-
-
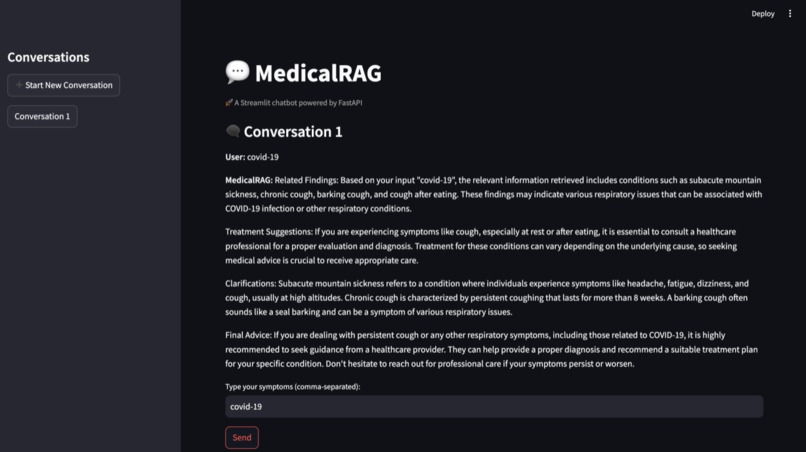
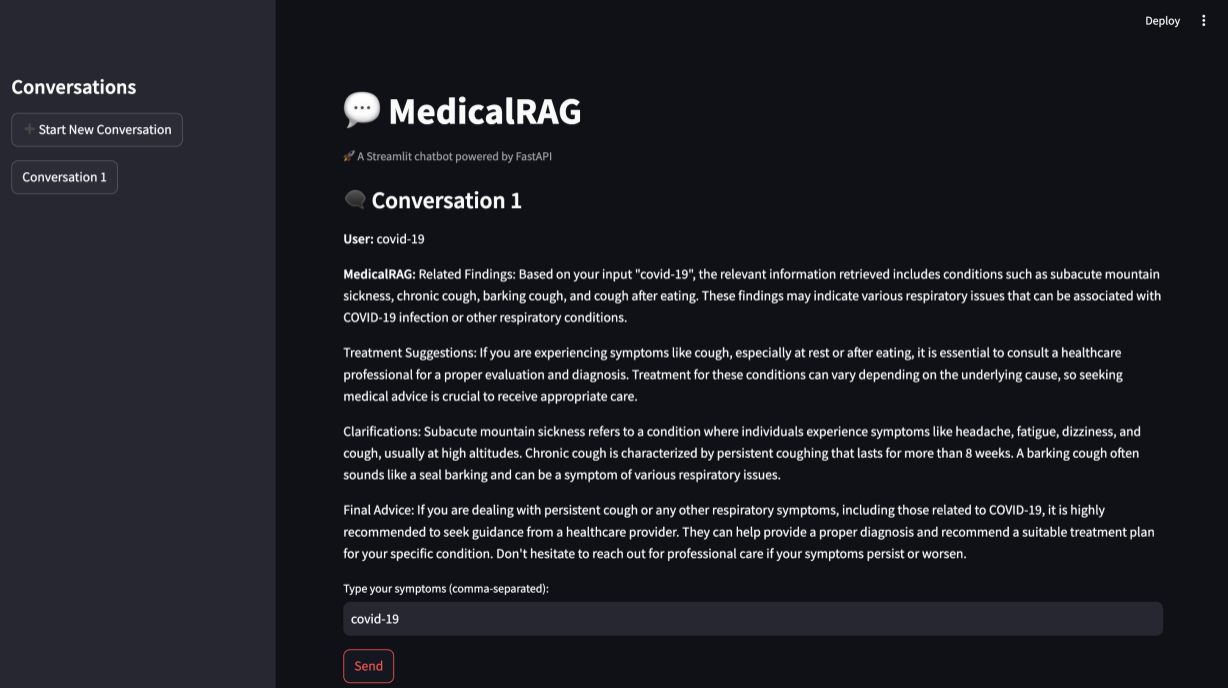
Website
-
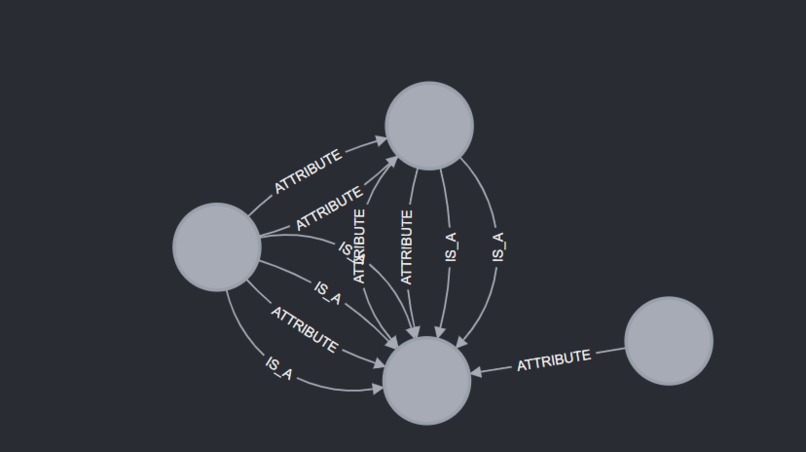
Relationships between the Nodes
-

Overview of Graph
-

Node Properties



Inspiration
During the early days of the COVID-19 pandemic, when information was scarce and uncertainty ran high, my close friend's father fell ill. He struggled with symptoms that didn’t seem to match anything he’d experienced before, but with the healthcare system overwhelmed and knowledge about the virus still evolving, he couldn’t get the answers he needed in time. Tragically, his condition worsened before a proper diagnosis could be made. This experience deeply impacted me and sparked an idea: what if people could have access to reliable, up-to-date health information, backed by trusted sources like the National Institutes of Health? That’s when I decided to develop a tool that could help individuals diagnose themselves quickly and safely, empowering them to seek timely medical attention, and ultimately save lives during times of uncertainty.
What it does
This project is a self-diagnosis tool designed to help individuals identify common symptoms associated with various health conditions, including viral infections like COVID-19. By inputting their symptoms into the system, users can receive reliable recommendations based on up-to-date information from trusted sources such as the National Institutes of Health (NIH). This project uses Neo4j which is a database that can store graphs. Our graph contains near 3 million relationship across 500,000 nodes. The tool helps users understand whether their symptoms might require professional medical attention, empowering them to make informed decisions and seek proper care quickly. It aims to bridge the gap in healthcare information, especially during times of uncertainty, providing a reliable first step in managing health concerns.
How we built it
The provided code integrates multiple technologies to build a medical chatbot powered by FastAPI, Streamlit, OpenAI, Neo4j, and ClinicalBERT. The key components are:
FastAPI & Streamlit: FastAPI handles the backend API, where symptom data is processed and queried from a Neo4j knowledge graph, while Streamlit provides a frontend interface to interact with the user. A chatbot interface allows users to input symptoms, which are processed by OpenAI's GPT-3.5 to generate relevant medical conditions and treatments.
Neo4j & ClinicalBERT: Neo4j is used for storing and querying medical relationships and symptoms through a knowledge graph, while ClinicalBERT (a specialized transformer model) is utilized to compute semantic similarities between symptoms and related medical terms. This enables the system to recommend possible conditions based on user inputs. The integration of these components facilitates a dynamic medical information retrieval system, where user symptoms are matched against a comprehensive medical knowledge base for tailored responses.
Challenges we ran into
One of the major challenges faced was handling the large-scale data in Neo4j, which included over half a million nodes and 3 million relationships, each with numerous properties. Managing such a vast amount of data required careful planning to ensure efficient storage, querying, and indexing.
Additionally, cleaning the data to ensure consistency and accuracy was a significant hurdle. The dataset likely contained inconsistencies, missing values, and incorrect relationships, all of which needed to be addressed. This process involved data wrangling techniques such as deduplication, standardization, and normalization, along with ensuring that the nodes and relationships were appropriately structured to support fast, accurate queries. Optimizing Neo4j’s indexing and query patterns to handle such large datasets also became crucial for maintaining performance and reliability, especially during complex queries related to symptom matching and medical condition retrieval.
Accomplishments that we're proud of
One of the accomplishments I'm most proud of is successfully integrating everything together. It took many sleepless nights, but seeing the entire system come together seamlessly was incredibly rewarding. Despite the challenges, we were able to ensure that all the components — from data ingestion and cleaning to query optimization and interface design — worked in unison. This full integration was a major milestone, and it's satisfying to know that all the hard work, troubleshooting, and late nights paid off in a system that functions as intended.
What we learned
Through this project, we learned a great deal about working with Neo4j, particularly in terms of managing and querying large datasets. Handling over half a million nodes and millions of relationships required us to deeply understand graph database optimization techniques, including how to efficiently structure data and index properties. We also learned how to create APIs from scratch, ensuring they were scalable and could handle the complexity of our dataset. This process gave us valuable insights into data modeling, performance tuning, and managing large volumes of data, which will be crucial for future projects involving big data.
What's next for MedHelp
Next for MedHelp, we plan to enhance the graph by adding more properties to the nodes and relationships. This will provide more granular insights and improve the overall utility of the data model. Alongside this, we'll focus on optimizing the search procedures. By implementing more efficient algorithms, such as indexing or introducing caching mechanisms, we aim to significantly reduce search times and improve the performance of the system, ensuring it can handle increasing data volumes and user queries more efficiently. This will ensure MedHelp is scalable and capable of supporting a growing user base while maintaining high performance.

Log in or sign up for Devpost to join the conversation.