-
-

Medi Judge Landing
-
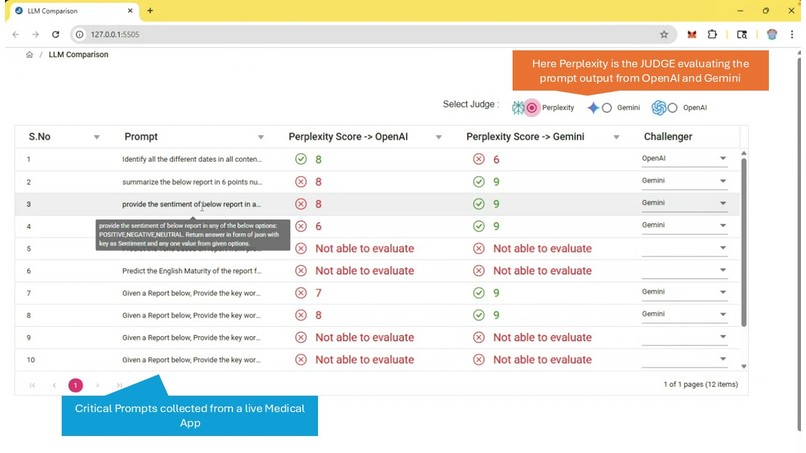
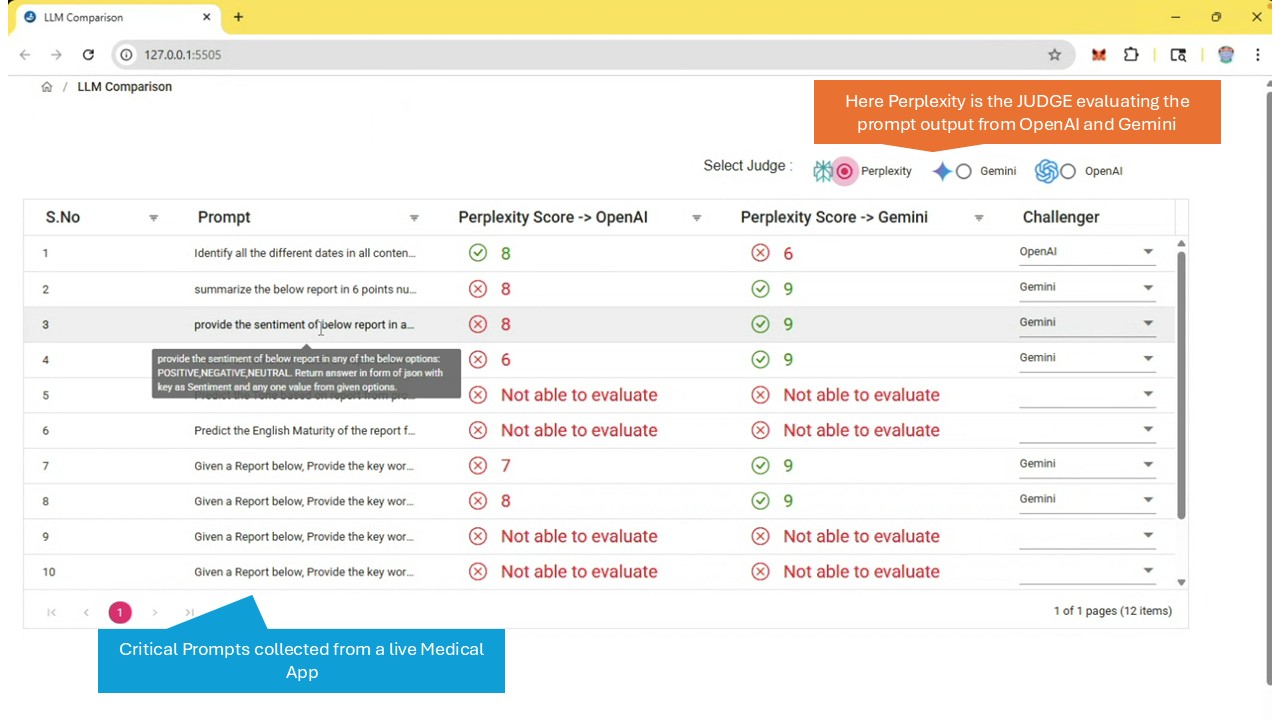
Perplexity Judging both OpenAI and Gemini for Accuracy
-
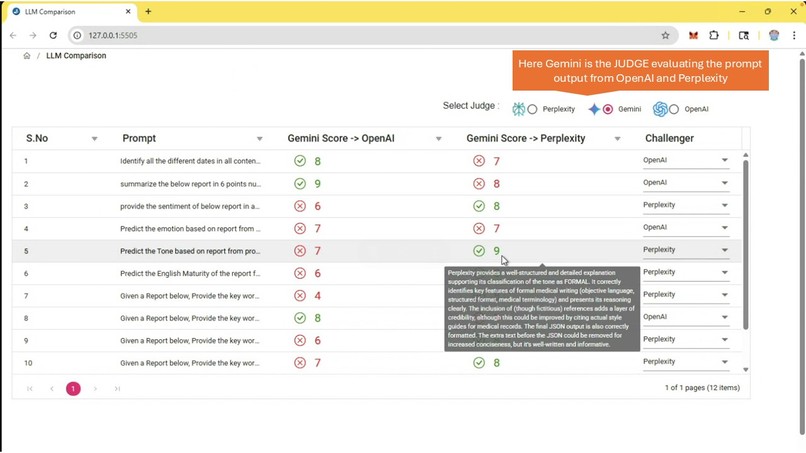
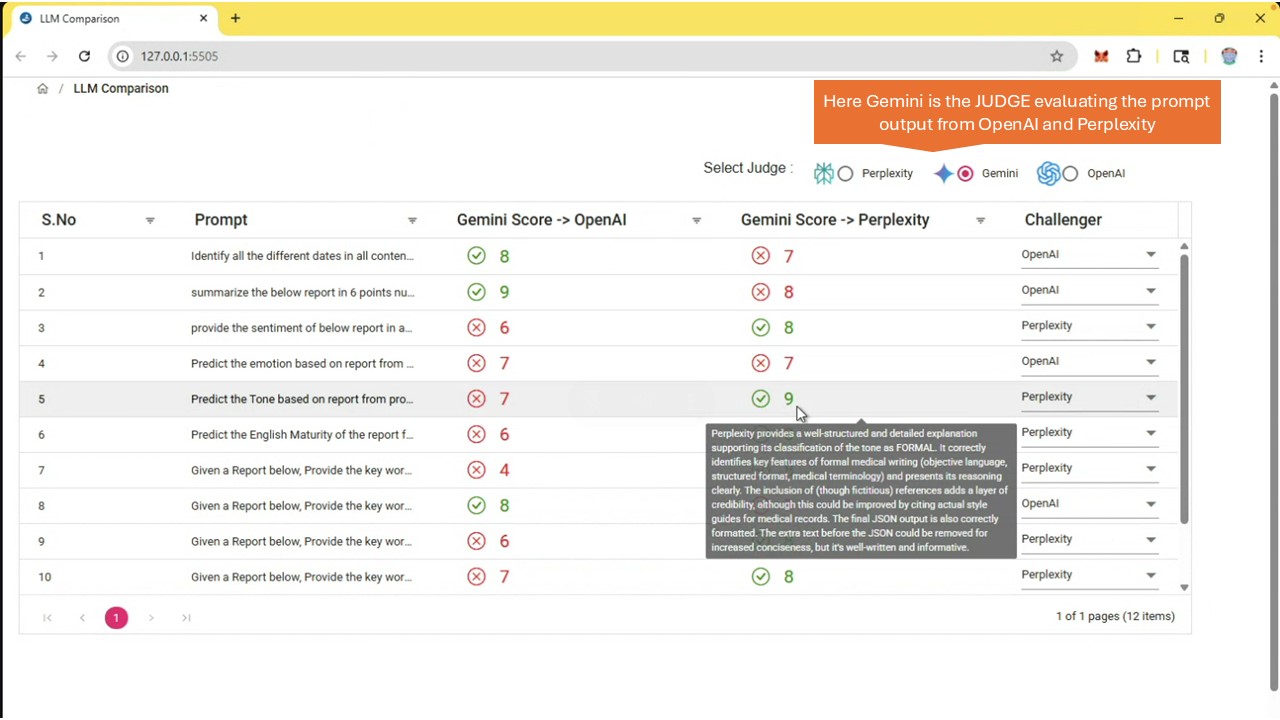
Evaluating Medical Mission Critical Data against Gemini
-
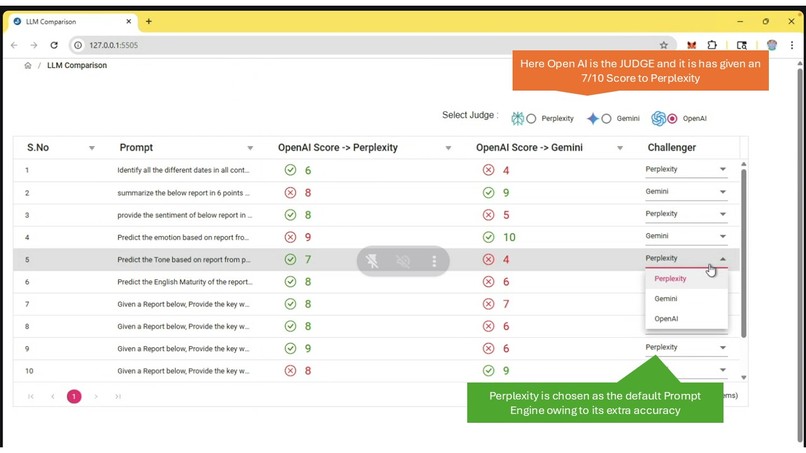
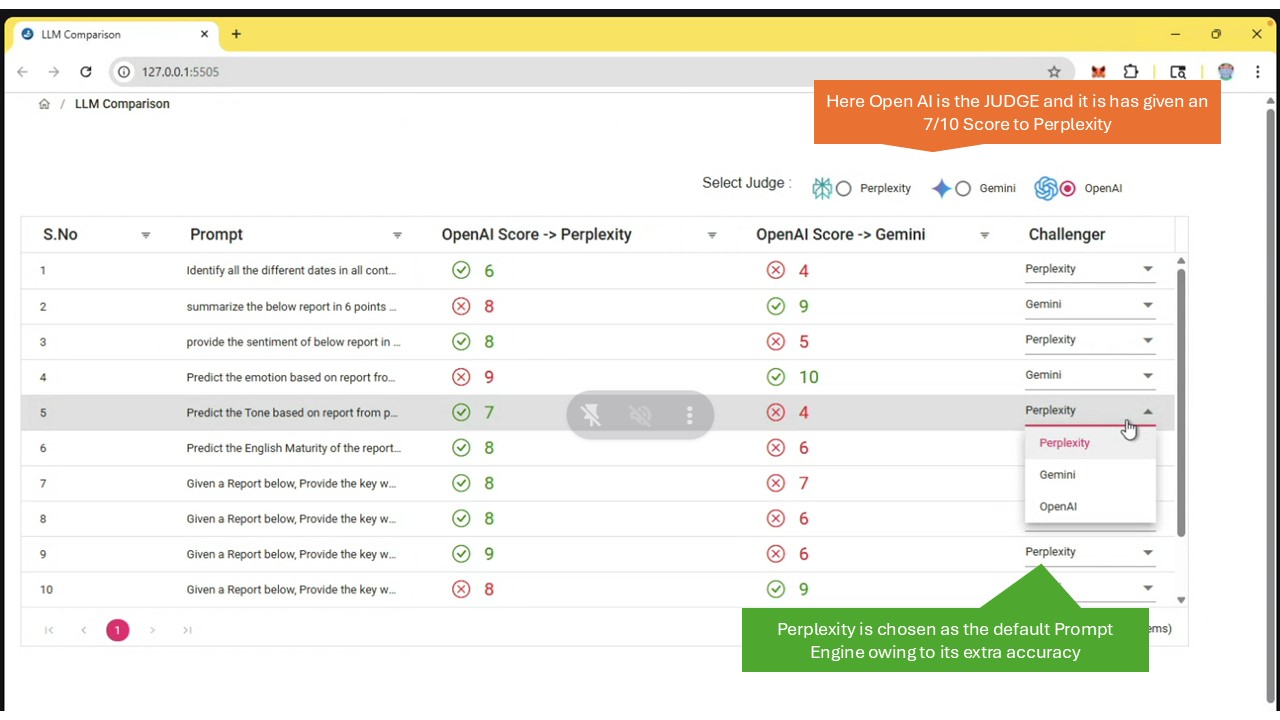
OpenAI choosing Perplexity as the winner

⚛️ Inspiration and Problem Statement
The rapid integration of AI into medicine without rigorous, independent validation creates significant risks, potentially jeopardizing patient safety through unverified outputs, perpetuating biases leading to health inequities, and eroding clinical trust, thereby causing a trust-issue of AI in medical industry.
Medi-Judge is a well-thought validation tool in medical AI to ensure patient safety, verify unbiased performance, and build clinical trust for reliable adoption in healthcare.
✔️ What it does
Medi-Judge leverages Perplexity as an independent third-party auditor in validating the AI information generated by various industry and domain standard LLMs like OpenAI, Gemini, Mistral etc.
This is an very interesting and novel concept for structuring an AI validation workflow.
Potential Strengths of this Approach:
Leveraging Existing Technology: Perplexity is known for its ability to synthesize information and provide sources from its searches.
Cross-reference claims: Check if the information generated by the primary LLM aligns with information found by Perplexity across the web.
Identify supporting sources (or lack thereof): Perplexity's citation feature could help flag statements that are not well-supported by its search results, prompting further human review.
Scalability for initial screening: For a large volume of AI-generated content, Perplexity could offer a first pass to flag outputs that seem inconsistent with broadly available information.
Third-Party Perspective: Using a different AI system (Perplexity) to check the output of another (e.g., OpenAI's model) introduces a layer of separation, which can be more "independent" than self-assessment by the original LLM.
☮️ How we built it
"Medi-Judge" is a developed and user-centric platform. Let's break down how these new components enhance the system:
Scoring Model at Prompt Level and Granular Evaluation : This is crucial. Evaluating each LLM response at the specific prompt level allows for nuanced understanding of an LLM's performance across different types of medical queries (e.g., diagnostic suggestions, drug information, patient education).
Quantitative Feedback: A scoring model provides a quantitative measure, which can be easier to track, compare, and benchmark over time or against different LLMs. The key will be the robustness and clinical relevance of the criteria feeding into this score.
Integration Point for Perplexity (and others): The audit by Perplexity (as discussed previously) could be one of several weighted factors contributing to this overall prompt-level score. Other factors might include checks for harmful content, clarity, relevance to the prompt, presence of disclaimers, or even human expert review scores if that's part of your workflow.
Standardization & Reproducibility: Using a JSON file for prompts ensures that evaluations are standardized and can be reproduced consistently. This is vital for comparing different LLMs fairly or tracking the improvement of a single LLM over time.
Scalability: It allows for easy management and expansion of the test set of medical prompts, covering a diverse range of medical topics and query complexities.
Categorization Potential: Prompts within the JSON could potentially be categorized (e.g., by medical specialty, query type, difficulty level), allowing for more targeted analysis of LLM performance. Flask Application for Easier Front End:
User Accessibility: A web interface significantly lowers the barrier to entry for users (clinicians, researchers, auditors) who may not have programming expertise. The users can interact with Medi-Judge, submit prompts, and view results and scores easily.
Interactive Evaluation: Users can input custom prompts or select from the predefined JSON list through this interface.
Visualization: The Flask front end is used to present the scores and validation insights in a more digestible format, using charts, tables, or highlighting specific areas of concern in the LLM output. Users Using It & Strong Concepts of Web Accessibility (e.g., WCAG compliance):
Practical Utility: This confirms the tool is designed for actual use, not just as a theoretical framework. Inclusivity: Prioritizing web accessibility from the outset is commendable and essential, especially in healthcare. It ensures that the tool can be used by a wider range of individuals, including those with disabilities. This aligns with ethical considerations in medical technology.
♒ Challenges we ran into
The Core: Validation Criteria within the Scoring Model: The effectiveness of Medi-Judge is heavily dependent on the "scoring model" . What specific metrics does it measure? How are these metrics weighted? How well do these metrics correlate with actual clinical safety, accuracy, and utility? This is where the integration of Perplexity's audit, human oversight, or other validation techniques becomes critical. We trusted Perplexity to provide non-biased grounding facts when doing the evaluation
Transparency of Scoring: For users to trust Medi-Judge, the scoring mechanism should be as transparent as possible. Users should ideally understand what contributes to a good or bad score. Explaining the workflow, Users would interact with the Flask app, select or input a prompt, choose the LLM(s) to test, and then Medi-Judge would process this, by sending the prompt to the selected LLM, getting the response, running it through its scoring model (which involves querying Perplexity and applying other checks), and then displaying the scored output and analysis on the front end.
Human-in-the-Loop: Even with Perplexity and a scoring model, for high-stakes medical validation, incorporating a human review step (facilitated by the Flask app) for ambiguous or critical findings would be highly advisable. The scoring could help prioritize which outputs need human attention. Calibration and Benchmarking: How will you calibrate your scoring model? Will you compare its outputs against expert evaluations or known "gold standard" responses for a subset of prompts?
🔯Accomplishments that we're proud of
Establishment of a Structured and Standardized Evaluation Framework: Creating a systematic process for judging medical LLM outputs. This is achieved through the use of a JSON-defined set of prompts, which allows for consistent, reproducible, and scalable testing across different LLMs or versions. This structured approach is foundational for reliable validation.
Implementation of a Quantitative, Prompt-Level Scoring Model: Moving beyond purely qualitative assessment to a quantitative scoring system at the individual prompt level. This allowed for more granular, objective (based on its defined criteria), and comparable evaluations of LLM performance, making it easier to track improvements and identify specific weaknesses.
Development of a User-Centric and Accessible Platform: Building a Flask application for the front end, prioritizing ease of use for various users (clinicians, researchers, etc.) and explicitly incorporating strong web accessibility concepts. This made the tool practical, inclusive, and more likely to be adopted and used effectively in the medical community.
Innovative Integration of an Independent Audit Layer Concept: Conceptualizing and incorporating the idea of leveraging a third-party AI like Perplexity as an independent auditor within the validation workflow. While the nuances of LLM-auditing-LLM require careful handling, the vision to add such a layer for cross-referencing and source checking represents a forward-thinking approach to enhancing validation depth.
Dedicated Focus on Ensuring Medical AI Integrity and Safety: The entire tool, "Medi-Judge," is specifically designed to address the critical need for validating AI-generated information in the high-stakes medical field. This focus on patient safety and the trustworthiness of AI in healthcare is a significant accomplishment in itself, tackling a pressing industry challenge. These accomplishments, when realized, would make Medi-Judge a valuable contribution to the responsible development and deployment of LLMs in medicine.
☯️ What we learned
The concept of Medi-Judge using Perplexity as an initial or supplementary layer in a validation process is innovative. Perplexity could be a useful tool for preliminary checks, source identification, or broad consistency screening. However, for robust medical AI validation, we understood that thus would likely need to be part of a multi-layered approach heavily involving human medical expert oversight, clearly defined validation criteria rooted in medical best practices, and an understanding of the inherent limitations of using one AI to audit another in such a critical domain.
🕎 What's next for Medi-Judge
Based on the features and design philosophy you've described for "Medi-Judge," here are what we believe would be its top 5 accomplishments upon successful development:
Establishment of a Dedicated Medical AI Validation Framework: A significant accomplishment is the creation of a specialized system focused specifically on the critical need for validating LLM outputs in the medical industry. This inherently addresses a major challenge in the responsible adoption of AI in healthcare by providing a structured approach to assess information that can directly impact patient safety and care.
Implementation of a Quantitative, Prompt-Level Scoring Model: Developing a scoring model that evaluates LLM responses at the individual prompt level is a key achievement. This allows for granular, objective (or at least consistently applied subjective) assessment of AI performance across diverse medical scenarios. This quantitative feedback is crucial for benchmarking, comparing different LLMs, and identifying specific areas of weakness or strength. We now have a basic quantitative model and would like to explore more better models
User-Centric Design with Enhanced Accessibility: Building Medi-Judge with a Flask front-end for ease of use by clinicians, researchers, and auditors, coupled with a strong commitment to web accessibility (e.g., WCAG compliance), is a major accomplishment. We would like to extend it to a simpler React based mobile and multi-form factor User Centric Design
Innovative Integration of Third-Party Auditing Concepts: While the practical implementation requires careful consideration, the conceptualization of leveraging an external AI system like Perplexity as an "independent third-party auditor" within the validation workflow is an innovative step. This demonstrates forward-thinking in designing multi-layered validation strategies, aiming to introduce an additional layer of scrutiny to the AI-generated medical information.
We believe there is a lot of way forward for Perplexity to be the leader and also run alongside with all standard LLMs.




Log in or sign up for Devpost to join the conversation.