-
-
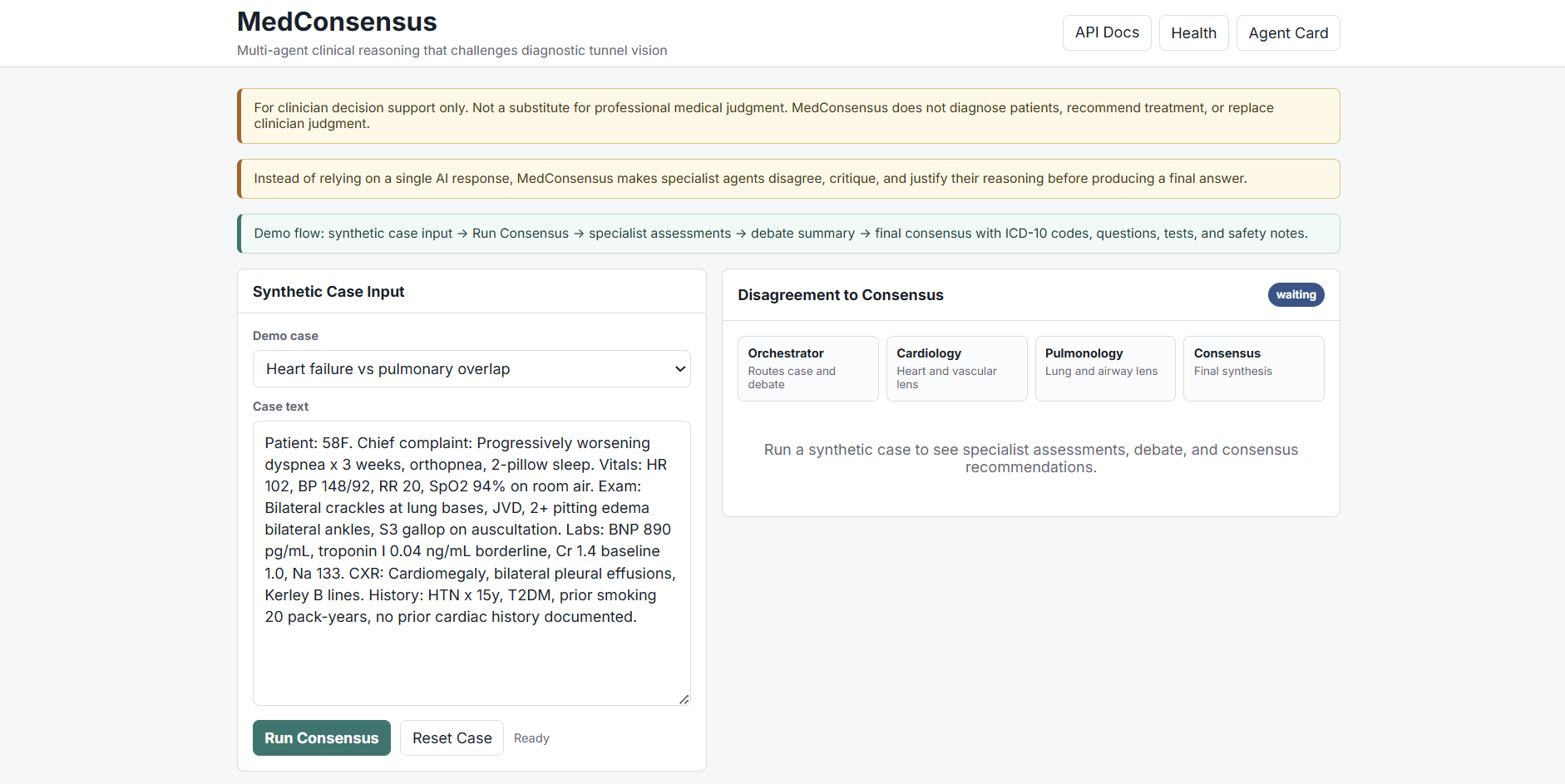
MedConsensus homepage: multi-agent clinical reasoning demo interface
-
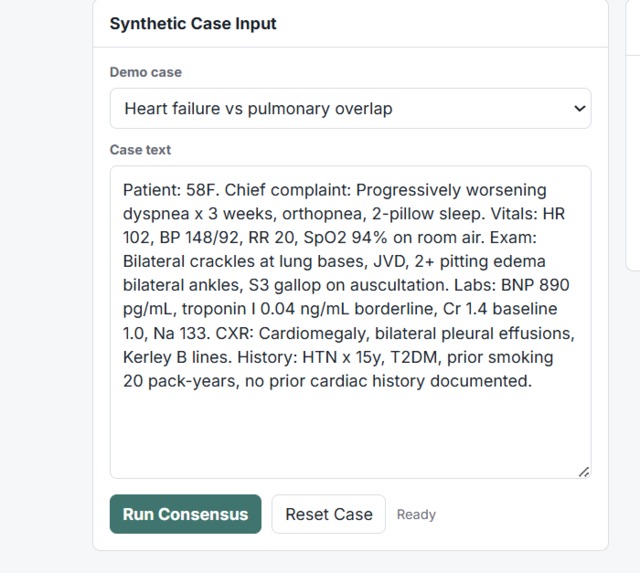
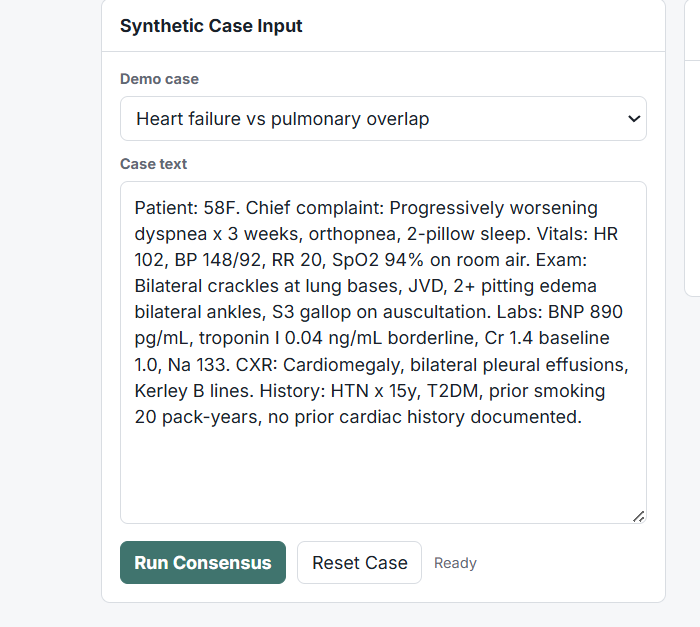
Synthetic patient case used for multi-agent evaluation
-
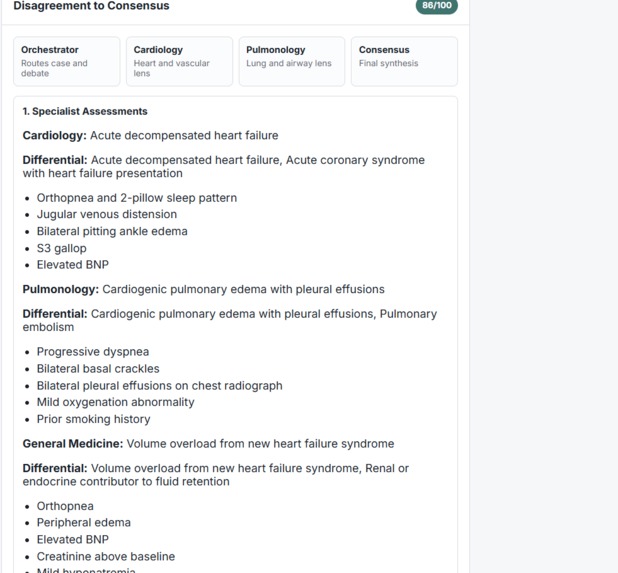
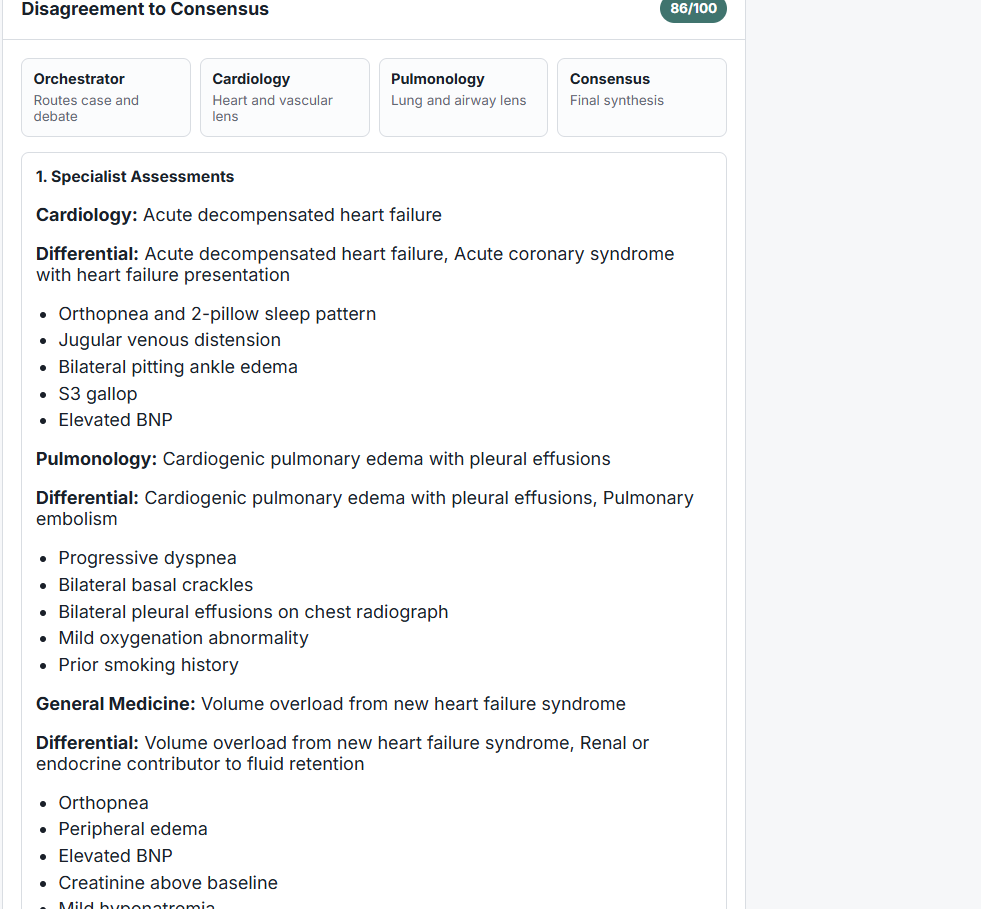
Independent specialist assessments before consensus
-
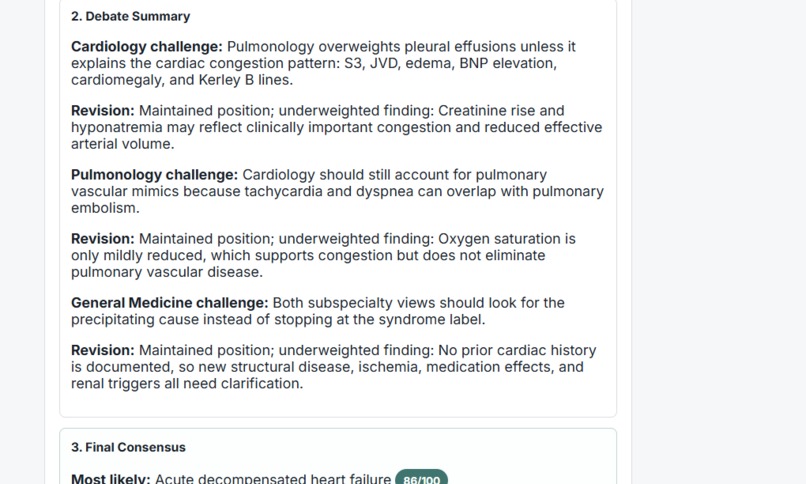
Agents challenge each other’s reasoning to reduce diagnostic tunnel vision
-
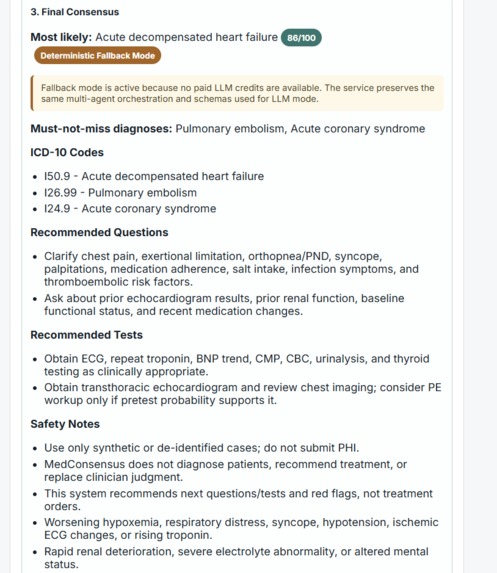
Final consensus with structured reasoning, confidence score, and ICD-10 codes
-
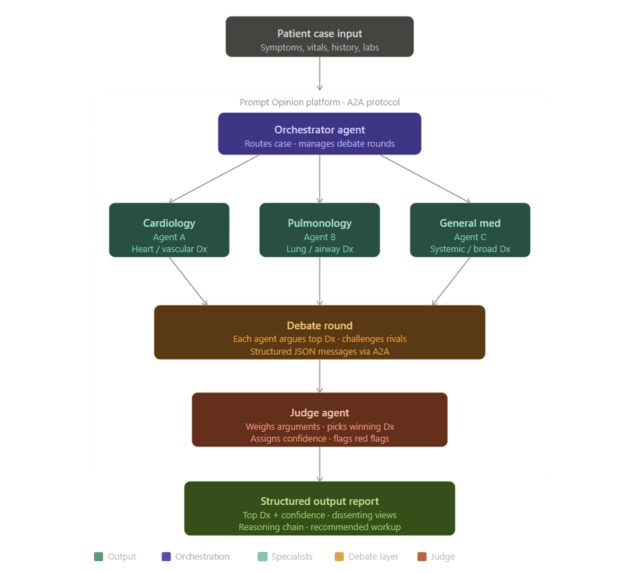
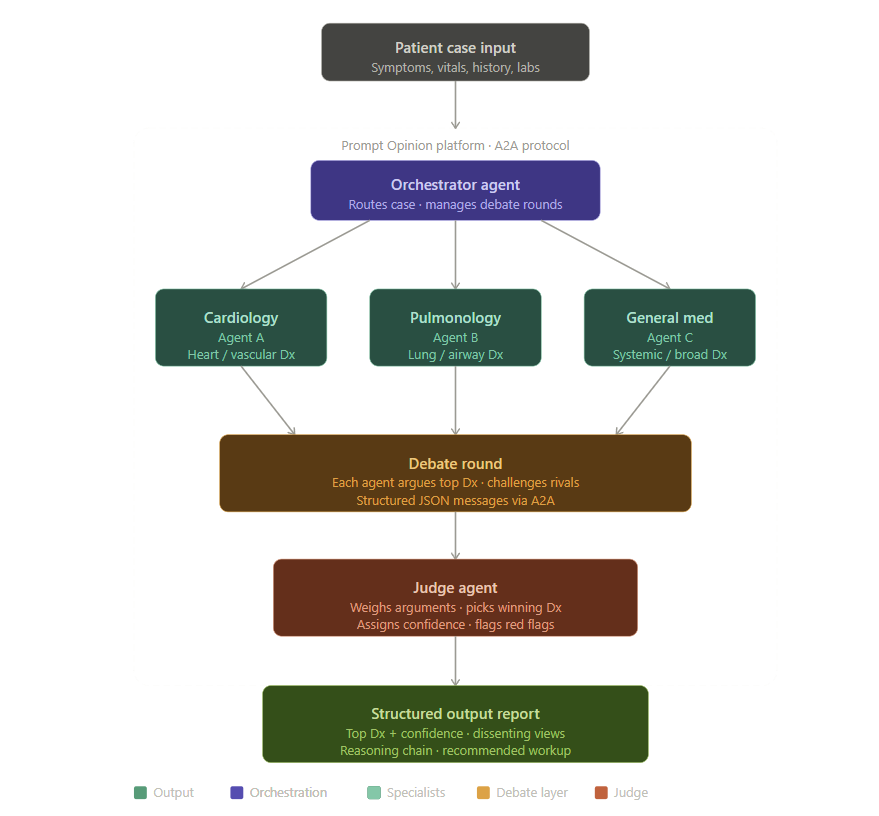
A2A-style multi-agent orchestration architecture


Inspiration
Most AI systems provide a single answer to complex problems. In healthcare, this can reinforce diagnostic tunnel vision, where one explanation dominates too early and alternative possibilities are overlooked. In real clinical practice, decisions are rarely made in isolation; physicians consult across specialties, challenge assumptions, and refine their reasoning collaboratively.
MedConsensus was inspired by this gap. We wanted to explore what happens when AI systems move beyond single responses and instead simulate how real clinical teams think: through structured disagreement, critique, and consensus.
What it does
MedConsensus is a multi-agent clinical reasoning system that evaluates synthetic patient cases through a panel of AI specialists.
The system:
- Distributes a case to General Medicine, Cardiology, and Pulmonology agents
- Each agent produces an independent assessment
- Agents critique and revise each other’s reasoning
- A Consensus Agent synthesizes a final structured recommendation
The output includes:
- most likely diagnosis
- differential diagnoses
- must-not-miss conditions
- recommended next questions and tests
- numeric confidence score (0–100)
- ICD-10 codes
- safety notes and disclaimer
Instead of a single opaque answer, MedConsensus produces a transparent reasoning process.
How we built it
MedConsensus is implemented as a FastAPI service using a multi-agent orchestration pattern.
Key components:
- A2A-style architecture for agent coordination
- Pydantic schemas for structured outputs
- LLM-powered agents for reasoning, critique, and revision
- Deterministic fallback mode for reliability
Each specialist agent uses a role-specific prompt to simulate domain expertise. The system performs two rounds of reasoning:
- Independent assessment
- Cross-agent critique and revision
The Consensus Agent then aggregates all outputs into a final structured report.
Challenges we ran into
One of the biggest challenges was moving beyond a traditional single-agent model. Designing a system where multiple agents produce meaningful, non-redundant perspectives required careful prompt design and orchestration.
Another challenge was balancing AI flexibility with reliability. Fully LLM-based systems can be unpredictable, so we implemented a deterministic fallback while maintaining an LLM-first architecture.
We also had to ensure strict safety constraints. The system uses only synthetic or de-identified data, avoids PHI entirely, and frames outputs as decision support rather than diagnosis or treatment.
Accomplishments that we're proud of
- Built a working multi-agent reasoning pipeline with independent assessment, critique, and consensus
- Created structured, explainable outputs instead of opaque responses
- Integrated clinical-style outputs including ICD-10 codes and confidence scoring
- Designed a system that is safe, compliant, and aligned with real-world healthcare constraints
- Delivered a complete, testable FastAPI service with marketplace-ready endpoints
What we learned
We learned that multi-agent systems can unlock capabilities that single-agent systems cannot, especially in domains requiring multiple perspectives.
We also learned that explainability is critical. Showing disagreement, uncertainty, and reasoning is often more valuable than providing a single confident answer.
Finally, we saw that structure matters. Without clear schemas and orchestration, multi-agent systems can quickly become inconsistent or difficult to interpret.
What's next for MedConsensus
Next steps include:
- Expanding to additional specialties (e.g., neurology, infectious disease)
- Improving reasoning depth with more advanced LLM prompting strategies
- Adding feedback loops to learn from clinician input
- Enhancing evaluation with real-world benchmark datasets (while maintaining privacy constraints)
- Integrating into clinical workflows as a lightweight decision-support layer
Ultimately, MedConsensus aims to evolve from a hackathon prototype into a scalable system that supports collaborative, transparent, and safer decision-making in healthcare.

Log in or sign up for Devpost to join the conversation.