Building a Privacy-First AI Hospital Dashboard
What Inspired Us
Hospitals generate enormous amounts of data every day: clinical notes, lab reports, prescriptions, measurements, discharge summaries. Yet most of it remains unstructured and underused. Doctors spend hours documenting instead of treating. At the same time, AI is advancing rapidly, but very little of it is usable inside real hospitals because of privacy constraints.
We kept coming back to one core question: why is powerful AI available everywhere except where decisions matter most?
The answer is privacy. Medical data cannot simply be sent to external APIs or cloud models. Regulations are strict, and rightfully so. But that should not mean hospitals are excluded from technological progress.
We wanted to build something that runs completely locally, keeps all patient data inside hospital infrastructure, supports doctors instead of replacing them, provides uncertainty rather than blind predictions, and structures messy medical data into something actually usable. That idea became our project.
Simulating and Structuring Clinical Data
Since we could not use real hospital data, we generated synthetic but clinically realistic patient populations using Synthea. It provides structured CSV files alongside unstructured clinical documents such as encounter summaries and discharge reports, which was perfect for us because it mirrors reality: hospitals have both structured records and messy narrative text.
Generating the data was the easy part. Transforming it into a dataset suitable for machine learning was not.
We generated large synthetic patient cohorts, parsed structured CSV data covering demographics, vitals, and diagnoses, extracted information from unstructured text documents, and mapped symptoms, lab values, medications, and diagnoses into feature vectors to build clean tabular datasets for classification.
Conceptually, we constructed:
$$X = [\text{age}, \text{blood pressure}, \text{heart rate}, \text{lab values}, \text{symptoms}, \dots]$$
$$y = \text{diagnosis}$$
Parsing the text documents was one of the most instructive parts of the project. Clinical language is messy. Important information is buried inside narrative paragraphs, and turning that into structured features required careful preprocessing and a lot of validation. It gave us a real appreciation for how much hidden complexity exists inside hospital data systems.
How We Built the System
We built a full hospital workflow dashboard, not just a model.
Frontend
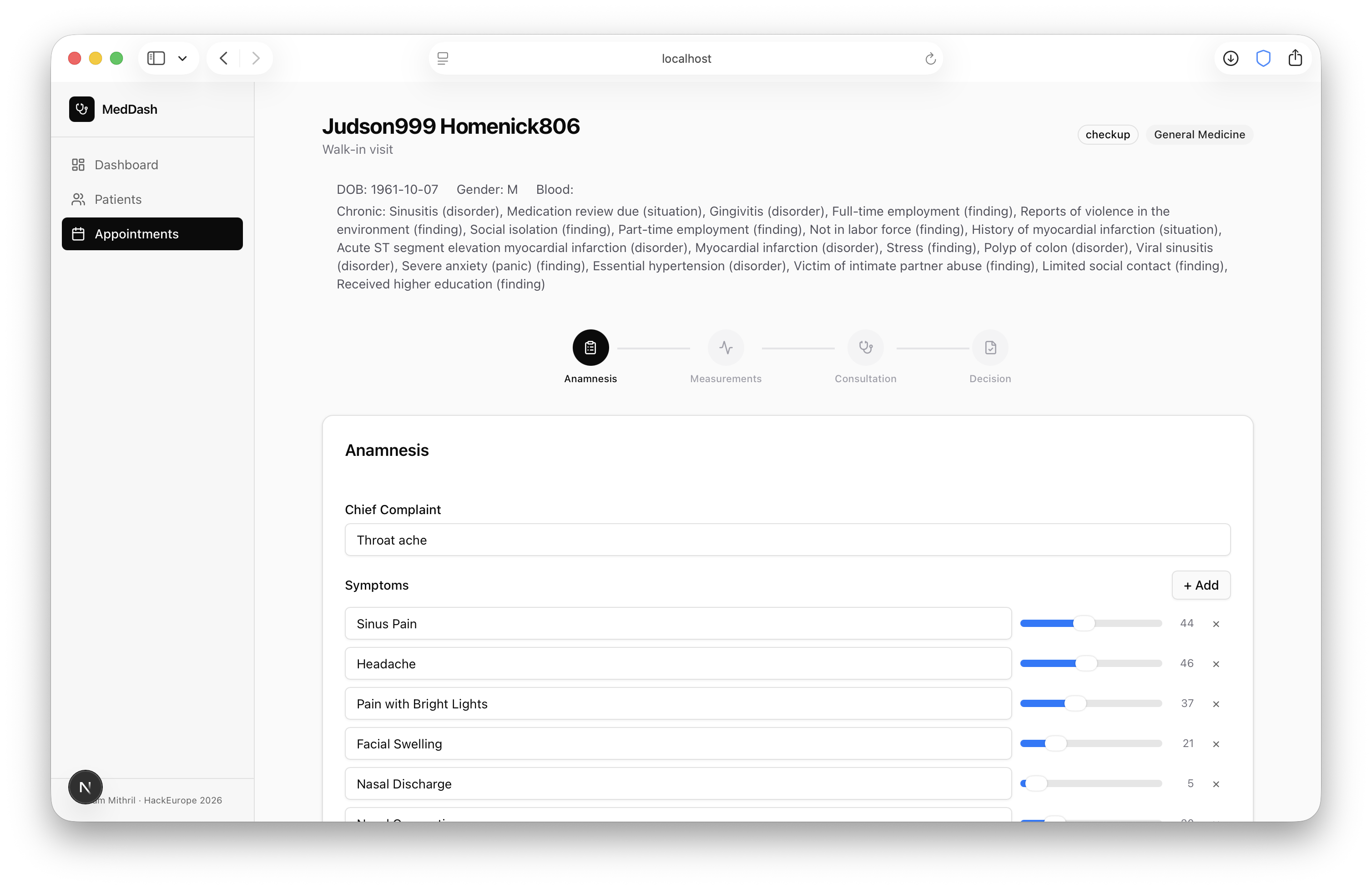
The interface is built with Next.js, React, Tailwind CSS, and shadcn/ui. It follows the real hospital pipeline: patient search and check-in, anamnesis, measurements, consultation, diagnosis support, medication decisions, and final outcome.
We focused on minimalism throughout. Doctors should not feel like they are using an AI experiment. It should feel like a clean, familiar hospital system that happens to have helpful assistance panels alongside it.
Backend
The backend is built with Python and FastAPI, exposing endpoints for LLM-based summarization, tabular prediction, medication compatibility checks, and patient data storage. Everything is designed to run locally within hospital infrastructure.
Why We Combined an LLM and a Tabular Model
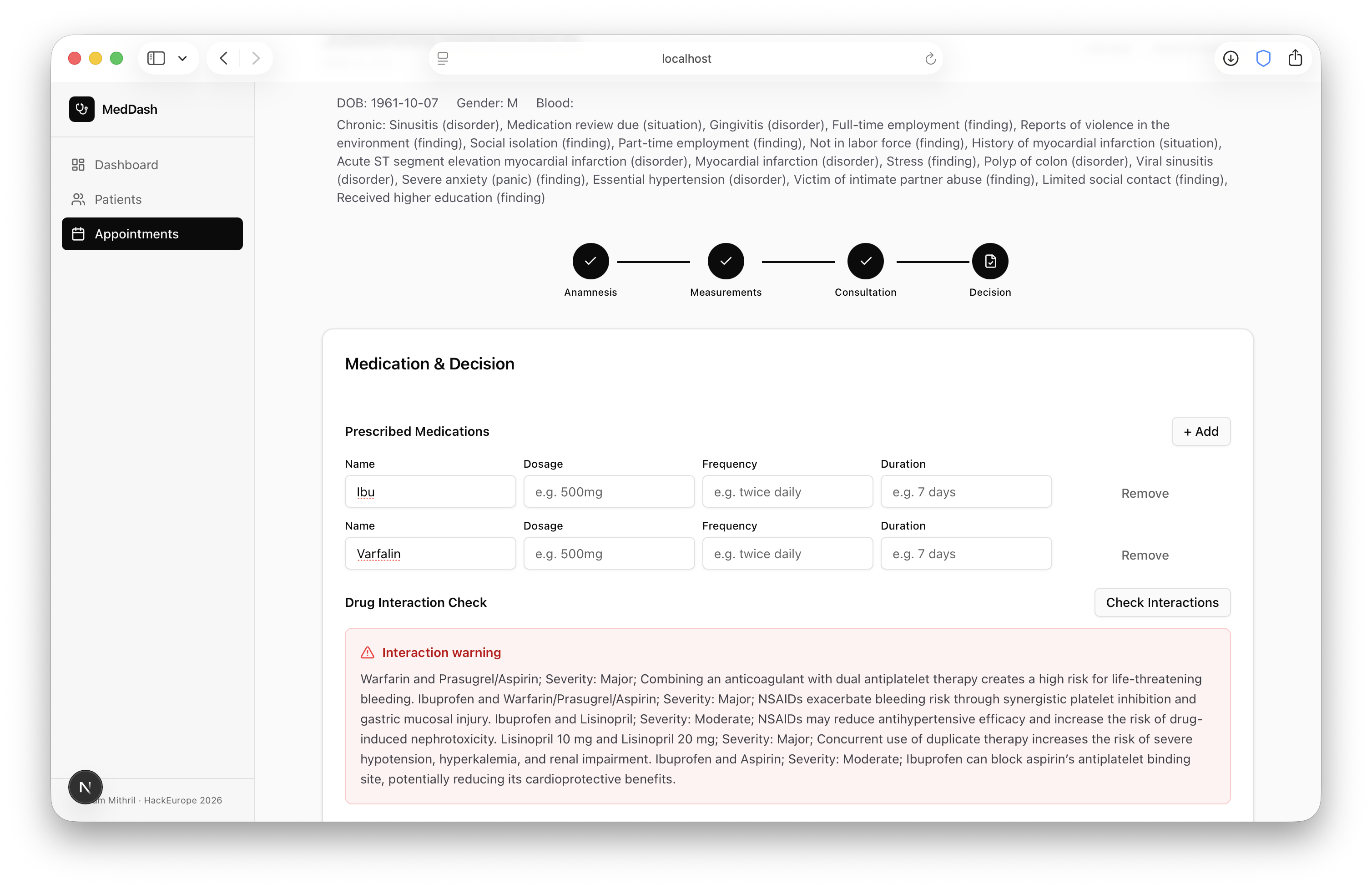
We realized early on that LLMs, as impressive as they are, are not reliable enough to use alone in a healthcare context. They are good at summarizing notes, structuring text, and answering contextual questions. But they can also hallucinate, and in medicine that is not an acceptable risk.
So we separated responsibilities clearly.
The medical LLM handles unstructured reasoning: summarizing patient history, extracting structured information from notes, flagging potential medication conflicts, and answering doctor queries. It is advisory only. The doctor always edits and decides.
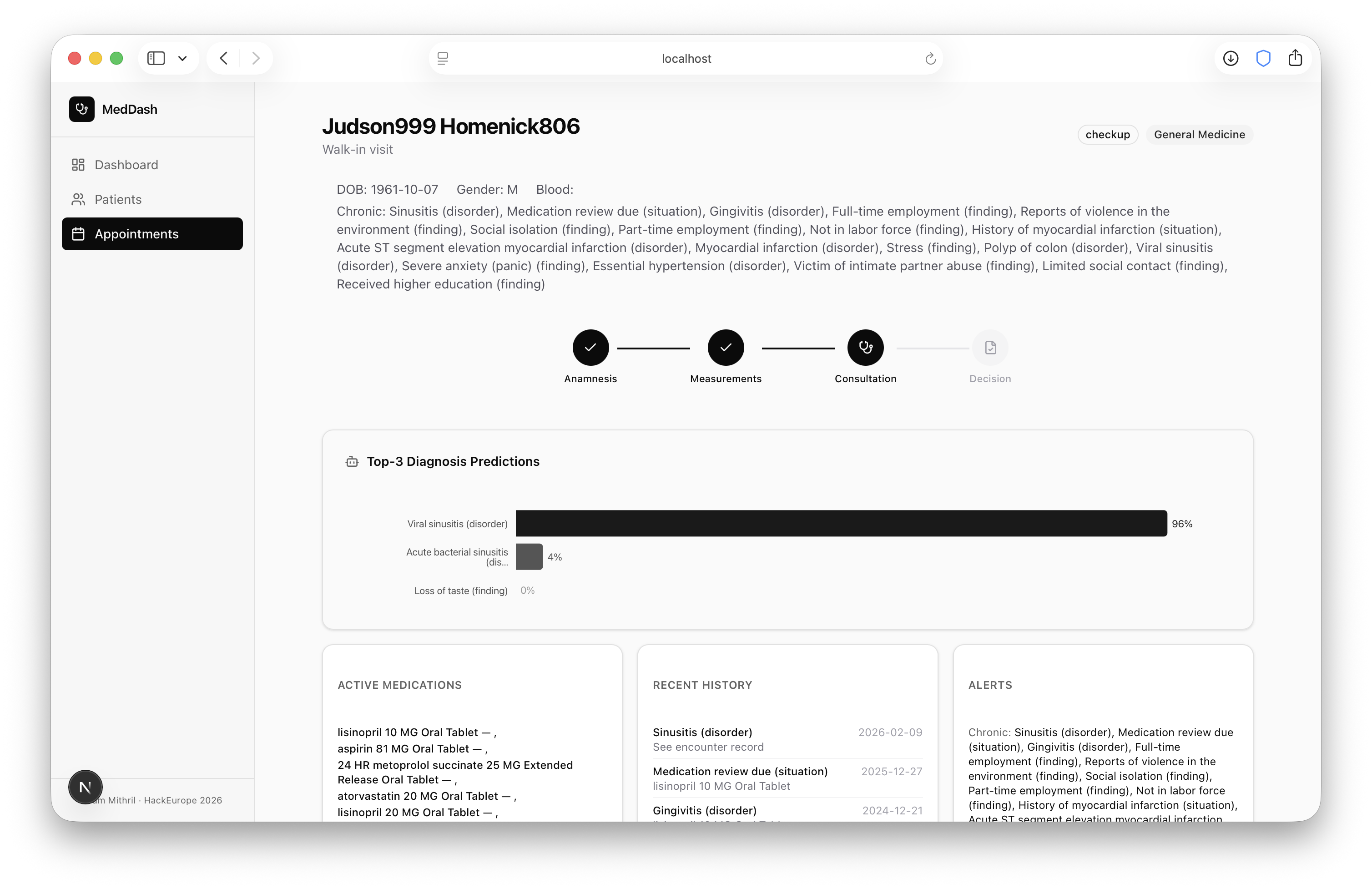
For diagnosis support, we use TabPFN, a foundation model for tabular classification. Traditional machine learning requires you to choose a model, tune hyperparameters, retrain, validate, and repeat. TabPFN works differently. It was pretrained on millions of synthetic tasks and can immediately perform strong classification on structured tabular data without retraining. Instead of optimizing:
$$\theta^* = \arg\max_{\theta} p(D \mid \theta)$$
it approximates the predictive posterior directly:
$$p(y \mid x, D)$$
This mattered for us because hospitals often have small datasets, limited training infrastructure, and everything has to run locally. TabPFN fits that reality well.
The model outputs probabilities using softmax:
$$\text{softmax}(z_i) = \frac{e^{z_i}}{\sum_j e^{z_j}}$$
So rather than predicting a single diagnosis, it provides confidence alongside it. That distinction matters enormously. A prediction without uncertainty in healthcare is not just unhelpful, it is actively dangerous. We would rather show the doctor both a prediction and the model's confidence in that prediction than hand them a label with false certainty.
What We Learned
The biggest surprise was how much harder data cleaning was than modeling. Generating synthetic patients was straightforward. Converting raw clinical documents into meaningful structured datasets consumed far more time and effort than we expected. It reinforced something that is easy to underestimate: real-world AI systems are mostly data engineering.
We also learned to treat uncertainty as a first-class citizen rather than an afterthought. In many ML demos, a model outputs a class and the demo moves on. In healthcare, that approach is not acceptable. If the model is unsure, the doctor needs to know that.
Designing for local-only execution was genuinely constraining, but in a productive way. We could not assume cloud GPUs. We had to assume a decent but ordinary hospital workstation, and that forced us to think carefully about model size, compute efficiency, and deployment simplicity. The constraint made the system more realistic.
Finally, we were constantly aware of the risk of overreliance. The UI deliberately avoids making AI outputs feel dominant or authoritative. The system assists. It does not decide.
Challenges We Faced
Parsing and aligning structured and unstructured synthetic data was harder than expected. Designing a workflow that genuinely mirrors real hospital processes required iteration. Integrating two fundamentally different AI systems coherently took careful thought. And throughout all of it, we were aware that healthcare is high stakes territory where mistakes are not theoretical.
That awareness pushed us beyond accuracy metrics and toward questions of usability, trust, and safety, which we think is where healthcare AI needs to spend more of its time.
Where This Can Go
As more structured data is collected over time, diagnostic performance improves, outcome tracking becomes possible, medication safety increases, and epidemiological trends become visible. Because everything runs locally, hospitals can improve their models without ever exporting sensitive data.
The long-term vision is straightforward: make hospital data usable, keep it private, show uncertainty, and support doctors. Nothing more, nothing less.
Built With
- fastapi
- gemini
- medgemma
- node.js
- python
- react
- sqlalchemy

Log in or sign up for Devpost to join the conversation.