-
-
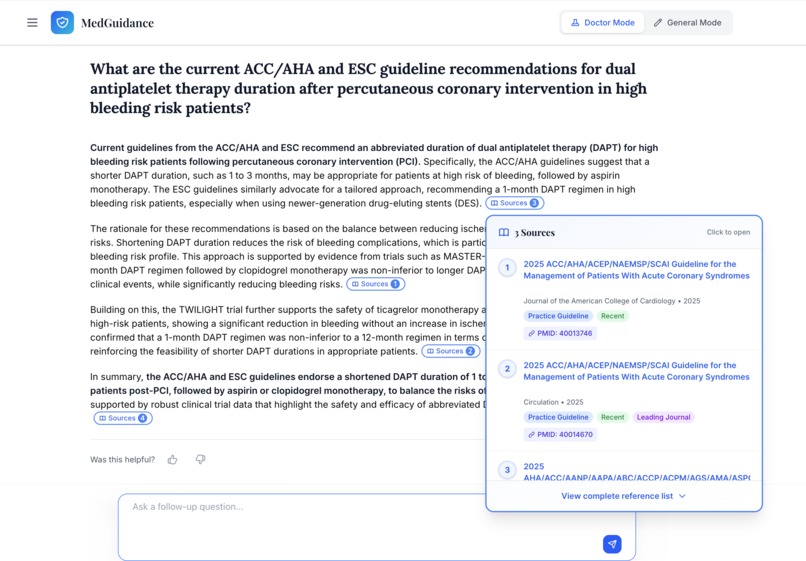
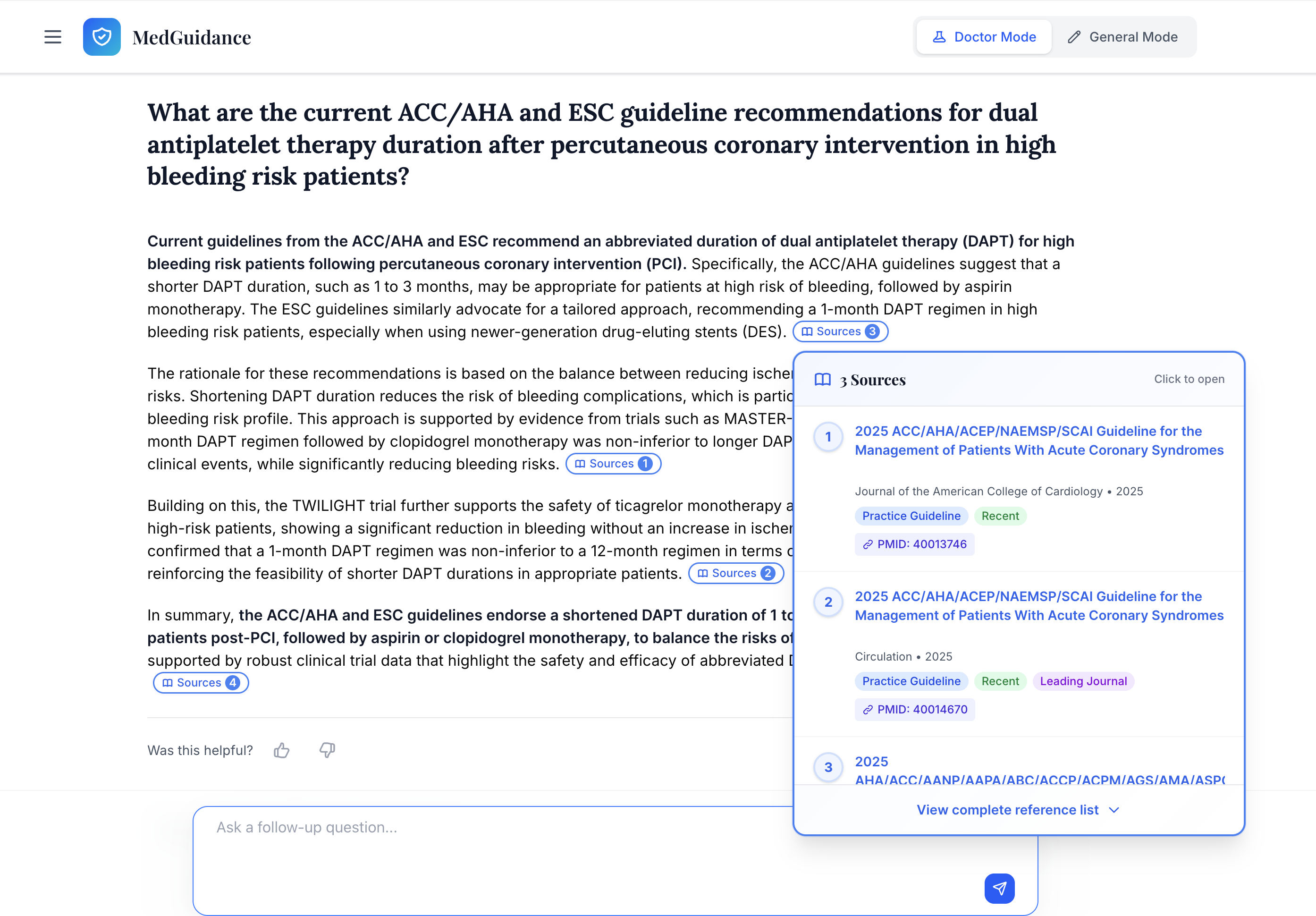
Dr. Mod is specially designed for health professionals to get a clear, evidence-backed answers.
-
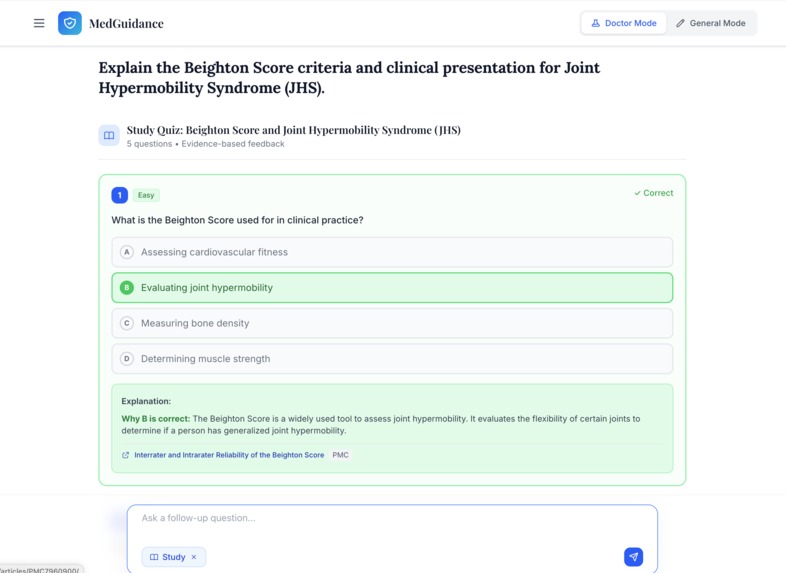
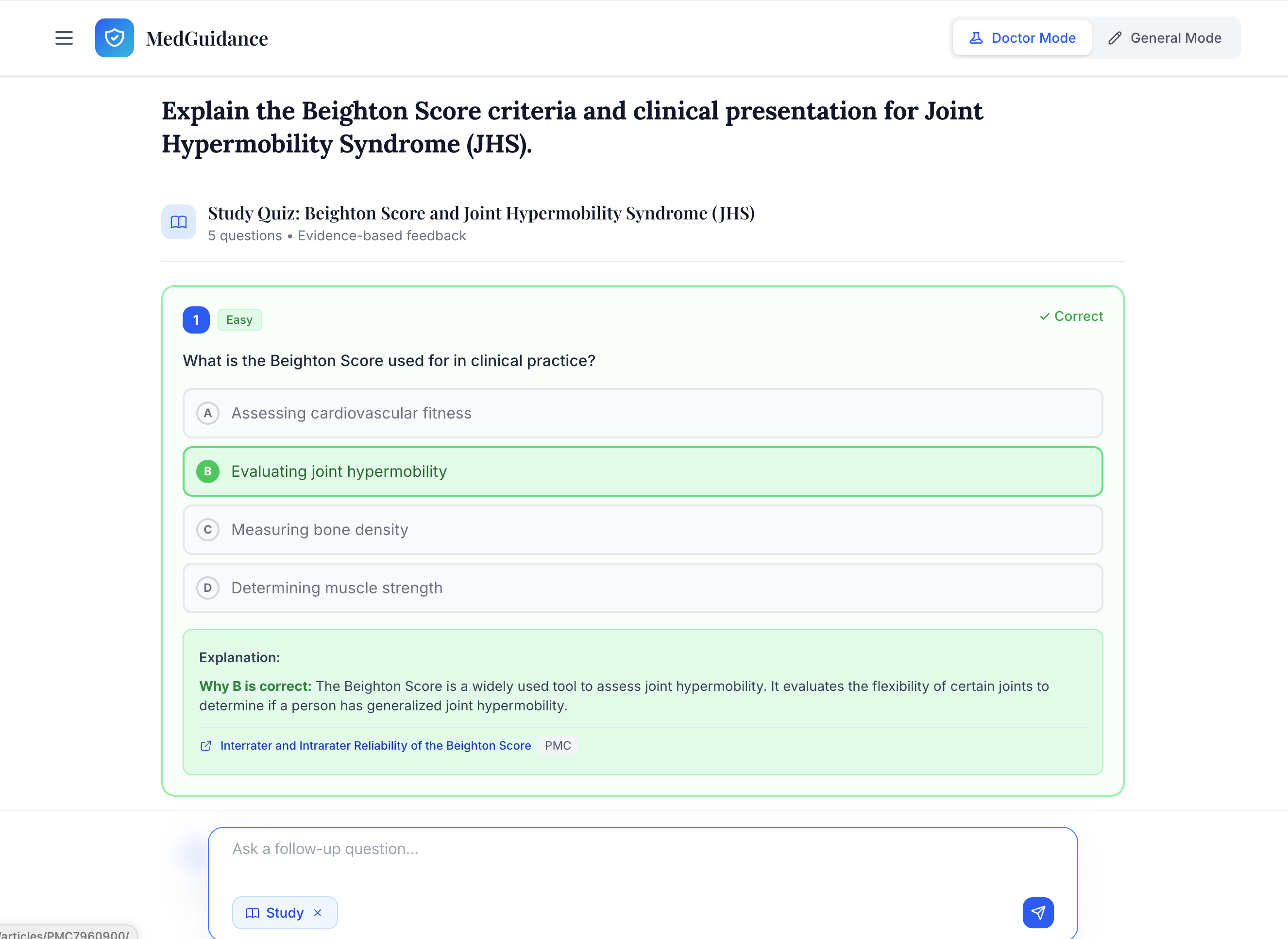
Study Mode is specially designed for medical students to dive deep into the topic.
-
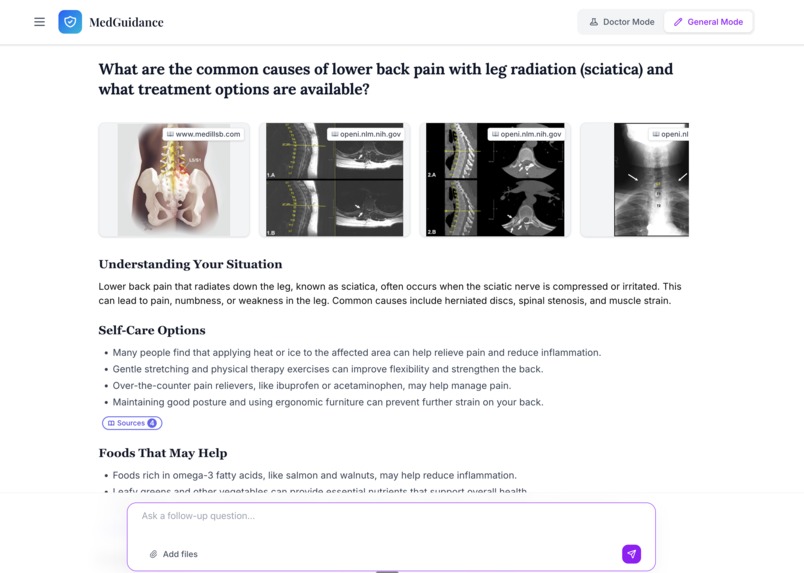
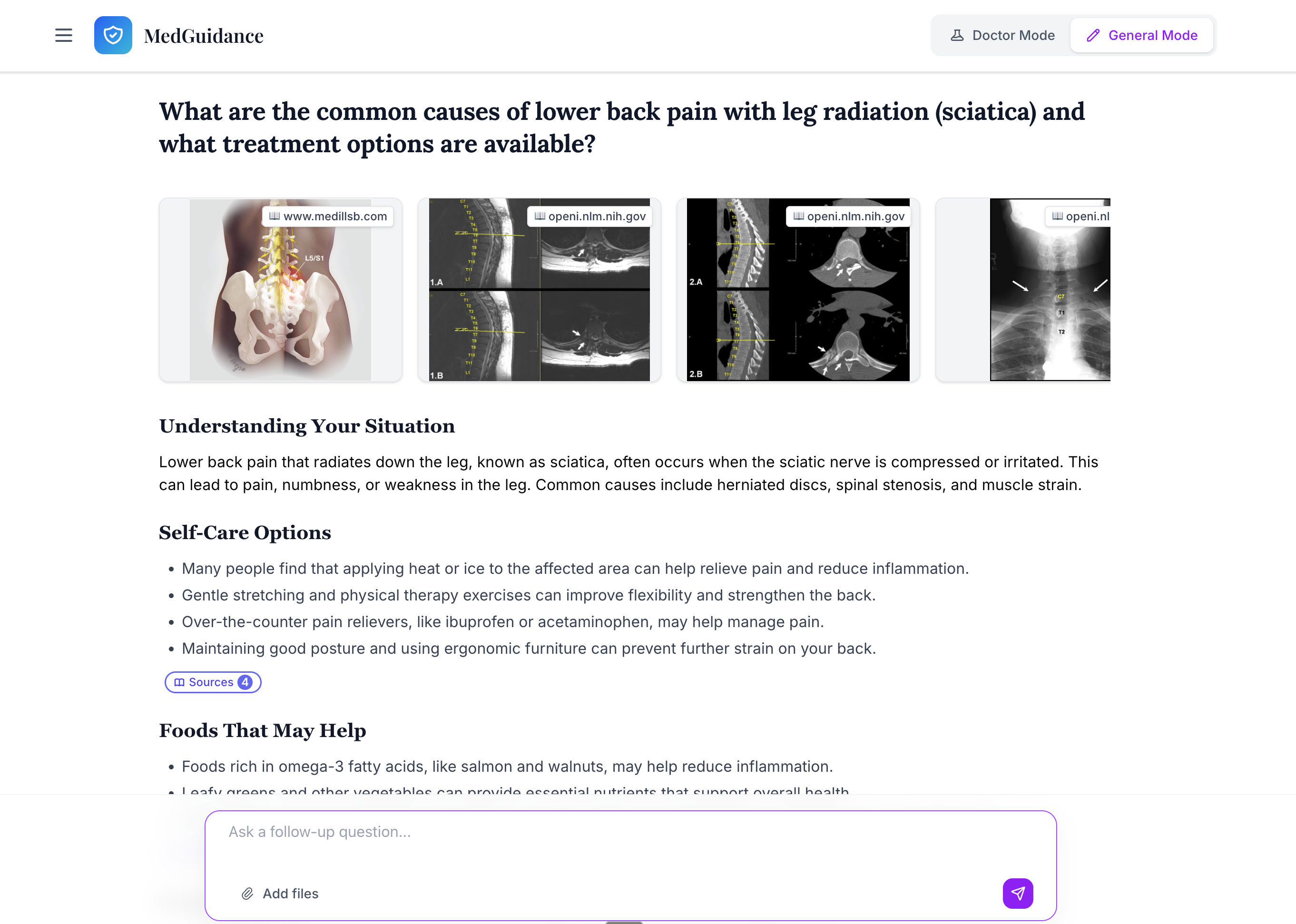
General Mode is designed for the audiance who need evidence to treat simple issues.
-
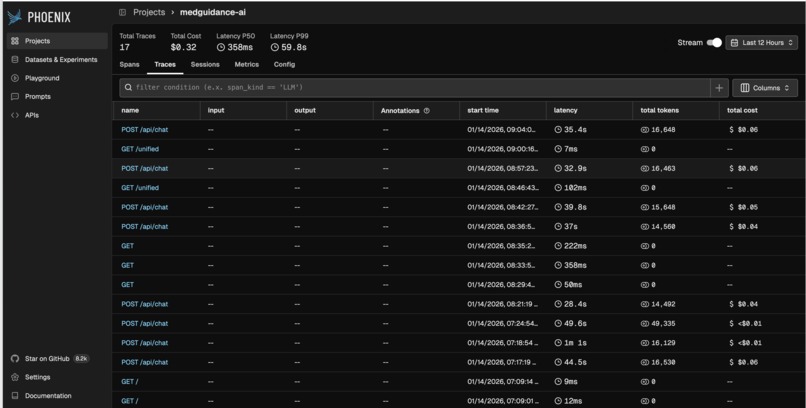
Phoenix (Arize-AI)
-
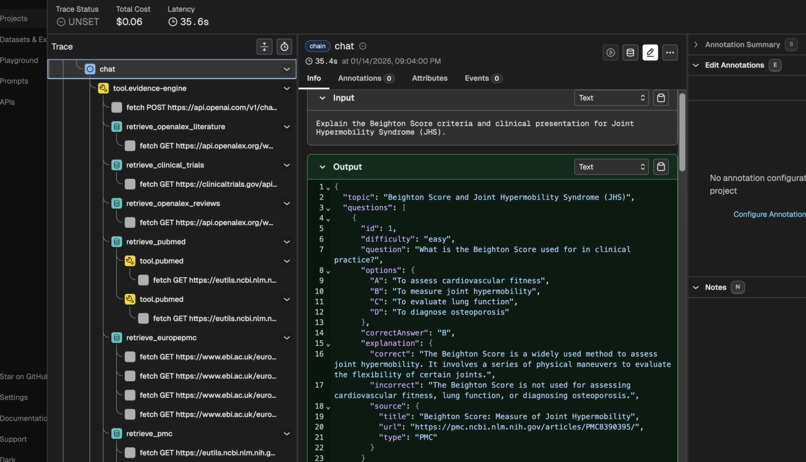
LLM Observatory: to track the traces, tools, and the complete workflow.
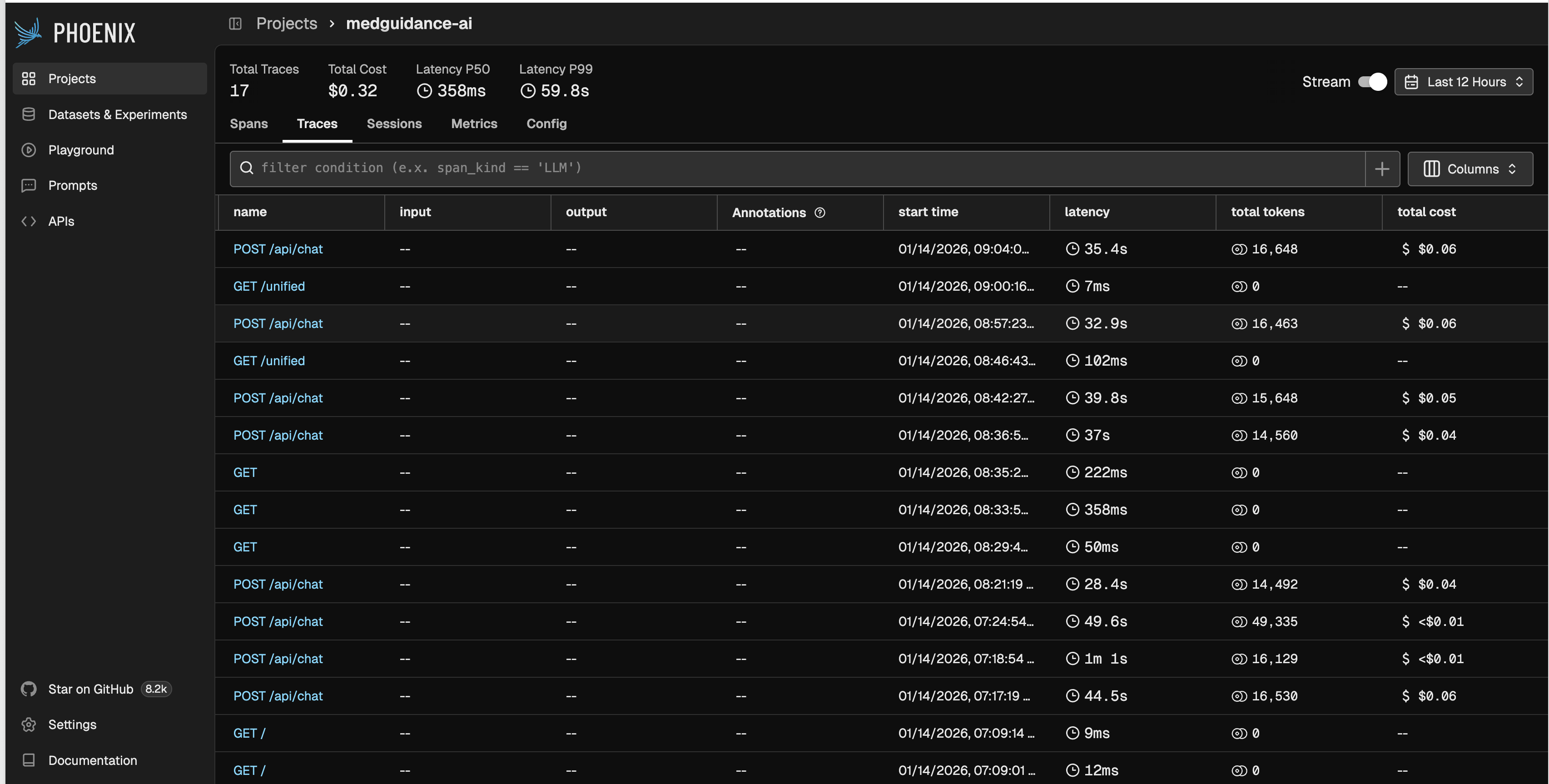
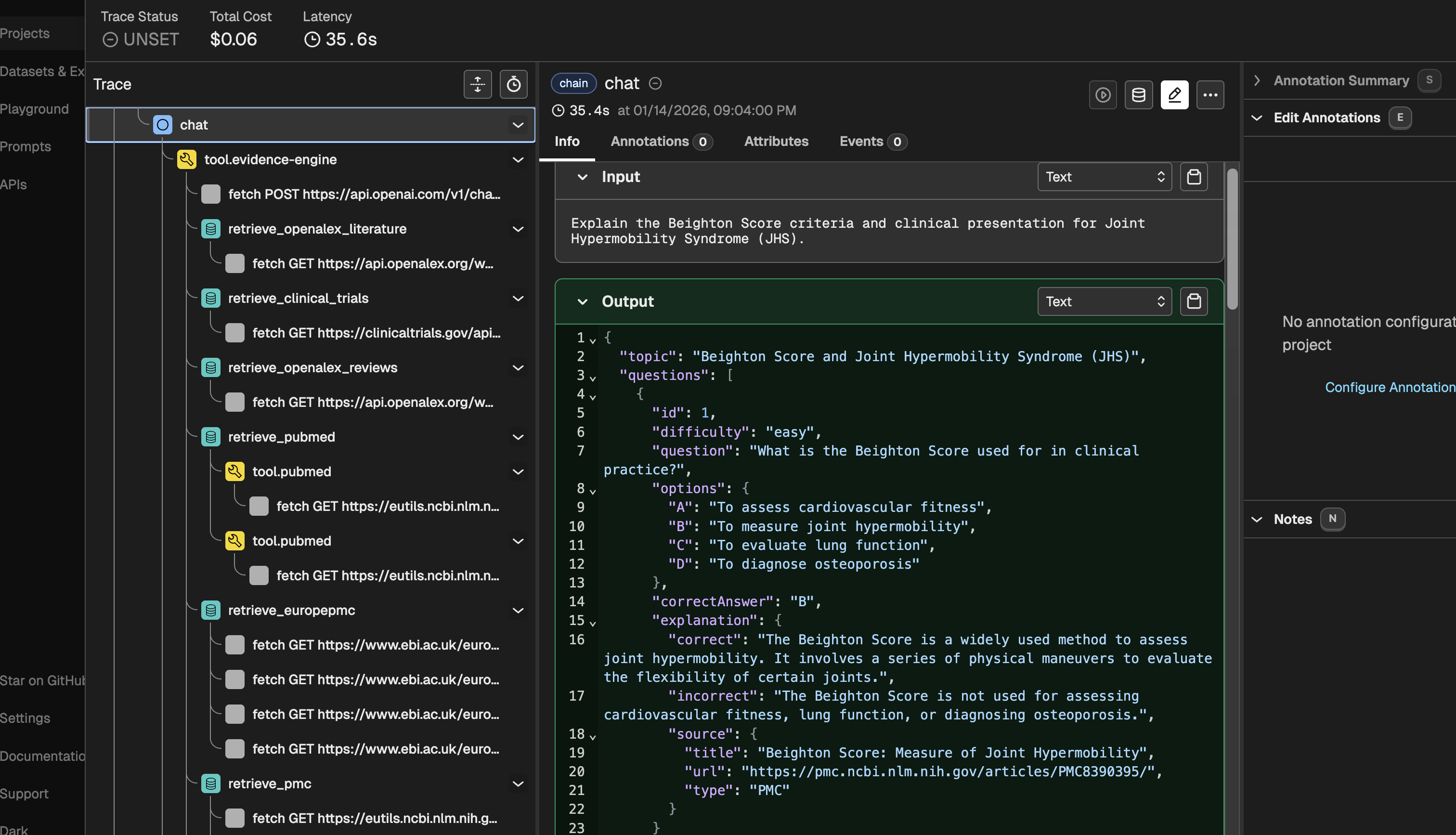
About the Project
The problem that inspired me
Indian health professionals are under intense pressure. To make a single safe clinical decision, they often need to read multiple PubMed papers, guidelines, and reviews—jumping across tabs for hours just to confirm a treatment approach. This is mentally exhausting and hard to sustain in a busy practice.
At the same time, general‑purpose LLMs like ChatGPT or Gemini can be confident but wrong, hallucinating studies, guidelines, or dosing recommendations. For medicine, that’s not just inconvenient—it’s unsafe.
I built MedGuidance AI to address this gap: a tool that behaves like a point‑of‑search evidence engine for clinicians and students, not a black‑box “AI doctor.”
What I built: MedGuidance AI
MedGuidance AI is a source‑first medical assistant with two modes:
- Doctor Mode – An evidence‑based clinical copilot for health professionals. It surfaces guidelines, landmark trials, and high‑quality studies with verified citations and concise, action‑focused summaries.
- General Mode – A consumer‑friendly health information assistant that uses the same evidence engine but explains things in plain language, includes “When to see a doctor” guidance, and has built‑in safety rules for mental health and crisis queries.
In both modes, the core principle is the same: “Source‑first, LLM‑second.” The model never answers from its memory alone; it must read from real medical sources.
How I built it (technical overview)
I designed the system around a strict retrieval‑and‑reranking pipeline:
Evidence collection from 57+ medical sources
MedGuidance queries a large set of trusted databases and APIs, including PubMed, Cochrane, WHO, CDC, NICE, ClinicalTrials.gov, OpenFDA, DailyMed, RxNorm, Semantic Scholar, MedlinePlus, and more.- Google Search is intentionally disabled.
- Real‑time search uses Tavily but is restricted to medical domains only and used as a fallback when internal evidence is insufficient.
- Google Search is intentionally disabled.
Beijing ReRanker (BGE Cross‑Encoder) for relevance
All retrieved documents are passed through a BGE Cross‑Encoder (“Beijing re‑ranker”). For each clinical question, the model scores how relevant each paper, guideline, or trial is to that query.- I added domain‑specific boosting so that up‑to‑date guidelines and systematic reviews outrank weaker evidence like case reports.
- When scores cluster, I use lexical tie‑breakers and Jaccard similarity to pick truly relevant items instead of near‑duplicates.
Anchor guidelines and landmark trials
The engine can detect common clinical scenarios (e.g., sepsis, CAP, diabetes, heart failure, AF, PE) and automatically inject:- Anchor guidelines (e.g., Surviving Sepsis Campaign, IDSA/ATS CAP, ADA Standards, ACC/AHA cardiovascular guidelines).
- Landmark trials (e.g., DAPA‑HF, EMPEROR‑Preserved, MASTER‑DAPT) with their PMIDs, DOIs, and key findings.
Source‑aware summarization with reduced hallucinations
Only after the evidence is collected and reranked do I send it to the LLM. The prompt makes it explicit that:- The model can only rely on the provided sources.
- Every important clinical statement should be backed by real citations.
- Citations must match actual PMIDs/DOIs and URLs from the evidence package.
- The model can only rely on the provided sources.
I added a citation validation layer that:
- Extracts PMIDs and DOIs from URLs.
- Rejects references that don’t map to real entries.
- Prevents the model from inventing references.
Stack and implementation details
- Frontend: Next.js, React, TypeScript, Tailwind CSS.
- Backend: Next.js API routes with a shared evidence engine in
lib/evidence/engine.ts. - Models: GPT‑4o for Doctor Mode, GPT‑4o‑mini for General Mode and vision.
- Observability: Integrated tracing to inspect queries, evidence selection, and model behavior over time.
- Frontend: Next.js, React, TypeScript, Tailwind CSS.
Observability and evaluation with Arize Phoenix
To make sure MedGuidance isn’t just “working” but actually selecting good evidence, I integrated Arize Phoenix as an observability layer. Every query goes through tracing so I can see:
- Which evidence sources were hit and what was returned
- How the BGE Cross‑Encoder scored and reranked documents
- Where the LLM might be over‑ or under‑using certain sources
This helps me spot failure cases (wrong guideline chosen, noisy trials, potential hallucinations) and iteratively improve the retrieval and prompt strategies instead of guessing.
Challenges I faced and accomplishments I’m proud of
Building MedGuidance AI as a student/solo developer came with several challenges:
Designing an effective reranking pipeline
Understanding how BGE Cross‑Encoder works in practice—score distributions, thresholds, and failure cases—was a major learning curve. I had to experiment with different strategies to ensure that the top results are truly clinically relevant, not just loosely related.Coordinating 57+ evidence sources
Managing latency, API limits, and token constraints while still returning rich evidence was difficult. I had to carefully design what each query fetches, how many results to keep from each source, and how to merge everything into a single coherent evidence bundle.Reducing hallucinations in a medical setting
Preventing hallucinated citations and incorrect guideline names required multiple layers: strict prompts, a citation whitelist, and URL‑based validation. Getting this right was critical for safety and trust.End‑to‑end system integration
Going from an idea to a working product meant building everything: the UI, the evidence engine, reranking logic, safety rules, and citation rendering. Getting the full pipeline running reliably—from query to evidence to summarized answer—was a milestone I’m proud of.
One of the most meaningful moments was asking my sister (a gynecologist) to test MedGuidance AI with real clinical questions. She cross‑checked the answers against her own reading and was genuinely impressed by how focused, cited, and usable the responses were. That validation from a real clinician was a big accomplishment for me.
What I learned
This project changed how I think about both AI and medicine:
- There is a real demand for trustworthy health information—not just from patients, but especially from clinicians who are overwhelmed by the volume of literature.
- I better understand the pain points of Indian health professionals: time pressure, burnout, and the constant need to reconcile multiple guidelines and trials.
- I learned how to move beyond “just calling an LLM” to designing a retrieval‑augmented system where:
- The LLM is a careful summarizer, not an authority.
- Evidence quality and ranking matter as much as the model itself.
- Safety (citations, crisis detection, clear disclaimers) is built into the architecture.
- The LLM is a careful summarizer, not an authority.
What’s next for MedGuidance AI
Over the next 8 months, my goal is to evolve MedGuidance AI into a more robust, India‑focused assistant for health professionals and medical students:
Make the system more robust for real‑world use
Improve the evidence engine, reranking, and prompt design based on real queries so responses stay reliable across different specialties and edge cases.Test with more clinicians and medical students
Work with multiple doctors and medical students in India to run MedGuidance AI against real clinical questions, collect structured feedback, and refine the system around their workflows.Move towards a medical LLM ecosystem for India
Use the lessons from this project to gradually build a dedicated medical LLM stack tailored to Indian clinicians and students—with localized guidelines, exam‑oriented study tools, and workflows that support both education and clinical decision support.
The long‑term vision is clear: help clinicians and students in India go from question → curated evidence → trustworthy summary in a few seconds, while keeping the human professional firmly in control.
Built With
- arize-ai
- bge-cross?encoder
- clinicaltrials.gov
- cochrane
- dailymed
- framer-motion
- gpt?4o?mini
- next.js-16
- openai-gpt?4o
- openalex
- openfda
- pubmed-api
- react-19
- redis-(optional)
- rxnorm
- semantic-scholar
- shadcn/ui
- tailwind-css-v4
- tavily-ai
- typescript


Log in or sign up for Devpost to join the conversation.