-
-
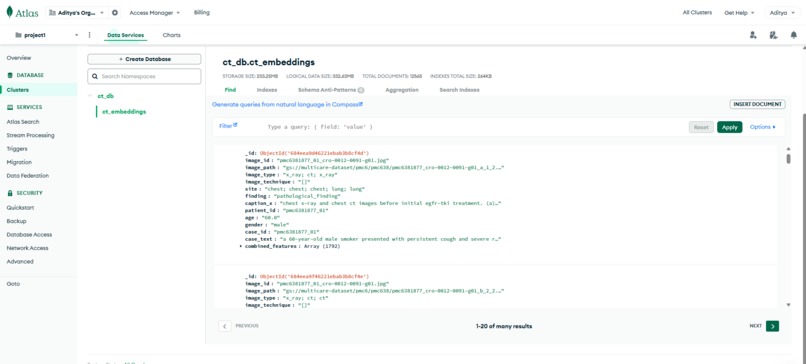
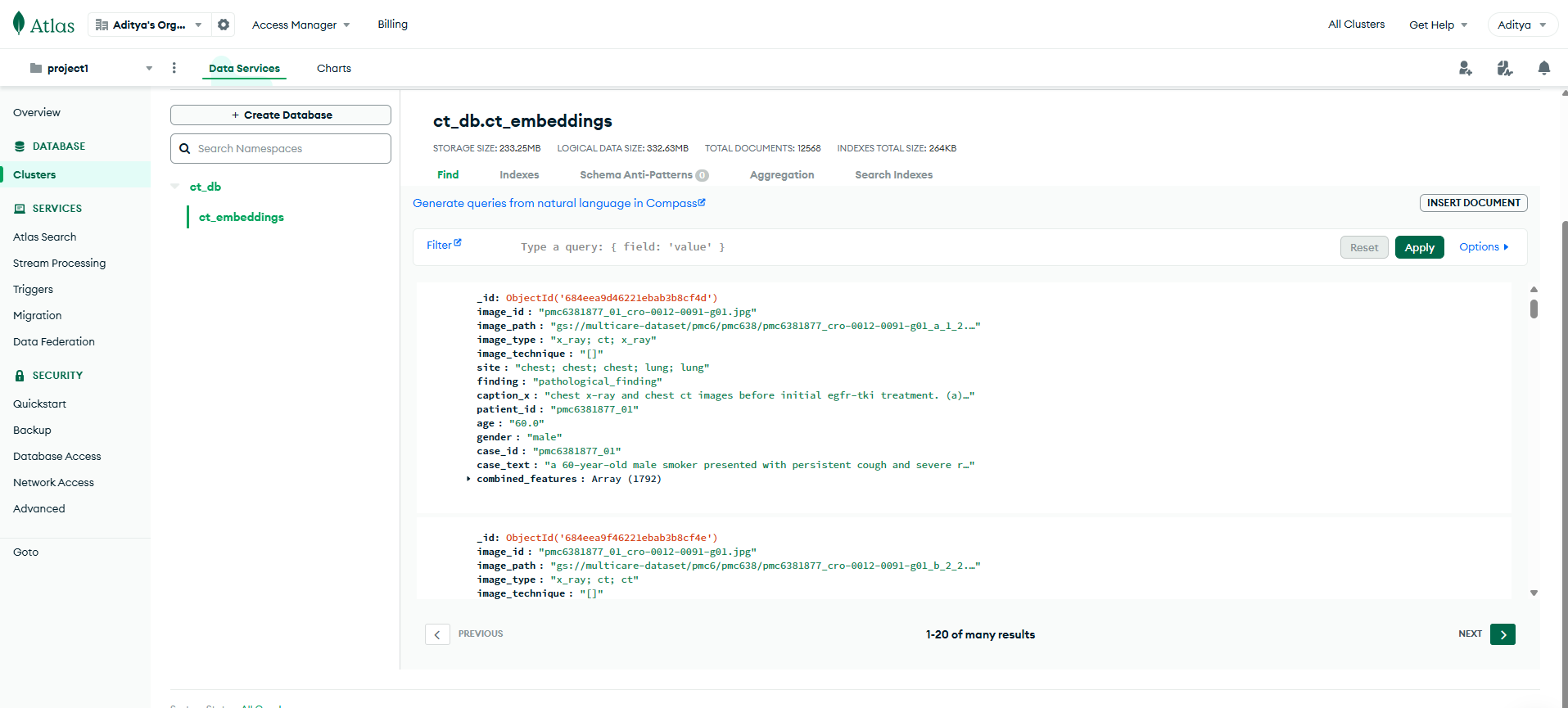
MongoDB Atlas Documents
-
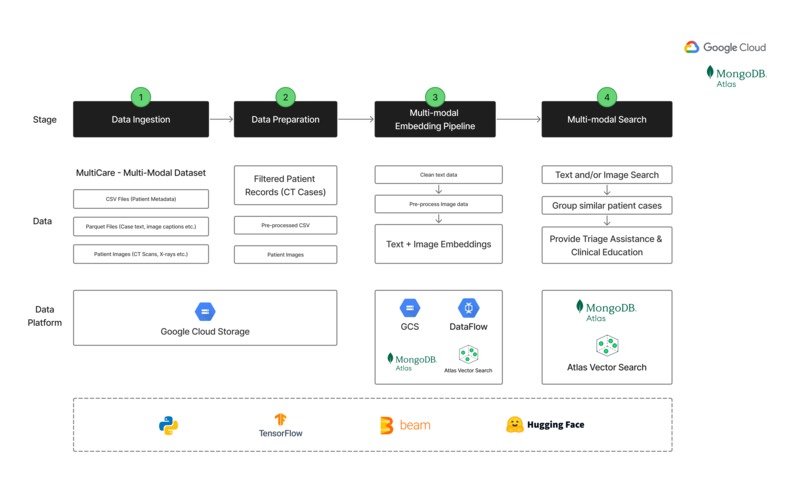
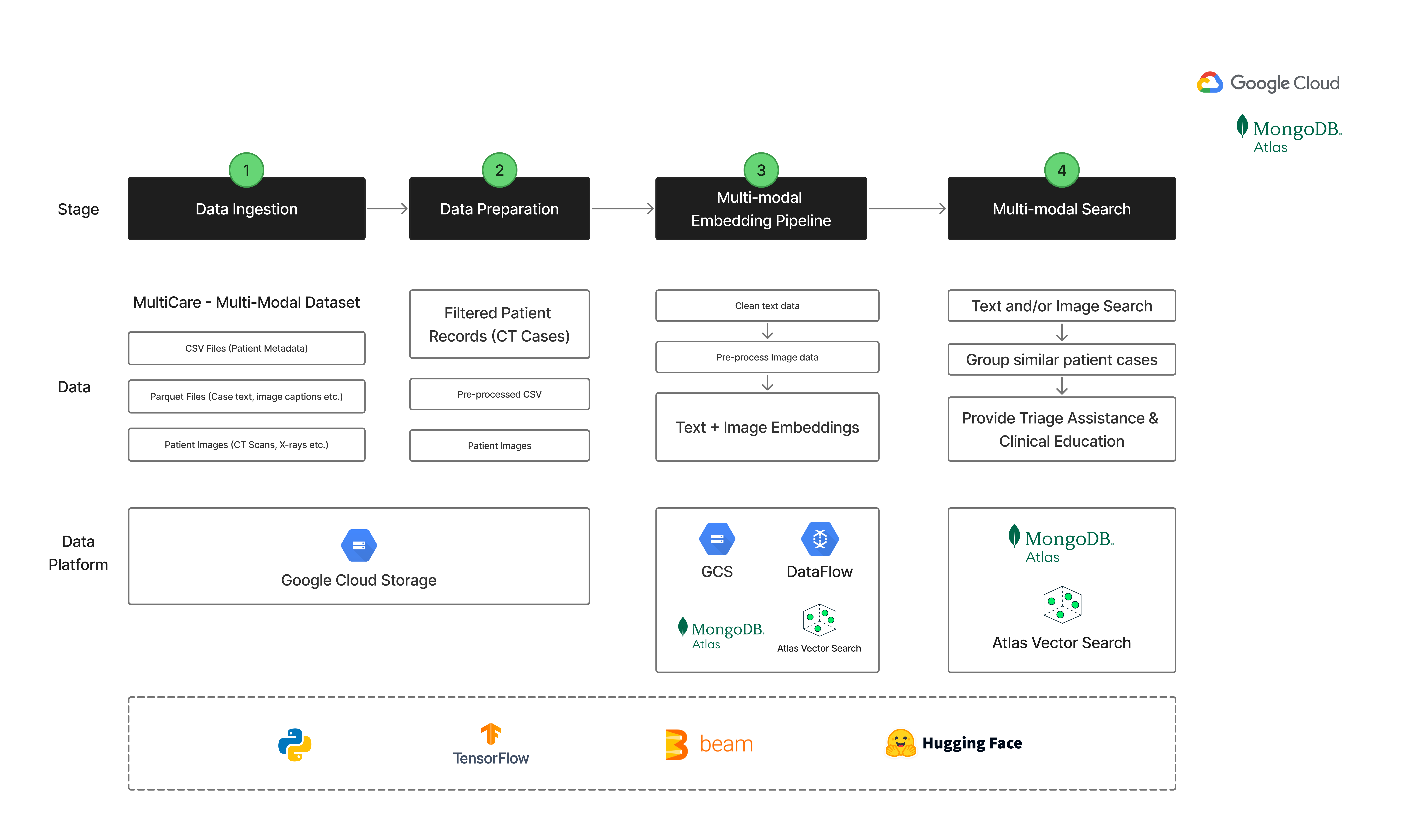
Architecture Diagram for MedFuse
-
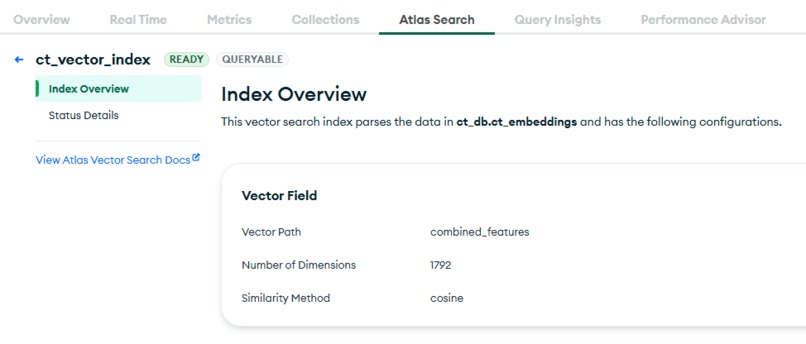
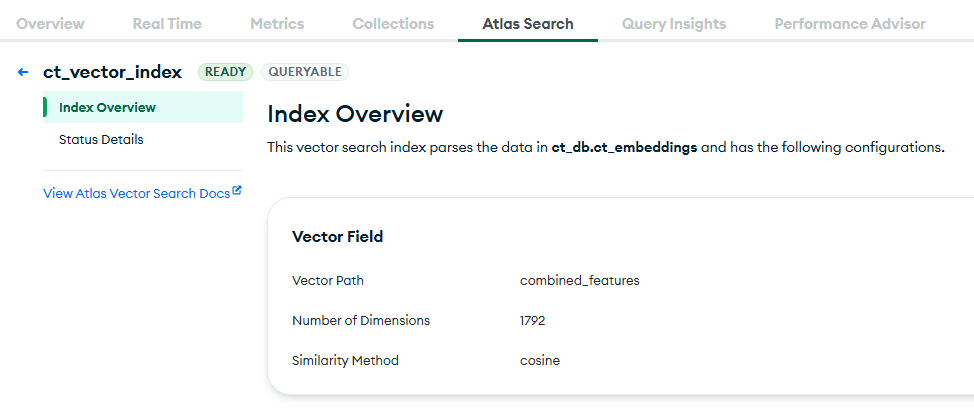
MongoDB Atlas Vector Search
Inspiration: Triage Assistance, Diagnostic Ease & Staff Training
- In clinical settings, time is critical—yet clinicians often struggle with scattered, multimodal patient data.
- It is challenging to process large medical images, analyze case history, and find relevant past cases quickly.
- Existing tools fail to scale with high-resolution images or unify image and text insights.
- This inspired us to build a system that can process, store, and retrieve insights from multimodal healthcare data—*helping clinicians make informed decisions faster.
What it does
- Processes and prepare CT scan cases from the MultiCare dataset, combining image and case-text metadata.
- ~10,000+ scans across diverse conditions
- Clinical descriptions from CSV + Parquet metadata
- Extracts multi-modal embeddings from both CT images and case descriptions using deep learning models.
- Stores multimodal embeddings in MongoDB Atlas with vector search for fast, scalable retrieval.
- Enables search of similar cases using image, text, or both—helpful for diagnostic reference, triage, & medical staff training.
- Runs on Google Cloud DataFlow, ensuring scalability.
How we built it
- Dataset: MultiCare dataset (images, metadata CSVs, and Parquet case descriptions).
- Preprocessed and filtered CT scan cases and aligned image paths with corresponding clinical text.
- Used Apache Beam on Google Cloud DataFlow to scale embedding generation across large data.
- Extracted:
- Image embeddings using DenseNet121
- Text embeddings using Bio_ClinicalBERT
- MongoDB Atlas & Vector Search - Stored ~15k multimodal embeddings with vector indexing.
- Developed a search interface to find similar cases by image, text, or both.
Challenges we ran into
- Handling large data across diverse file formats
- Processing high-resolution medical images at scale — needed distributed processing.
- Generating embeddings with large models (DenseNet, Bio_ClinicalBERT) in a scalable.
- Storing data in a non-redundant way
Accomplishments that we're proud of
- End-to-end scalable pipeline built using GCP DataFlow & MongoDB for large medical dataset.
- Successfully created and stored multimodal embeddings in MongoDB
- Efficient handling of large images
What we learned
- Designing for scale is critical
- User needs in clinical settings revolve around speed, interpretability, and access
- Combining ML models, cloud infra, and domain knowledge creates impactful healthcare tools
What's next for MedFuse
- Risk Scoring for Triage: Incorporate clinical rules to prioritize high-risk cases.
- Few-shot fine-tuning: Fine-tune embeddings and VLMs on specific clinical tasks for more precise retrieval and reporting.
- Structured report generation
- Imorove overall accuracy and performance



Log in or sign up for Devpost to join the conversation.