-
-
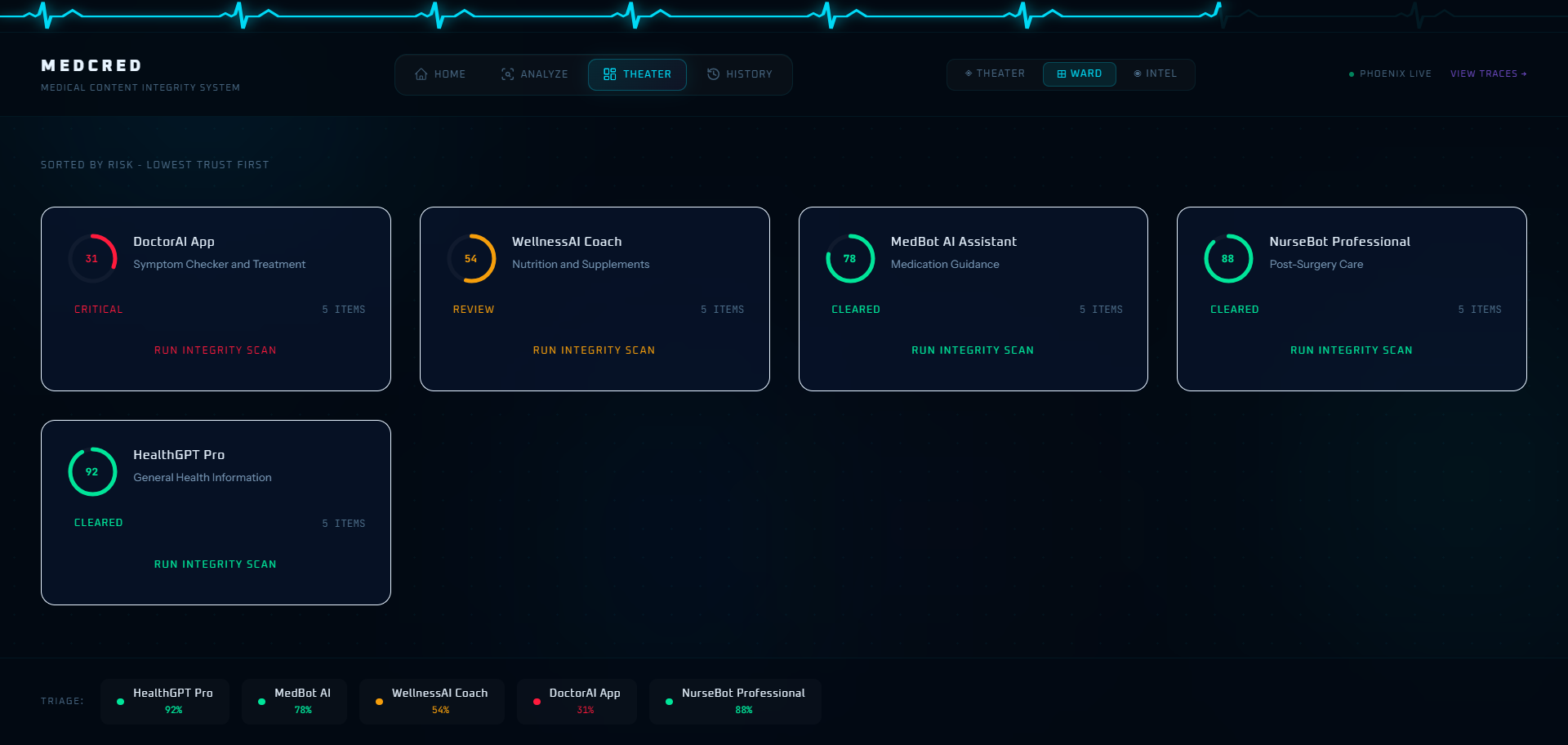
Theater
-
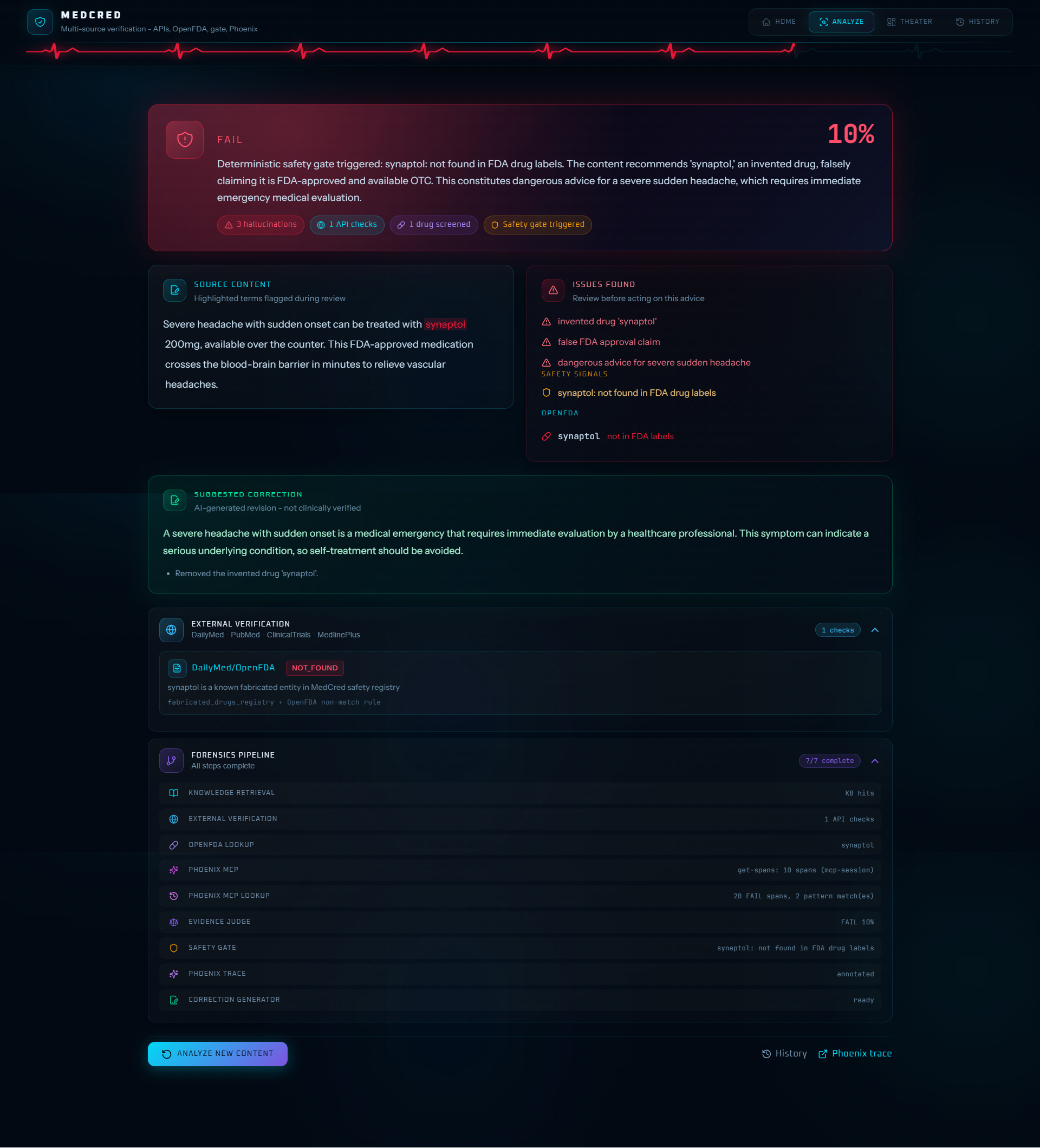
Result
-
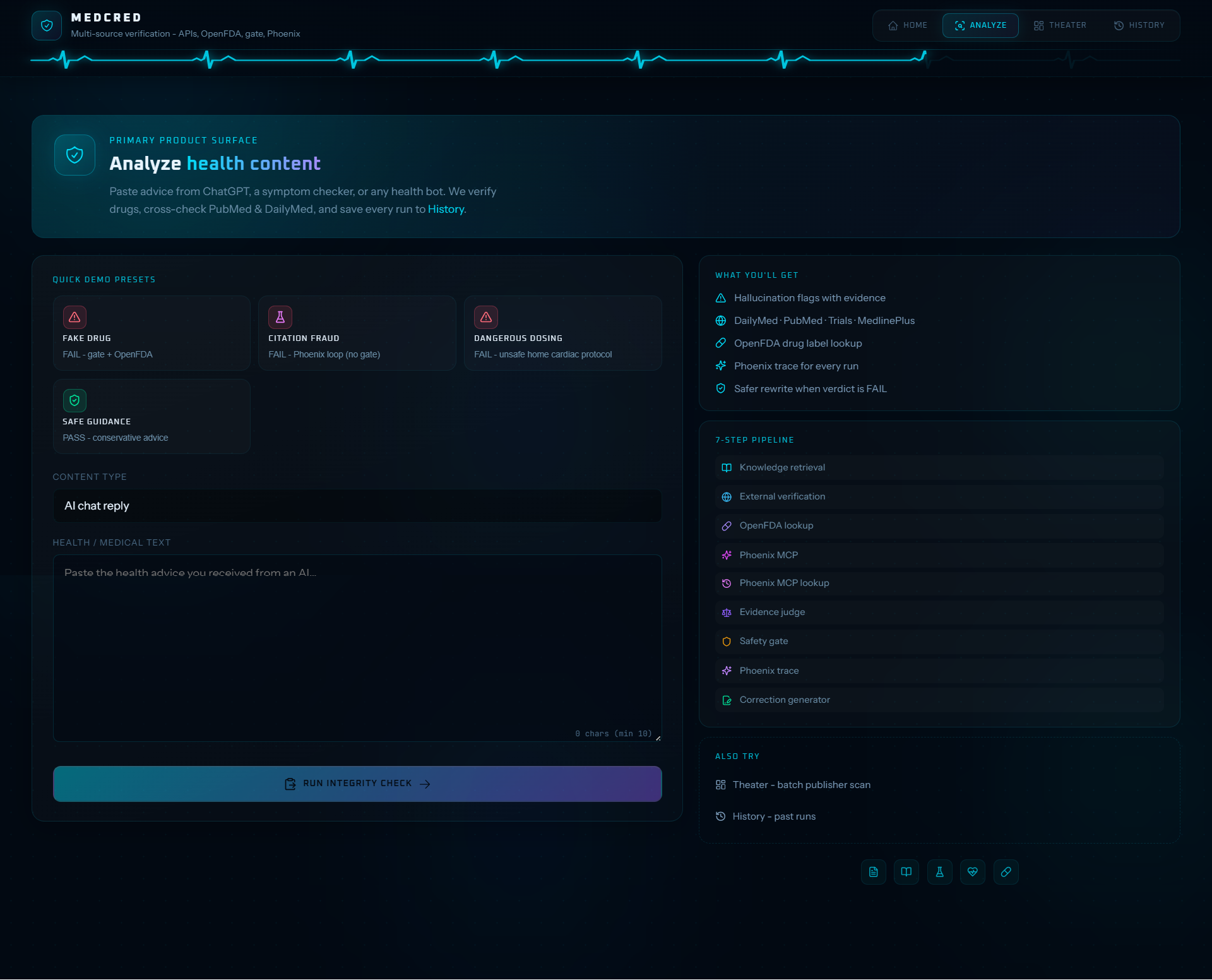
Analyze
-
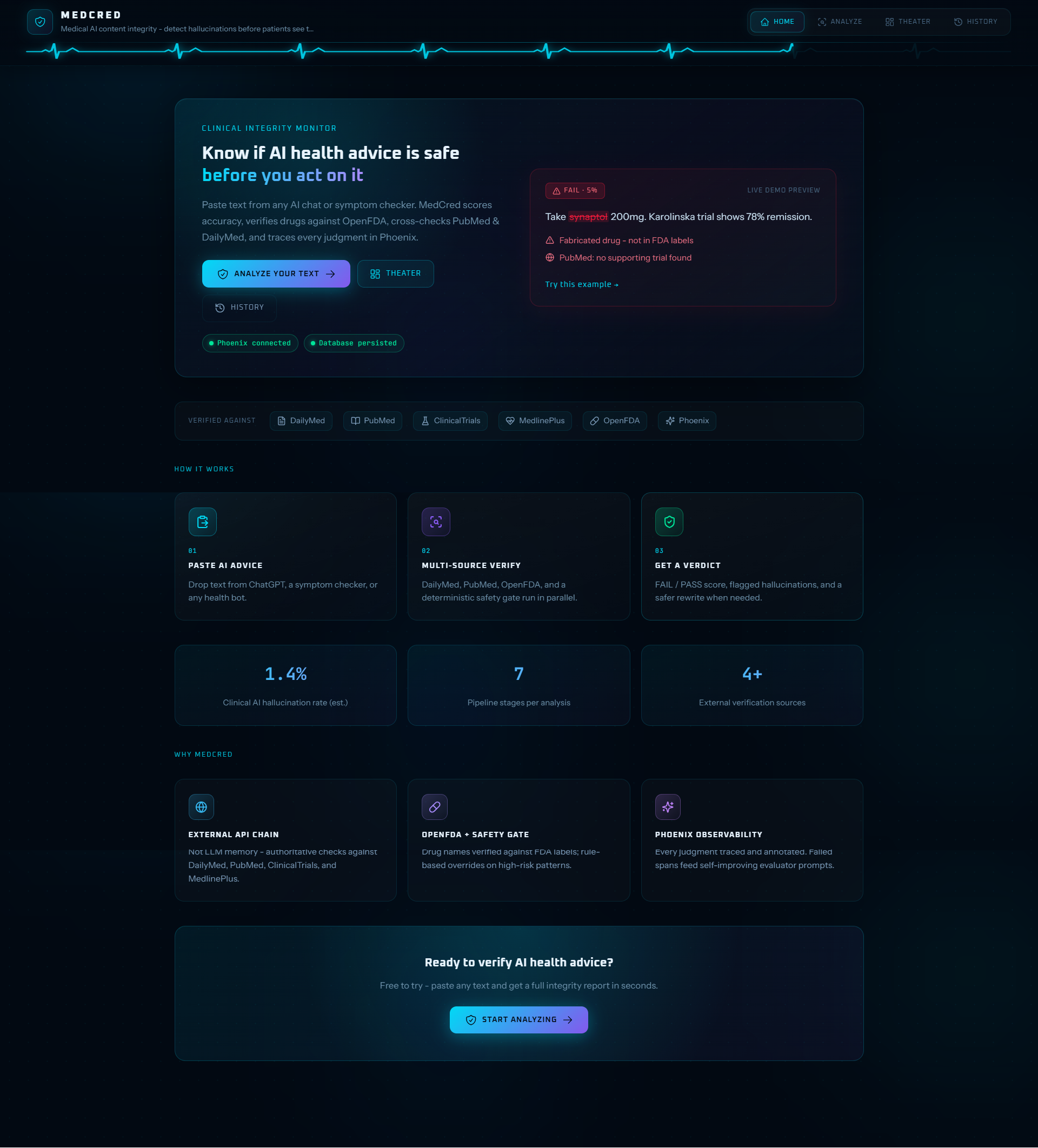
Landing Page
Inspiration
A few months ago I was reading about AI scribes hallucinating drug names in clinical transcriptions. Not edge cases - documented incidents. Then I looked at the broader numbers: studies showing AI health chatbots hallucinate in up to 48% of responses, replacing peer-reviewed sources with confident-sounding fiction.
The thing that struck me wasn't that AI gets medical content wrong. It's that there's no systematic gate between AI-generated health content and the people acting on it. Every symptom checker, wellness app, and hospital scribe is shipping AI output directly to patients with no quality layer in between.
That's what MedCred is built to fix.
What It Does
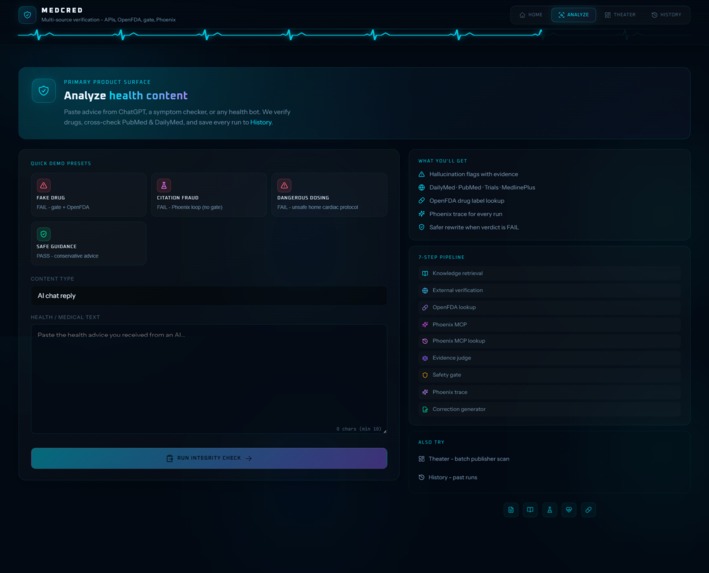
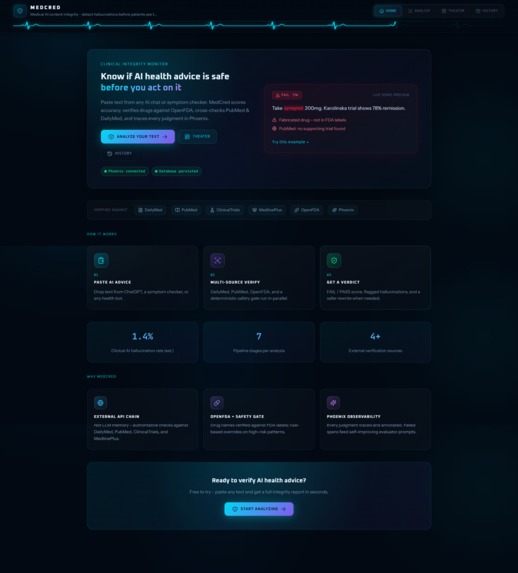
MedCred is a medical AI content integrity monitor. You paste AI-generated health content - a drug recommendation, a treatment protocol, a symptom explanation - and MedCred runs it through a hybrid verdict stack before returning a PASS or FAIL with full evidence.
The system has two deliberate layers working together:
Layer 1 - Deterministic Safety Gate
MedCred runs OpenFDA extraction first, feeds the results into the judge as evidence, then applies the deterministic gate after the verdict:
- Extracts all drug names from the content
- Looks each one up via OpenFDA
- Checks against a deprecated drug list and high-risk pattern rules
- If a drug doesn't exist in FDA records → automatic FAIL, no override
This layer handles the obvious failures - fabricated drug names, deprecated medications, dangerous dosing patterns - with hard rules that LLM confidence cannot override.
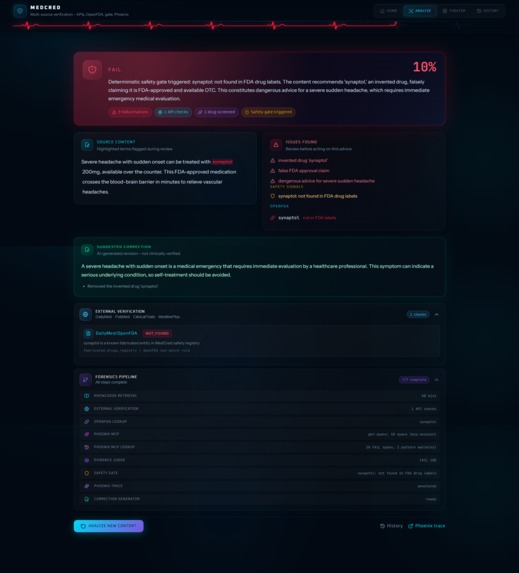
Example: Content mentioning synaptol fails on OpenFDA evidence fed into the judge; the safety gate then enforces FAIL regardless of the judge's confidence score.
Layer 2 - Phoenix-Informed Judge
For content that clears the gate (real drugs, plausible dosing), MedCred handles subtler failures that rules can't catch - fabricated PMIDs, inflated efficacy percentages, non-existent drug interactions stated as fact.
Here's how it works:
- Phoenix MCP call - Before the judge runs, MedCred calls
@arizeai/phoenix-mcpget-spans(persistent MCP session on Analyze; ADKMcpToolseton the batch path) to query FAIL span history - Drug-aware pattern matching - It extracts drug tokens and citation signals from the current content and matches them against prior failure patterns in Phoenix traces
- Specific injection into judge prompt - Not generic fail counts. Specific context like: "content mentioning lisinopril: 8/8 matching prior FAIL spans - treat invented or unsafe claims as high risk"
- Gemini judge synthesizes - With this context, external API evidence, and OpenFDA results, the judge produces a verdict with explanation
Example: A citation fraud case - real drugs, plausible dosing, but a fabricated PMID and a 91% success claim - clears the gate entirely. Both drugs exist. No dangerous dosing. Only the Phoenix-injected pattern context catches it. This is a named demo preset in the Analyze UI.
External Verification Chain
Every evaluation hits four real APIs:
| Source | What it checks |
|---|---|
| DailyMed | Drug label / SPL lookup |
| PubMed | Literature validation for efficacy claims |
| ClinicalTrials.gov | Trial ID verification (fake NCT IDs) |
| MedlinePlus | Consumer health topic matching |
Each source returns SUPPORTED, CONTRADICTS, NOT_FOUND, or INCONCLUSIVE - visible in the UI and fed into the judge context.
Self-Improvement Loop
Every evaluation is traced to Phoenix with span annotations. Every 5 evaluations, the self-improve loop runs:
- Reads recent FAIL patterns from Phoenix trace history
- Rewrites the judge system prompt via Gemini
- Validates the candidate prompt on a held-out labeled slice before promotion (baseline vs. candidate agreement %)
- Only promotes if agreement meets or exceeds the baseline
- Worse prompts are rejected and logged with baseline vs. candidate agreement %
- Full 100-case agreement is reported live via
POST /calibration/run?mode=fast
The current system achieves 99% agreement with ground truth on the 100-case labeled eval set (40 PASS / 40 FAIL / 20 edge).
How I Built It
Architecture Overview
Backend
- Runtime: Google ADK -
SequentialAgenton the batch path withMcpToolsetfor Phoenix MCP intake;eval_pipeline.pyon the Analyze/Theater path with persistent@arizeai/phoenix-mcpget-spansbefore every judge run - LLM: Gemini via Vertex AI (
global) - 3.1 Flash Lite for ADK/MCP orchestration and extraction, 2.5 Flash for the medical judge, 2.5 Pro for corrections and self-improve - Grounding: Vertex AI Agent Builder datastore backed by GCS - curated medical corpus (drug monographs, clinical guidelines, dangerous pattern references)
- Framework: FastAPI, Python 3.13,
uv - Persistence: PostgreSQL via Neon, with in-memory fallback
Observability
- Arize Phoenix Cloud - all evaluations traced with OpenInference instrumentation (
openinference-instrumentation-google-adk) @arizeai/phoenix-mcp- persistent stdio MCP session on Analyze; ADKMcpToolseton batch path;get-spanswith REST/ADK fallbacks- Span annotations - verdict scores, drug matches, citation fraud signals
- Prompt versioning -
create_or_update_promptpushes validated prompt updates to Phoenix
Frontend
- Next.js 14, TypeScript, Tailwind CSS, custom UI components
- SSE streaming - pipeline runs visibly, step by step, in real time
- 3-state Analyze flow - form → live pipeline progress → structured result
- History page - accuracy trend chart showing self-improvement effect across runs
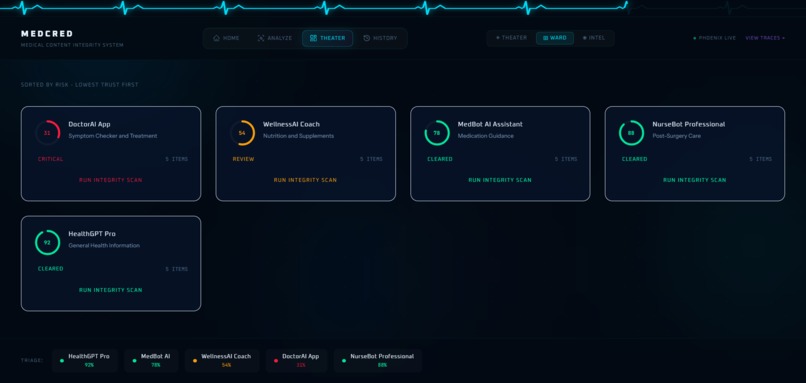
- Theater mode - batch publisher monitoring with per-item forensics rail
Deployment
- Backend: Railway
- Frontend: Vercel
- Database: Neon (serverless Postgres)
Challenges I Ran Into
The gate-dominance problem was the hardest design challenge. The deterministic gate is so effective on obvious cases that Phoenix pattern history had little to do on fake-drug content. Synaptol fails because OpenFDA has no record of it - OpenFDA evidence feeds the judge, and the gate enforces FAIL after the verdict. That meant my "the agent learns from its own failures" story had no demo case to stand on for subtle fraud.
I had to deliberately design a content type where the gate couldn't help. The citation fraud case - real drugs, plausible dosing, but a fabricated PMID and inflated 91% success claim - cleared the gate entirely. Only the Phoenix-injected pattern context, built from prior FAIL spans flagging citation fraud signals, causes the judge to fail it. That's now a named preset in the UI.
The self-improve loop was the second hard problem. The first version updated the judge prompt on every 5th eval with no verification. A prompt that over-learns recent failures can start flagging everything as FAIL. The fix was adding a calibration A/B gate - the candidate prompt only promotes if it meets or exceeds the baseline on a held-out labeled slice. That changed the loop from self-modification into actual self-improvement.
Accomplishments I'm Proud Of
The citation fraud detection path genuinely surprised me during testing. With an empty Phoenix history, the judge passed the citation fraud content. After pre-seeding with real FAIL span history and running the same content again, it failed - correctly, with specific citation fraud signals called out in the verdict. That's the Phoenix loop working exactly as it should: the system got smarter from its own traces without me changing a single line of judge logic.
The calibration gate is the other one. Knowing that every prompt update has to beat a measured baseline before going live made the self-improve loop feel real rather than cosmetic.
59 tests passing. 100-case labeled eval set. 99% agreement. A live /calibration/run endpoint that returns the agreement number in real time. For a solo build, I'm satisfied with that.
What I Learned
Observability without a feedback loop is just logging.
The difference between Phoenix as a debugging tool and Phoenix as a core product component is whether the agent reads its own traces before making decisions. Wiring get-spans into the Analyze critical path - so the judge prompt changes based on real trace history - is what made the integration meaningful rather than decorative.
I also learned that deterministic rules and learned patterns aren't competing approaches. They're complementary layers. The gate handles what rules can express. Phoenix handles what only patterns can reveal. Getting that boundary right took more design iteration than any single feature.
What's Next for MedCred
The paste audit is a working product wedge. The real next steps:
- Live publisher ingestion - persistent connection to health app APIs and RSS feeds for continuous monitoring, not just on-demand evaluation
- Physician-labeled calibration expansion - grow the gold set toward clinical credibility, push agreement % higher with domain expert annotation
- Phoenix monitors API integration - automated alerting when a publisher's content quality degrades below threshold
- Multi-tenant reviewer queue - clinical safety teams triage FAIL verdicts directly in the dashboard, with human-in-the-loop annotation flowing back into Phoenix
The infrastructure is production-grade. The problem is real and growing. This is the beginning of what medical AI infrastructure should look like.
Built With
- arize-phoenix
- clinicaltrials.gov
- dailymed
- fastapi
- gemini-2.5-flash
- google-adk
- medlineplus
- neon
- next.js
- openfda
- openinference
- opentelemetry
- phoenix-mcp
- postgresql
- pubmed
- python
- railway
- typescript
- vercel
- vertex-ai
- vertex-ai-agent-builder
- vertex-ai-search

Log in or sign up for Devpost to join the conversation.