
Inspiration
One of our team members tore their ACL. The surgery went fine. Then came a $48,000 bill with no explanation — just a wall of CPT codes and dollar amounts that meant nothing. We spent hours trying to figure out if the charges were even legitimate. Most people don't have the time or knowledge to do that. MedClarity started as a personal frustration and became a mission: every patient deserves to understand what they're being charged and whether it's fair.
What it does
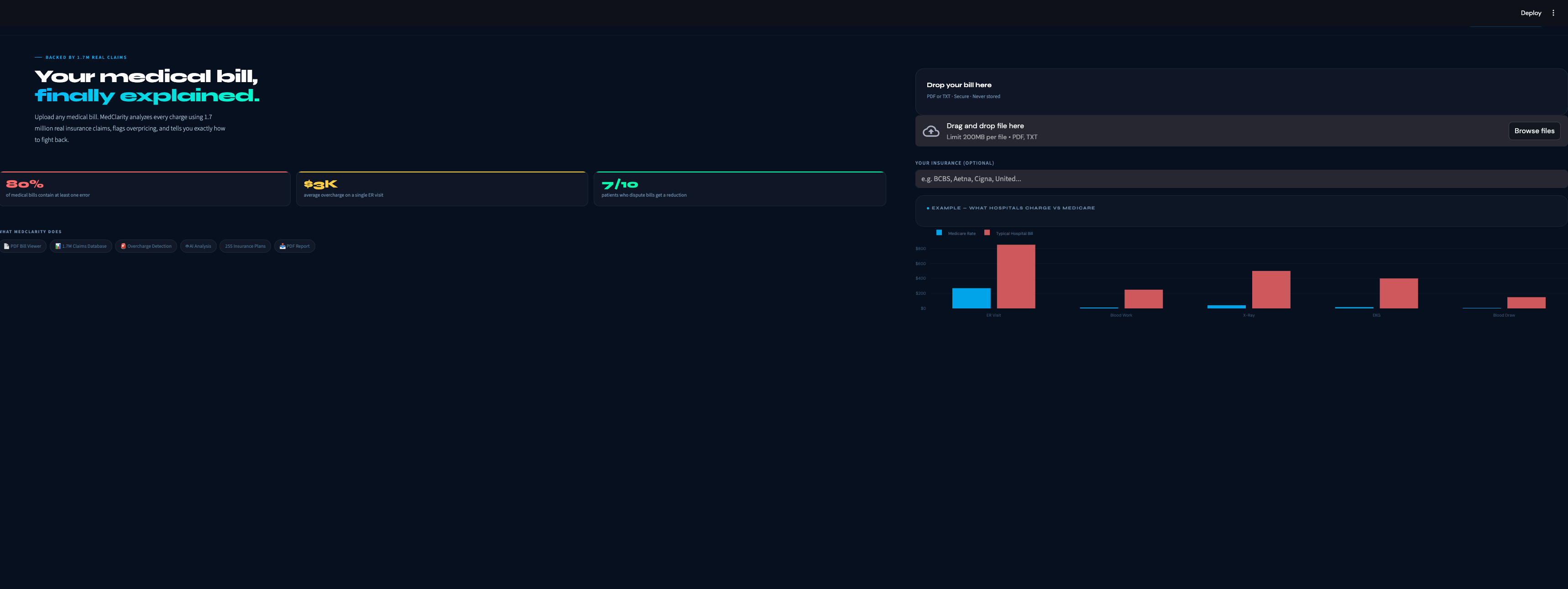
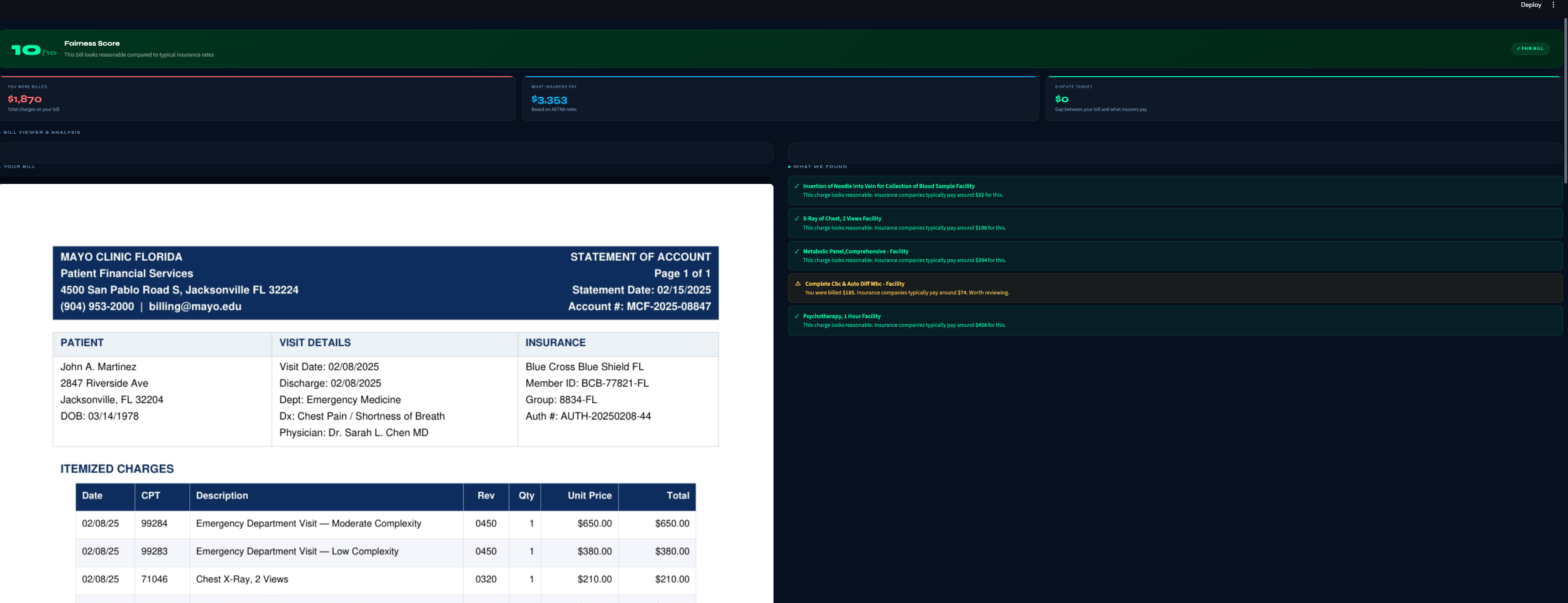
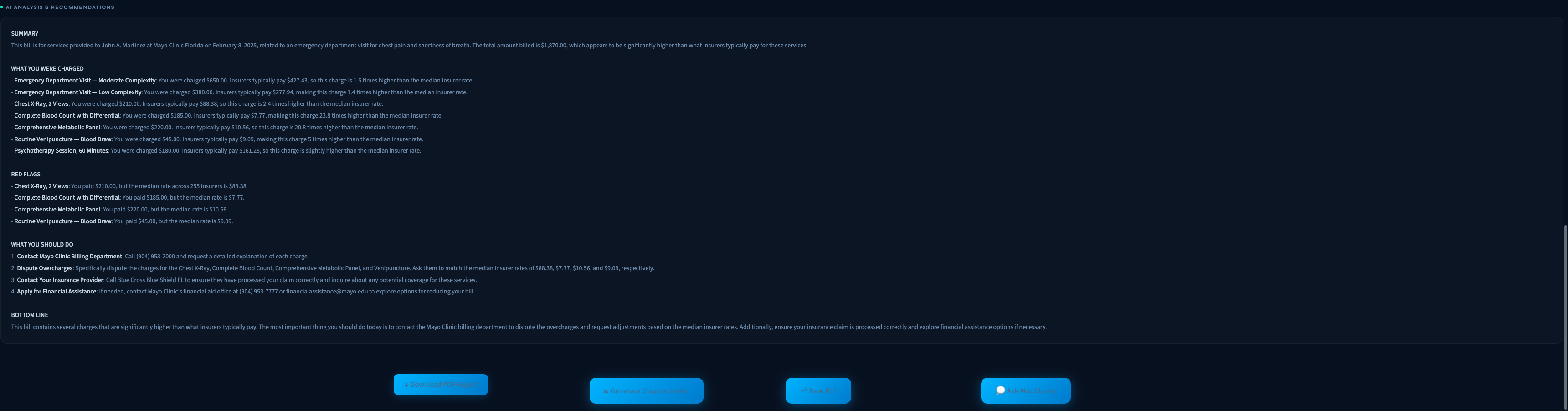
MedClarity analyzes medical bills using two real datasets — 1.7 million actual claims from Mayo Jacksonville covering 255 insurance companies, and the federal CMS Physician Fee Schedule. Upload a PDF bill and within 30 seconds you get: a plain-English explanation of every charge, a fairness score from 1 to 10, flags for any procedure billed significantly above what insurers actually pay, a breakdown of what different insurance companies pay for the same procedure, and a professional dispute letter you can send to the billing department. A built-in chatbot answers follow-up questions about your specific bill.
How we built it
The pipeline starts with pdfplumber, which extracts text and table structure from medical bill PDFs — preserving the column layout that other parsers scramble. We then use GPT-4o to tie each CPT code to its specific dollar charge on the same table row, solving the hardest accuracy problem in the pipeline. Those codes get matched against our Mayo Jacksonville MRF parquet file and the CMS fee schedule to produce benchmarks, percentiles, and overcharge probabilities. GPT-4o then receives all of that structured data as context and generates the plain-English analysis — it explains, it doesn't decide. The frontend is Streamlit with custom CSS matching a dark medical-tech aesthetic, and the dispute letter and PDF report are generated programmatically from the analysis results.
Challenges we ran into
The biggest technical challenge was accurate CPT-to-charge linking. Medical bills don't follow a standard format — charges and codes appear in different columns, different orders, and sometimes across multiple lines. Early versions of our matcher grabbed random dollar amounts from the bill and compared them to random benchmarks, producing completely wrong fairness scores. We fixed this by using the LLM specifically for structured extraction before any analysis runs. The second challenge was outliers in the MRF data. A single dataset contains Medicaid rates of $8 and out-of-network rates of $12,000 for the same procedure. Naively taking a median across all of them produced benchmarks that made no sense. We added per-CPT IQR filtering and switched from Ridge regression to HuberRegressor to make the model robust to the remaining outliers. We also scrapped our hospital price comparison feature mid-build after realizing the Dolthub hospital transparency data is inconsistently formatted across hospitals — some report gross charges, some report negotiated rates, some report neither correctly. Replacing it with the CMS fee schedule was the right call but cost us several hours.
Accomplishments that we're proud of
We're proud that this is genuinely not a GPT wrapper. Every overcharge flag, fairness score, and benchmark number comes from deterministic code running against real federal and hospital data. GPT-4o only touches the output layer. We're also proud of the CPT-to-charge linking solution — it's the kind of problem that looks simple until you try to solve it with real messy bills. And the chatbot knowing the patient's actual bill well enough to answer specific questions like "why was I charged $4,000 for that blood test" is something we're genuinely excited about.
What we learned
Healthcare data is messier than any other domain we've worked with. The federal government mandates price transparency but doesn't enforce format standards, which means 6,000 hospitals report the same information in 6,000 different ways. We learned to be skeptical of any dataset that sounds clean in description — validate it against real examples before building on it. We also learned that the hardest part of an AI product isn't the AI — it's the data pipeline that feeds it. We spent more time on PDF parsing, CPT extraction, and outlier handling than on anything involving GPT-4o.
What's next for MedClarity
Expand the claims database beyond Mayo Jacksonville to cover all US hospital MRF filings — that's 330 million rows of real negotiated rates across thousands of hospitals. Add a trained ML model that predicts what a fair rate should be for a specific patient's procedure, payer, and location. Build a mobile app where you photograph your bill and get instant analysis. And pursue the B2B angle — insurers and large employers have strong financial incentive to help members catch billing errors before they pay them, and MedClarity can be white-labeled as a member benefit.

Log in or sign up for Devpost to join the conversation.