-
-
-
Our Architecture

MedExplain
Dual-Model Convergence for Explainable Clinical AI
The Problem
In the realm of healthcare, trust is paramount. While modern AI systems have achieved remarkable accuracy in diagnosing diseases, they often fall short in explaining their reasoning. This lack of transparency breeds skepticism among clinicians who rely on clear, traceable reasoning to make informed decisions.
- Heatmaps (GradCAM, SHAP) show where a model looked.
- They do not show why a diagnosis was made.
- In clinical medicine, black-box decisions are unacceptable.
Radiologists need traceable reasoning, not just predictions.
Our Solution
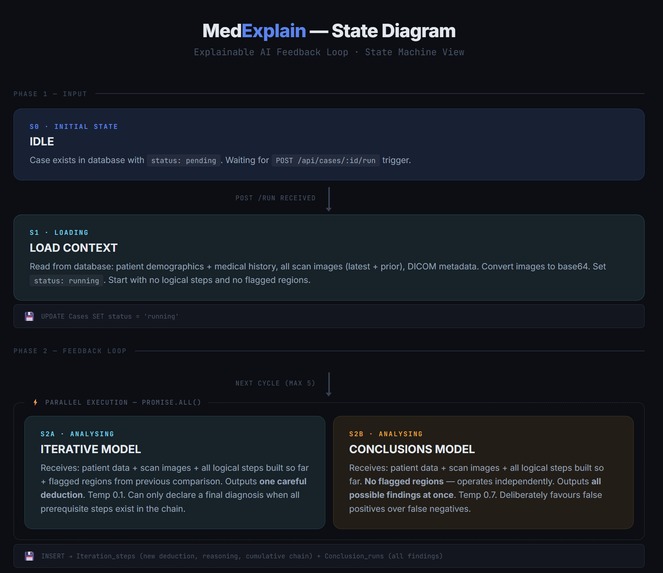
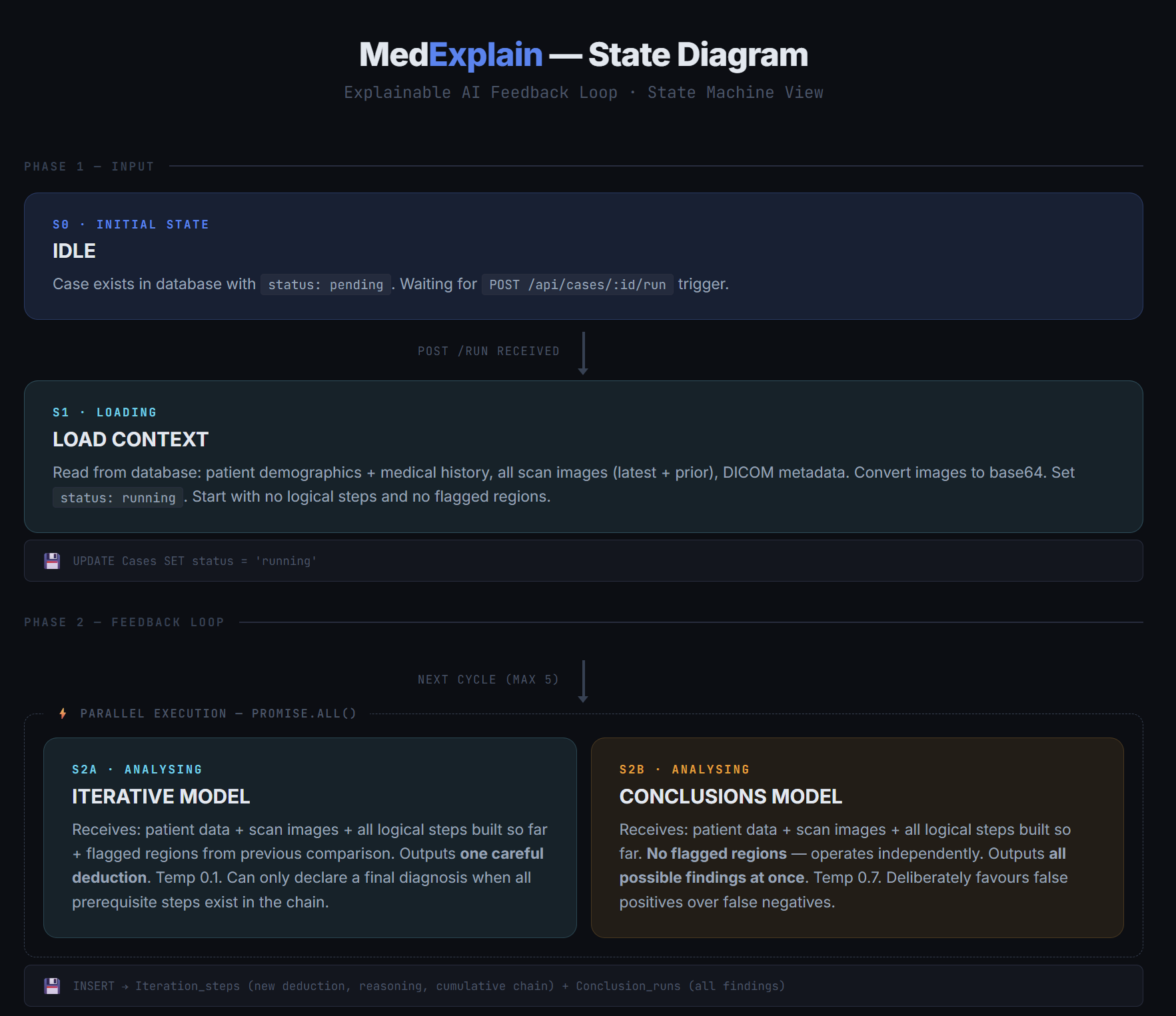
We built a clinical AI system powered by a Dual-Model Convergence Loop.
Instead of trusting one model:
- We run two independent reasoning strategies in parallel.
- A deterministic comparison model evaluates agreement.
- A diagnosis is accepted only if both strategies independently converge.
If they disagree, the system flags the case for human review.
Explainability is not added afterward — it is built into the reasoning process itself.
The Dual-Model Convergence Loop
Conclusions Model (Aggressive Strategy)
- Temperature: 0.7
- Casts a wide diagnostic net
- Prefers false positives over false negatives
- Immediately proposes all possible findings
Outputs for each finding:
- Diagnosis
- Severity level
- Confidence score
- Anatomical region
- Bounding box coordinates
This model behaves like an assertive specialist proposing differential diagnoses.
Iterative Model (Cautious Strategy)
- Temperature: 0.1
- Makes exactly one logical deduction per cycle
- Cannot jump to conclusions
- Cannot declare FINAL without full prerequisite reasoning
Formal reasoning constraint:
Dₙ = f(D₀ ∪ {d₁, d₂, …, dₙ₋₁} ∪ Fₙ₋₁)
Where:
- D₀ = patient records + imaging + clinical references
- dᵢ = prior deductions
- Fₙ₋₁ = flagged disagreement regions
Each step must:
- Reference patient data
- Reference imaging findings
- Reference clinical guidelines
The reasoning chain itself becomes the explanation.
Comparison Model (Deterministic Validator)
- Temperature: 0.0
- Performs semantic matching between model outputs
- Identifies agreement vs disagreement
- Extracts bounding boxes of mismatched findings
If disagreement exists:
- Flagged regions are fed back into the next reasoning cycle
- The system forces re-evaluation
The loop runs for up to 5 cycles.
Convergence Rule
The system converges when:
- Every aggressive conclusion has independent confirmation
- Semantic similarity exceeds threshold
- Iterative model declares FINAL
If convergence fails after 5 cycles:
status = human_review
Uncertainty is explicitly surfaced.
Honest doubt is safer than false confidence.
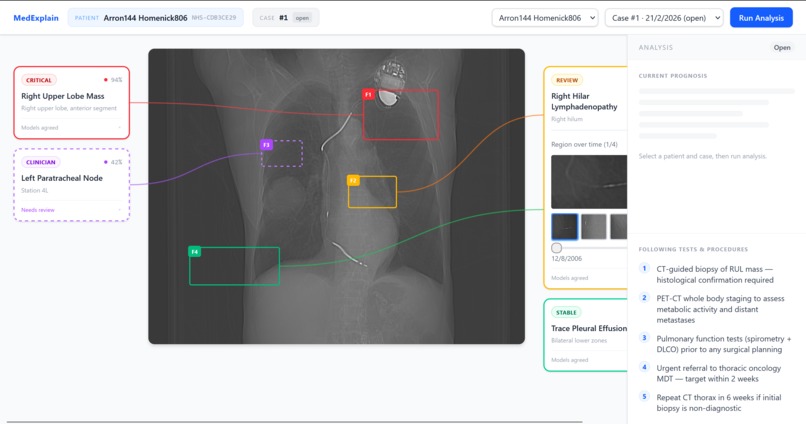
What the System Provides
- Multi-timepoint scan viewer
- Color-coded bounding boxes (severity based)
- Structured diagnosis & prognosis panel
- Suggested next steps
- Full reasoning chain (step-by-step)
- Downloadable CSV audit trail (regulatory-ready)
How We Built It
Backend
- Node.js + Express
- js.sqlite
- Anthropic SDK (Claude Sonnet)
- Structured JSON outputs
- Temperature-controlled role prompts
Data Layer
- FHIR R4 synthetic patient records (Synthea)
- DICOM imaging from TCIA
- Python pipeline for:
- Hounsfield Unit rescaling
- Window/level normalization
- DICOM-to-PNG conversion
- Hounsfield Unit rescaling
Database Schema
- Patient
- Cases (pending → running → converged / human_review)
- Scans (multi-timepoint support)
- Iteration_steps
- Conclusion_runs
Every reasoning step is stored.
Explainability is structurally embedded into the database.
Why This Is Different
Most explainable AI:
- Adds heatmaps
- Adds SHAP values
- Explains where the model looked
MedExplain:
- Explains how the model reasoned
- Forces independent agreement
- Surfaces disagreement transparently
- Stores a full audit trail
We do not trust one model to be right.
We require independent convergence between the conclusions model for breadth and the itertive model for depth.
From Explainable AI to Autonomous Clinical Agent
MedExplain is not just a reasoning framework.
It is an autonomous radiology reasoning agent.
Given:
- A FHIR patient record
- A DICOM scan
It independently:
- Performs structured diagnostic reasoning
- Validates itself through convergence
- Flags high-risk anatomical regions
- Generates a structured preliminary report
- Escalates only when uncertainty remains
This completes a meaningful clinical task end-to-end.
Proving Agent Value
Because the system runs as a loop with structured state, we can measure:
- Time to convergence per case
- Number of reasoning cycles required
- Escalation rate to human review
- High-severity findings flagged
- Token usage per diagnostic run
- Cost per case
This enables:
- Cost-per-diagnostic modeling
- Time-saved estimates for preliminary reporting
- Reduction in unnecessary escalations
- Clear ROI per deployment
MedExplain is not a seat-based tool.
It is a task-based autonomous agent.
Value is measured per diagnostic case.
Economic Model
Hospitals do not buy seats for agents.
They deploy agents to complete workflows.
MedExplain can operate under:
- Per-case billing
- Severity-tier billing
- Escalation-based pricing
- Convergence-efficiency pricing
Because every reasoning cycle and token is logged, agent economics are transparent and auditable.
The system can integrate with agent cost observability platforms to track:
- Latency
- Cost
- Accuracy
- Escalation rate
- Convergence efficiency
This aligns directly with agent-based pricing infrastructure.
What We Learned
- Prompt engineering defines agent behavior.
- Explainability must be architectural.
- Independent convergence improves reliability.
- AI agents must expose uncertainty.
- Agent value must be measurable per task, not per user.
What’s Next
- Clinical validation studies
- Integration with hospital EHR systems
- Multi-modality imaging expansion
- Specialized medical vision models
- Deployment-ready observability layer
- Alignment with AI regulatory frameworks
Closing Statement
MedExplain transforms medical AI from a black-box predictor into an autonomous, accountable reasoning agent.
Two models. Independent strategies. Converged conclusions.
Explainable by architecture.
Valuable by measurement.




Log in or sign up for Devpost to join the conversation.