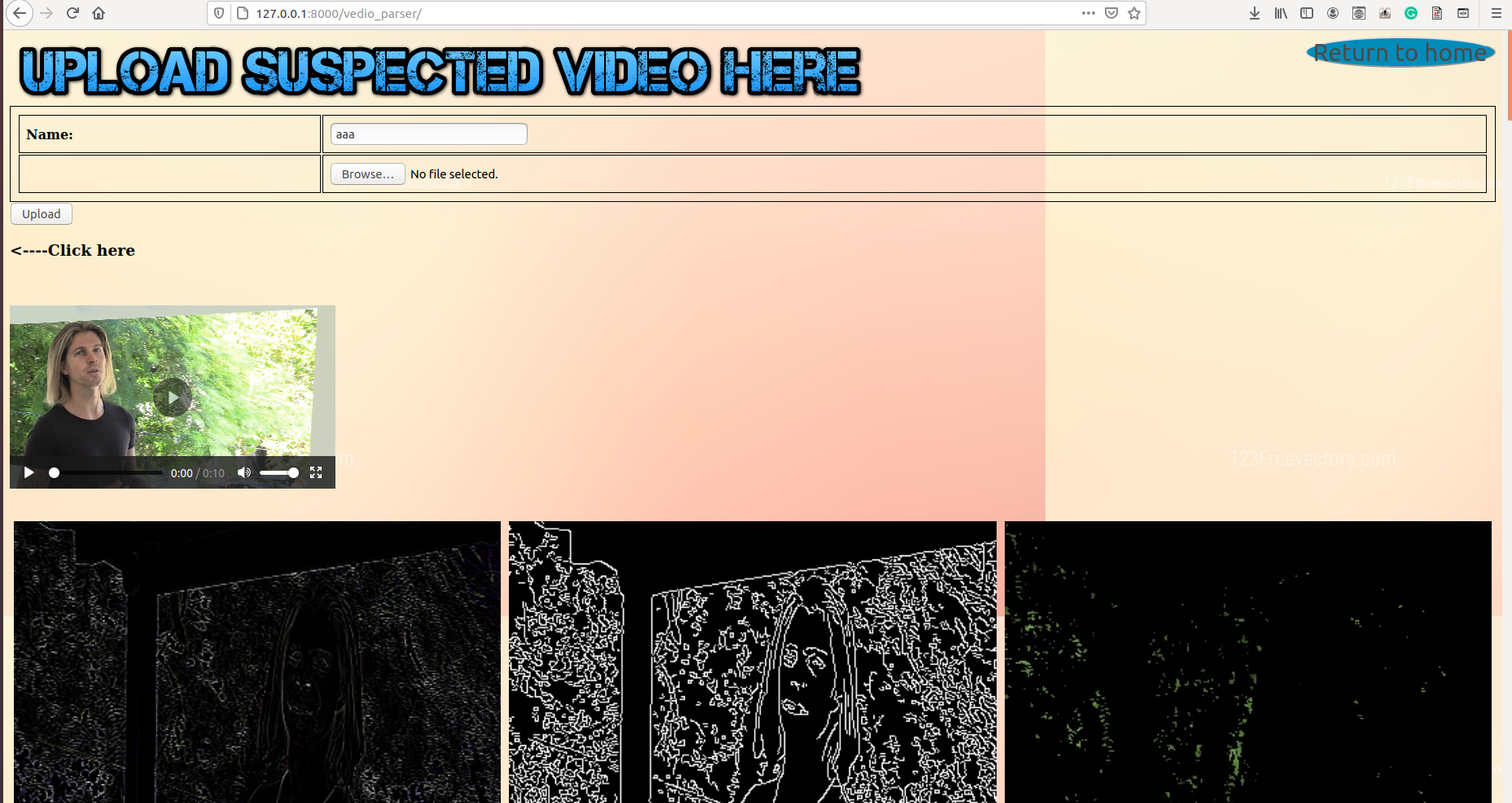
Vedio Analyzation_1
-
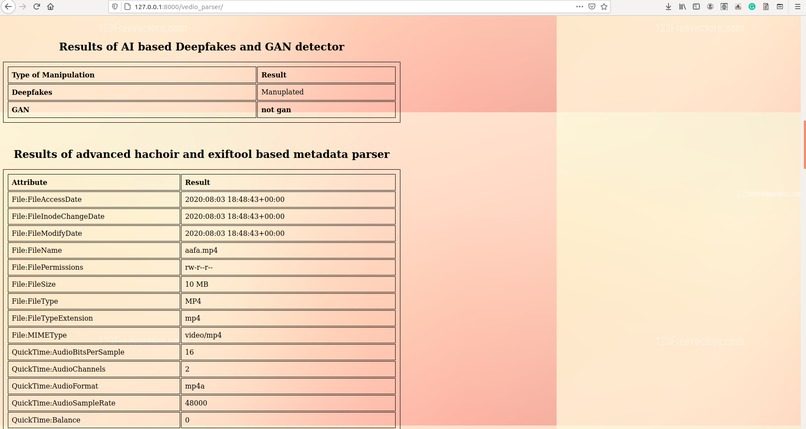
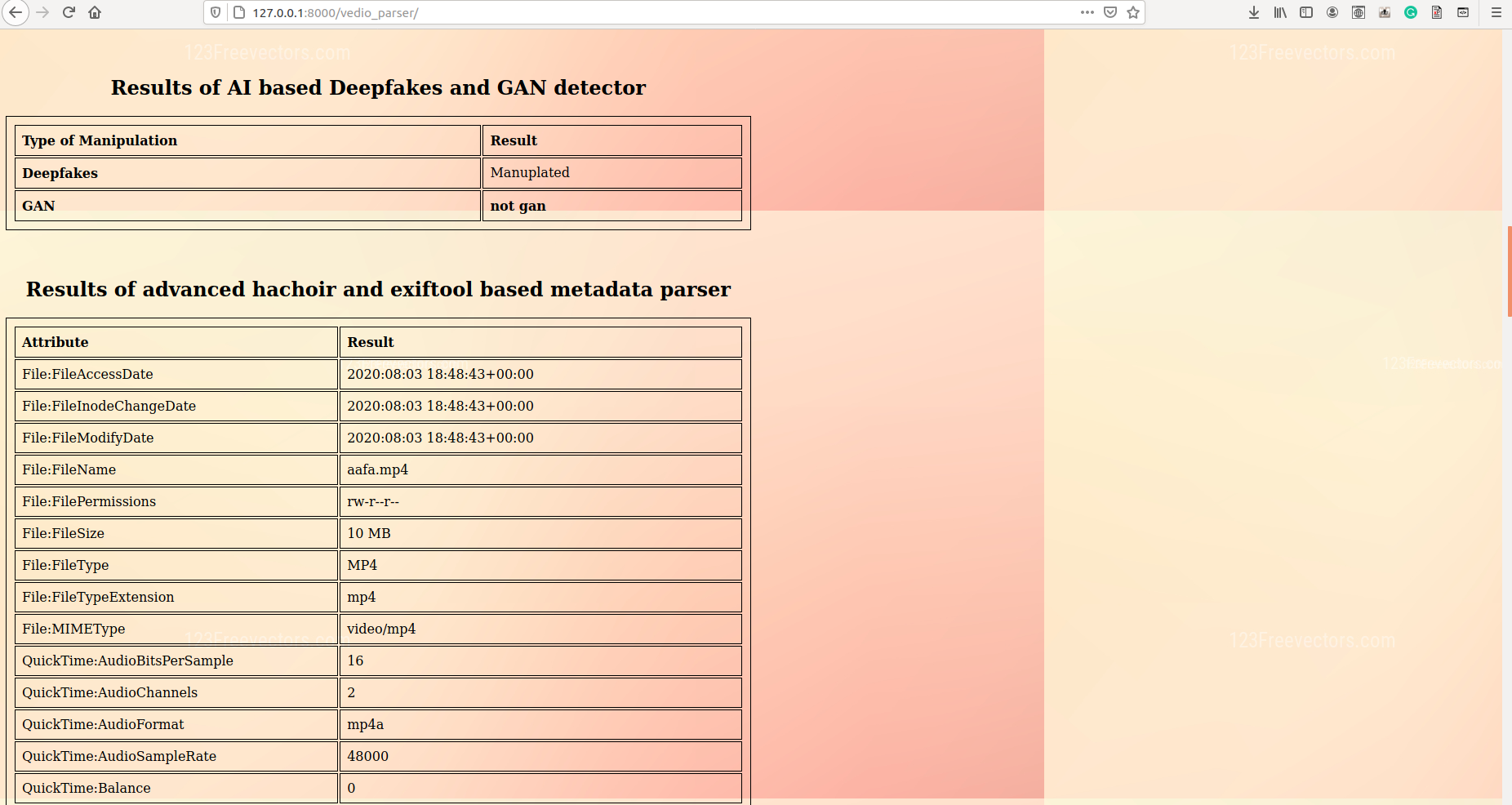
Vedio Analyzation_2
-
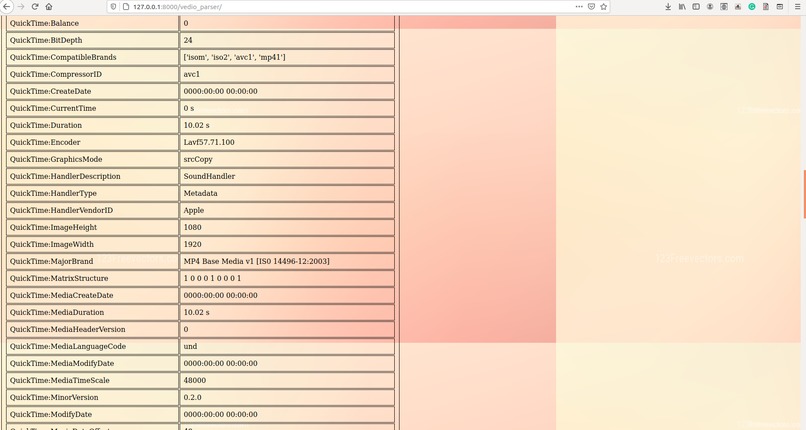
Vedio Analyzation_3
-

Image_Analyzation_1
-
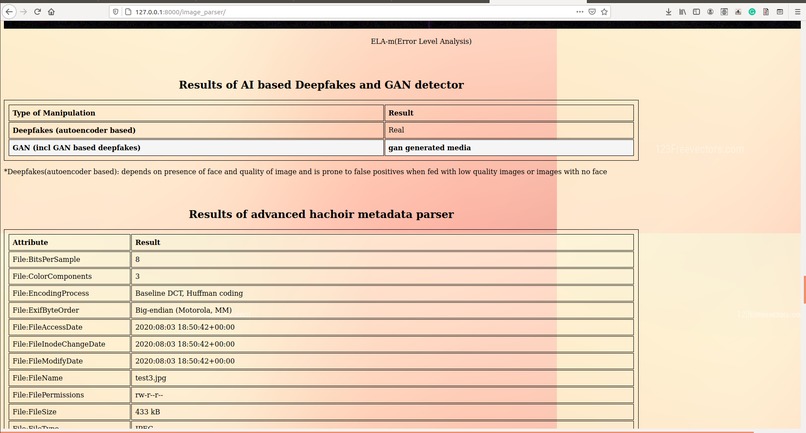
Image_Analyzation_2
-
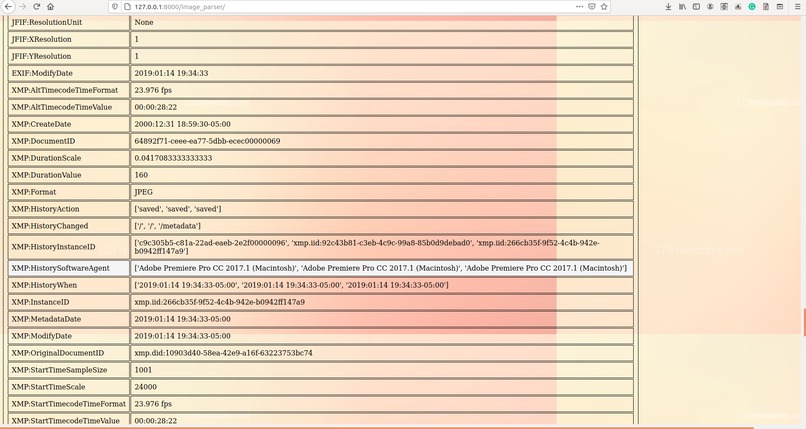
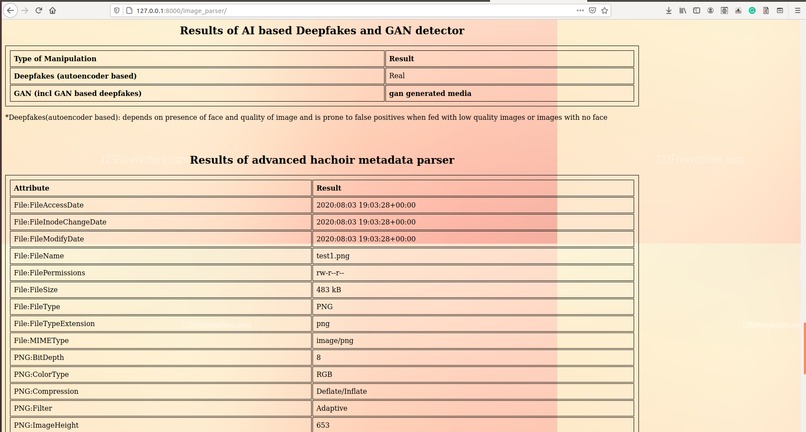
Image_Analyzation_3
-
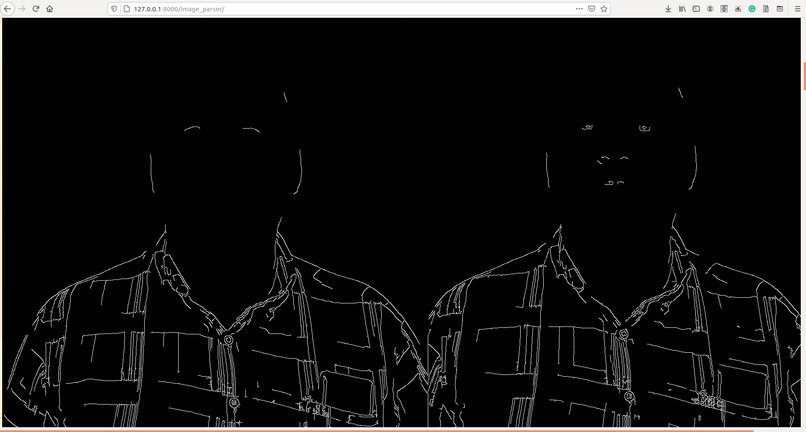
Image_Analyzation_4
-

Image_Analyzation_5
-
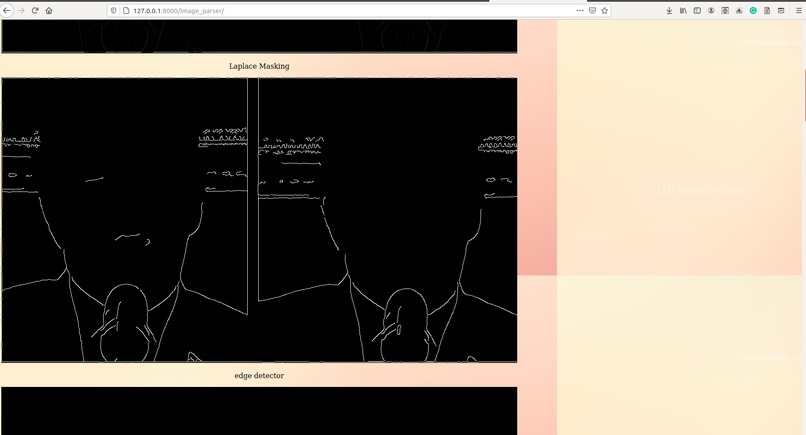
Image_Analyzation_6
-
Image_Analyzation_7
-

Image_Analyzation_8
-

Image_Analyzation_9




Media Forensics Toolkit
The unprecedented growth of technology in the past few decades has led to massive flooding of the market with media forgery tools like Photoshop, gimp, Deep Dream Generator etc. These tempered media sources have contributed to other major problems like fake news and even cyberbullying. Furthermore, advancements of deep learning lead to a more severe problem known as Deepfakes and Generative Adversarial Networks(GAN) generated images and videos, that are even harder to detect and investigate in case of a legal breach. This project aims to address this challenge by implementing two novel deep learning models that can be used conjointly with some static models to provide complete protection against almost all types of image and video forgeries including Deepfakes, GAN generated forged media, photoshopped media (splicing, copy and move forgeries). For Deepfakes detection, this project implements a Timedistributed CNN-LSTM neural network and for GAN generated media detection, this project uses a fine-tuned DenseNet model as the base Convolutional neural network. The statistical models include generation of images by masking original image through various algorithms like Error Level Analysis, Laplace transforms, variance masking, pixel density algorithm, and generation of Exifdata of media through various tools and packages like hachoir, ExifTool, etc. Compared with existing strategies, the evaluation results demonstrate that the novel strategy can serve as a one-stop tool for forensic investigators, thus providing holistic protection against threats of today(pixel based forgeries) as well as future(vector based forgeries).
Data Preparation
- The mean channel of images/frames was removed.
- All frames/images were normalized
- The fully-connected layer at the top of the network was removed ( for our DenseNet pretrained fine-tuned models)
- All frames and images were resized according to adjust with our pretrained models.
- Various data augmentation functions like adaptive Gaussian noise, emboss image, salt image, black hat filter, rotation, flipping, Affine Transformation, warping, increasing contrast were used to make the model more robust to changes.
- From the Keras preprocessing package, we used ImageDataGenerator to augment image input and use transformations as rescaling, shearing, zoom, flipping, height shift, width shift, fill mode, data format, brightness, and feature-wise normalize.
Implemented models {AI-powered}
1) Deepfakes
For Deepfakes, we used a Timedistributed CNN-LSTM neural network. TimeDistributed Layer keeps input to output relation proper, and avoid mixing of outputs. In this model, the function of CNN is feature extraction, and LSTM for sequence processing. In CNN, we used the initializer as glorot uniform, and reg lambda parameter to be 0.001. Various convolutional layers of variable kernel filters(32,64,128,256,512) are used to extract different features of frame/images. Different strides were used in pooling to gain access to different aspects of the image.The 2048-dimensional feature vectors after the last pooling layers are then used as the sequential LSTM input. We used stacked LSTM to increase sequence processing at different intervals ( units = 512, 256). Stacked LSTM gives robustness and increases the accuracy of our model as almost all correlations between features extracted by CNN are analyzed by it.
2) GAN generated media
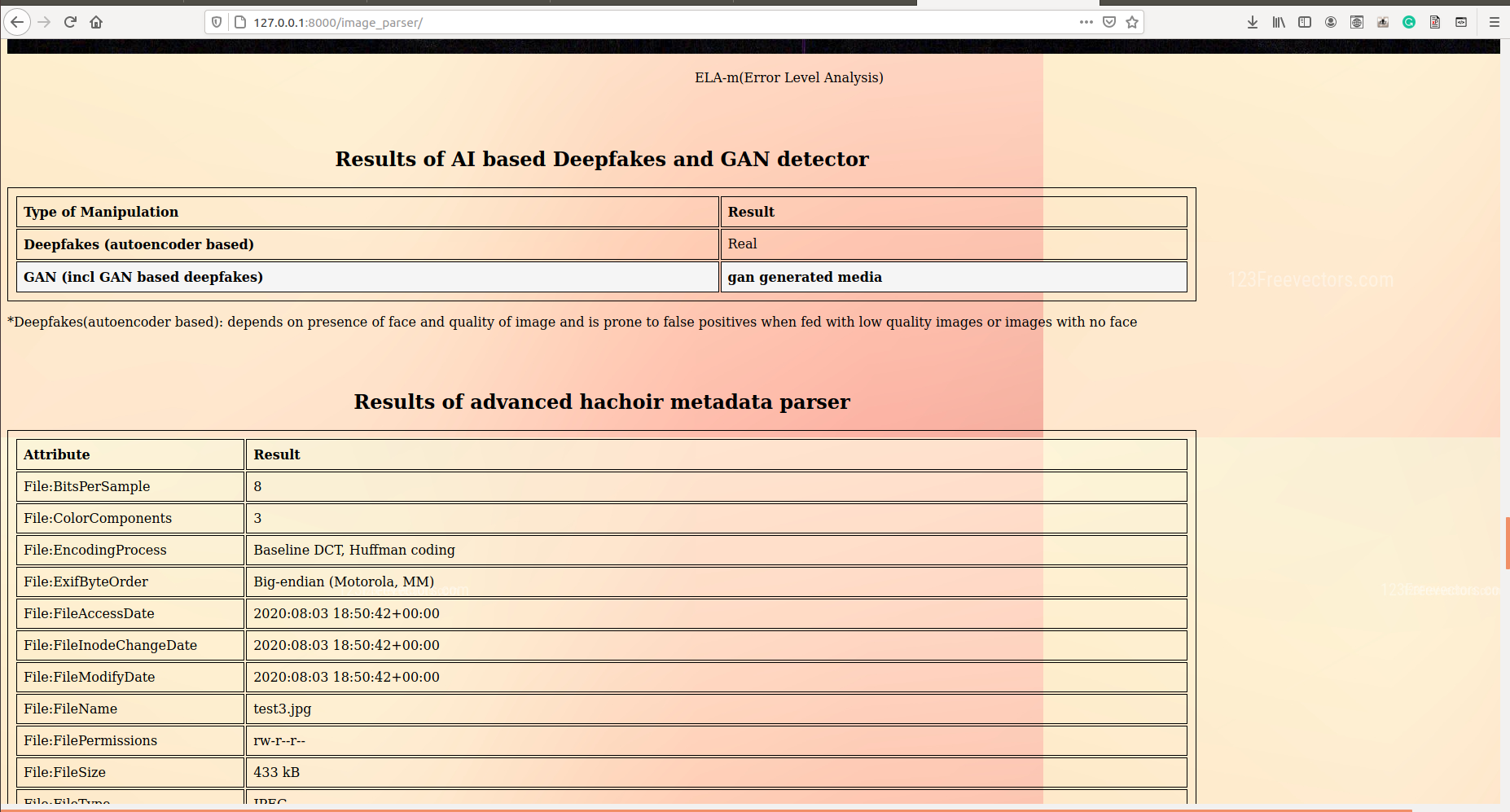
For the detection of GAN images/frames, we used a Finetuned DenseNet network along with an simple ANN( Artificial Neural Network). Sequential training was done on the network. Firstly, all layers apart from the last two layers of Densenet were frozen, and the model was trained on the rest of the layers. After initial training, all layers were unfrozen, and the whole model was again trained. Due to simultaneous training, the end layer’s (deciding layers) converge best to the global optima and give an accuracy boost to our model. Also Dropout(F 1 ) and batch normalization layers(F 2 ) were added regularly to prevent overfitting.
Implemented Statistical models
- Exif-Data Analysis
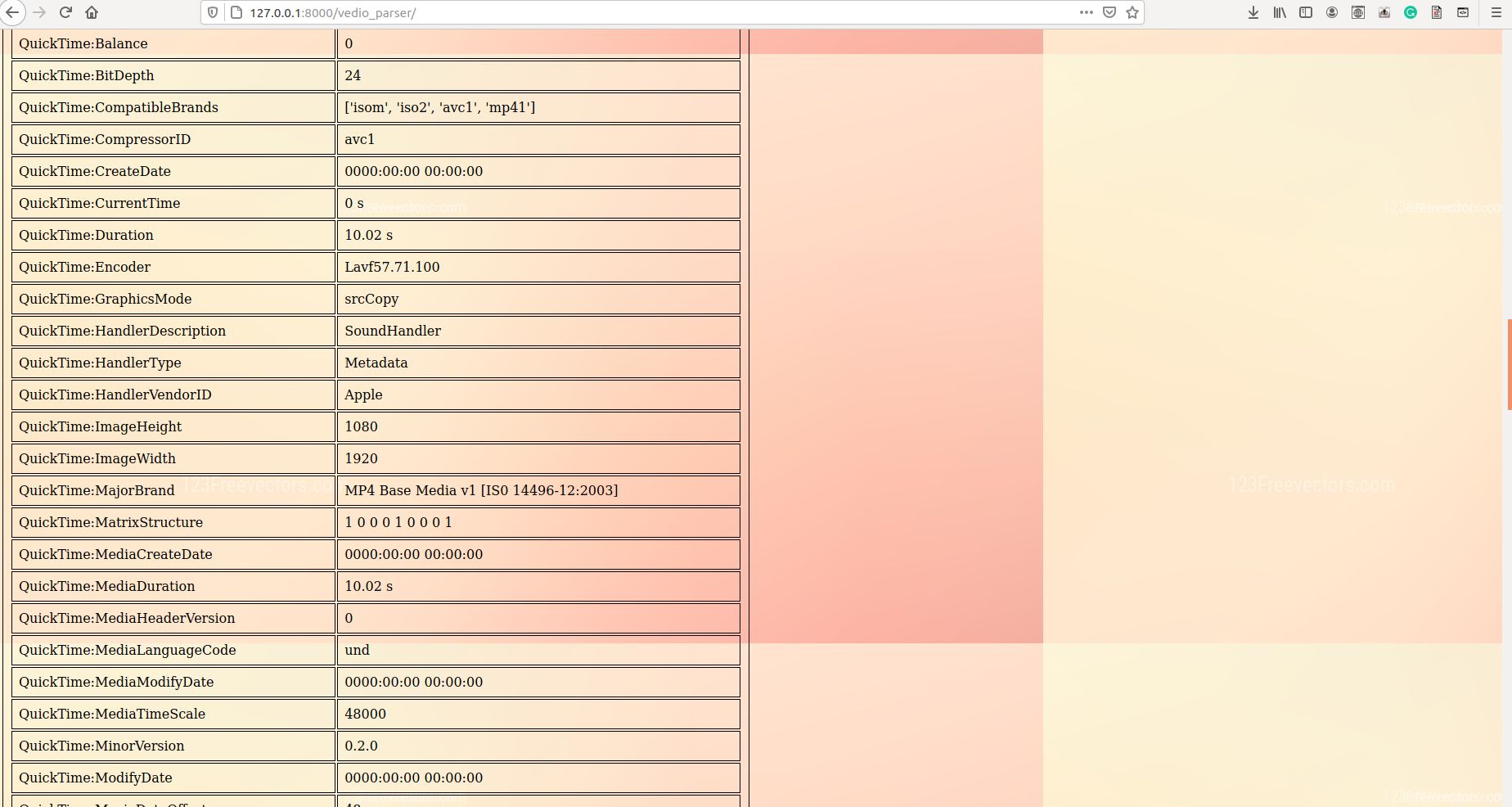
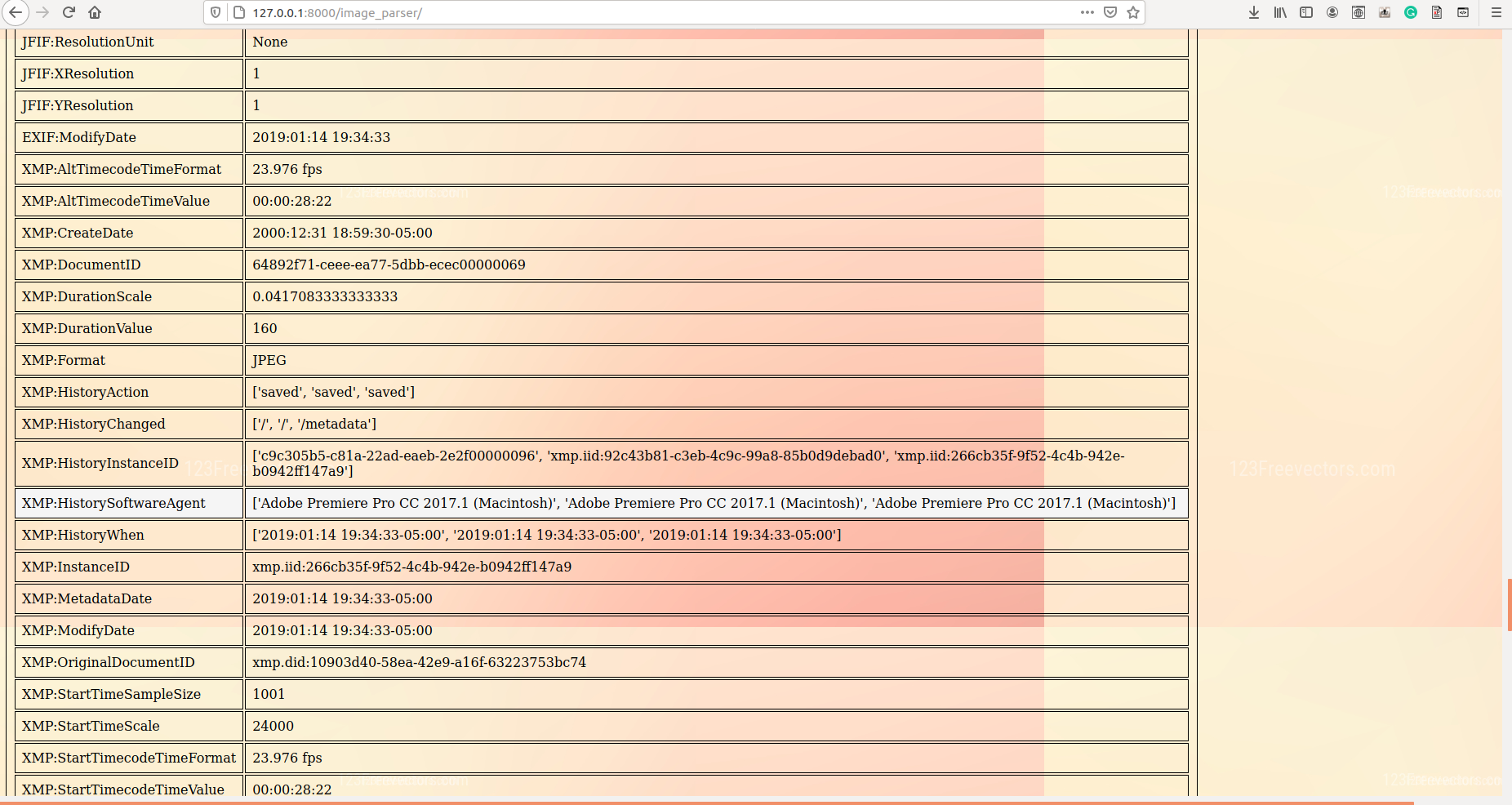
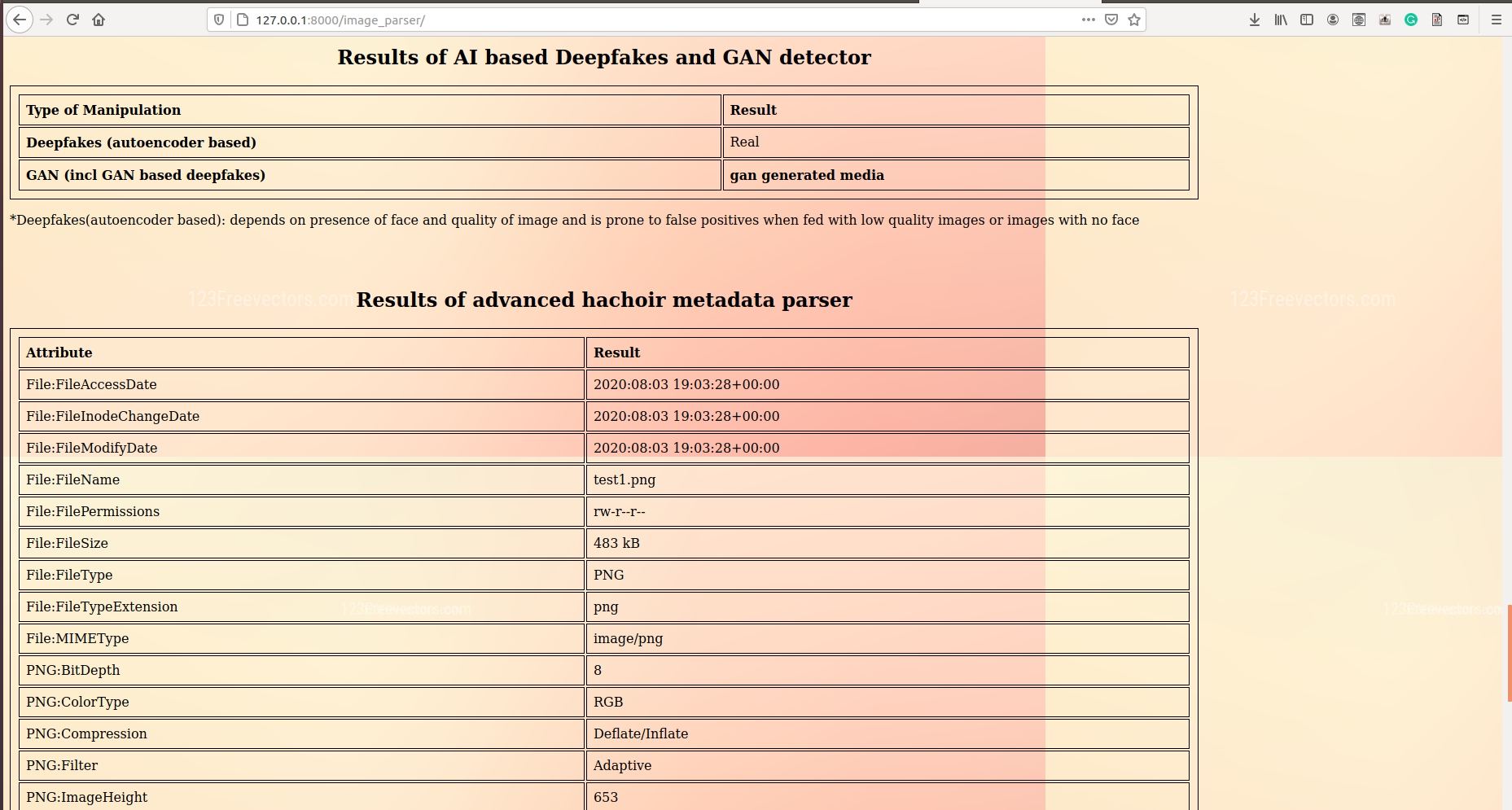
In our model, metadata extraction was done for all videos/images by using sequential use of a tool called ExifTool and a python package called hachoir. After data retrieval from both tools, the redundant data was removed and useful data like device id, device manufacturer, software used, encoder, etc were carved out into a .csv file. This piece of information, which is often neglected, can open new avenues to investigation and may also reveal personal identification proofs like the MAC address of original equipment used.
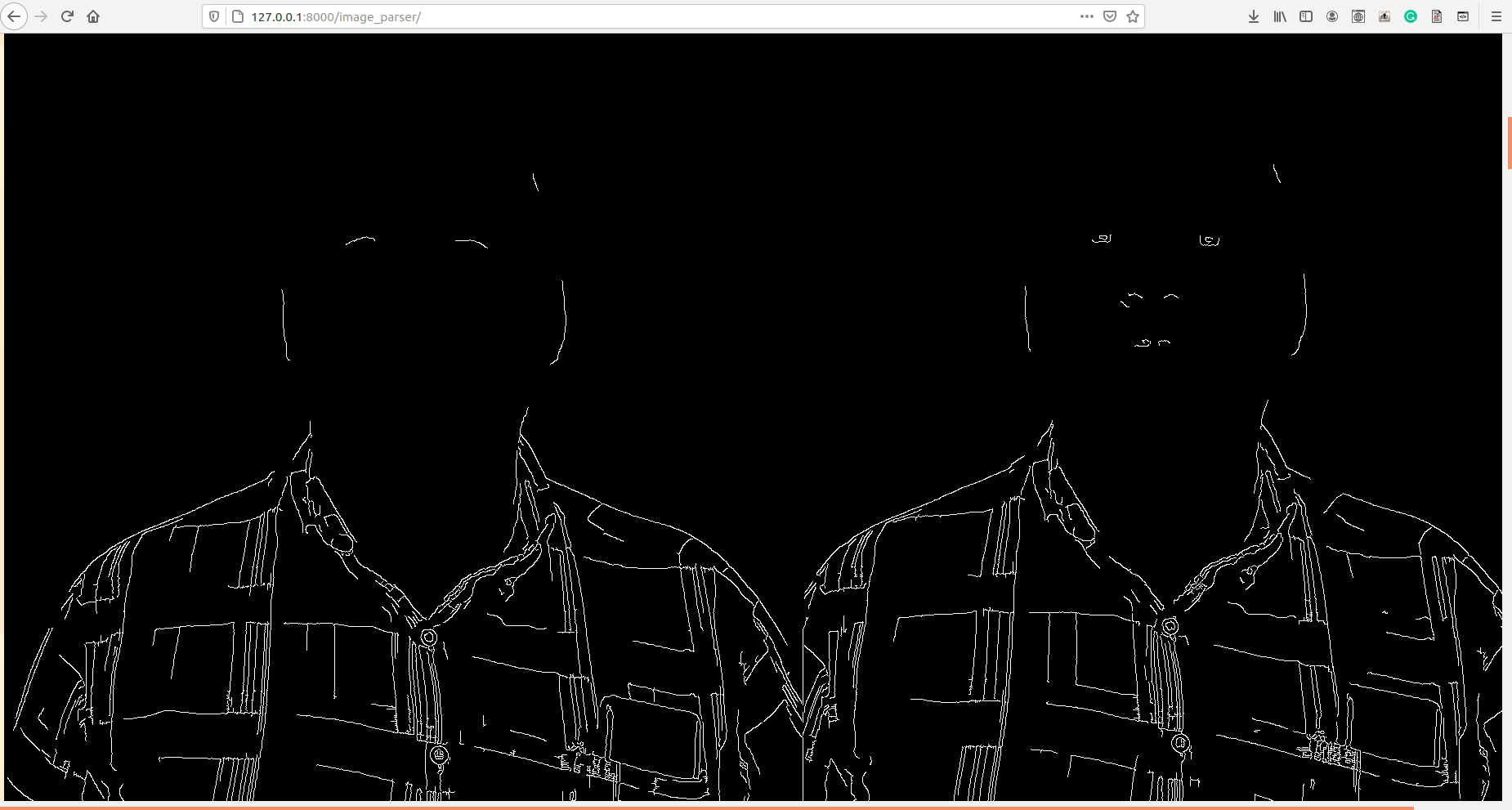
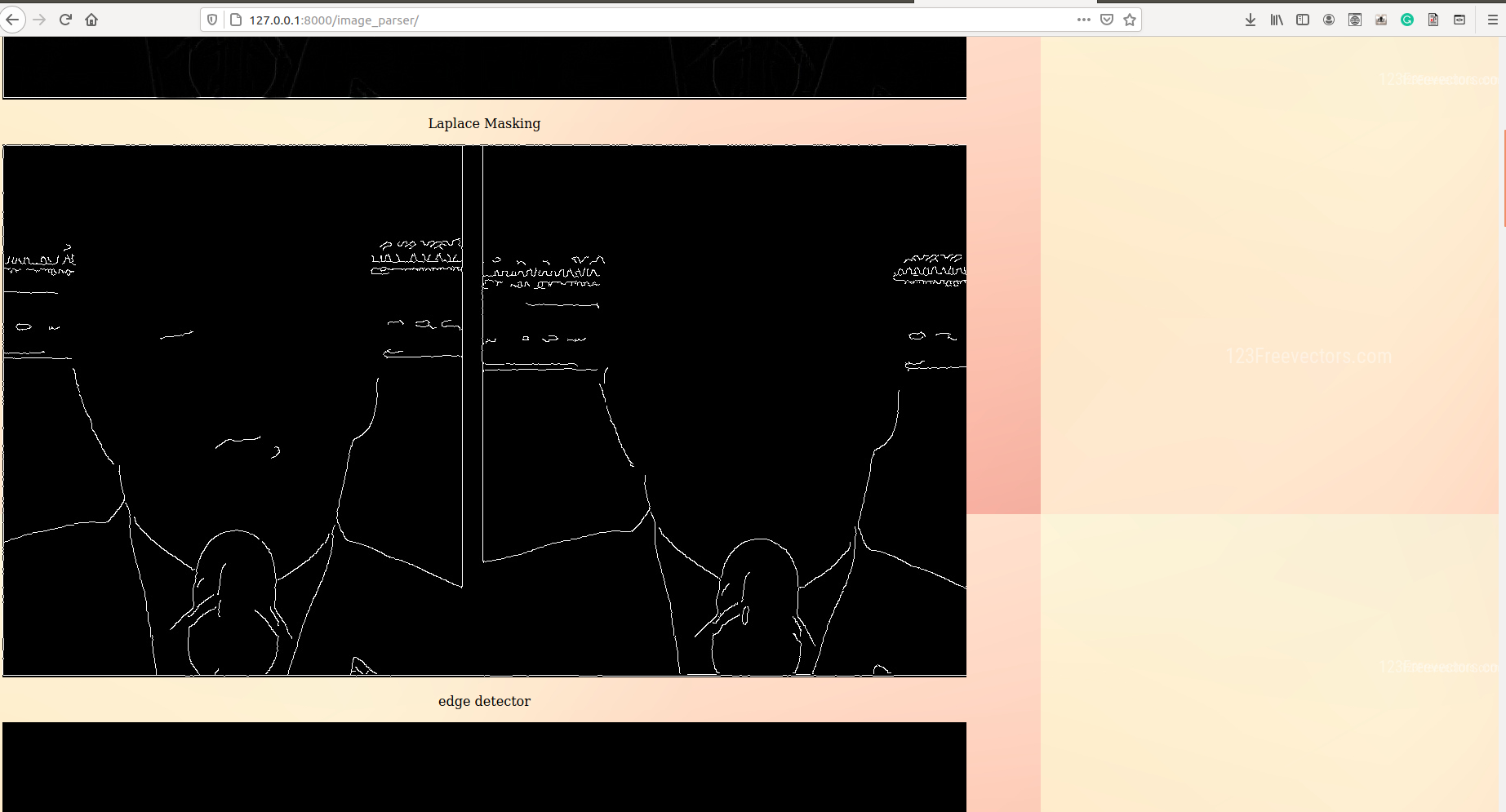
- Masking Algorithms Image masking is a process by which we can hide some aspects or parts of an image and highlight some other aspects of the image like highlighting high illuminance pixel entropy areas. Several masking algorithms like pixel density, Bitwise-AND masking, Variance Masking, Laplace detector, ELA are used in our project that can accurately detect any type of pixel based manipulation like photoshopped media(splicing, etc)
Future Scope
The future additions that could be made to this project are:
- Neural networks can be debugged for finding the performance of each layer of the network, thus finding any dead neuron or low learning by any layer.
- More juicy forensic artifacts could be collected by adding tools like Ghiro, JPEGsnoop ( better source to find last device used), stegsolve ( switch through the layers and look for abnormalities) to the main project, thus diversifying the static metadata information collected.
- Reverse searching of image/video could be added to the project, thus backtracking original digital media resource (scan through different open source search engines)
Built With
- django
- keras
- machine-learning
- scikit-learn
- scipy
- tensorflow


Log in or sign up for Devpost to join the conversation.