-
-
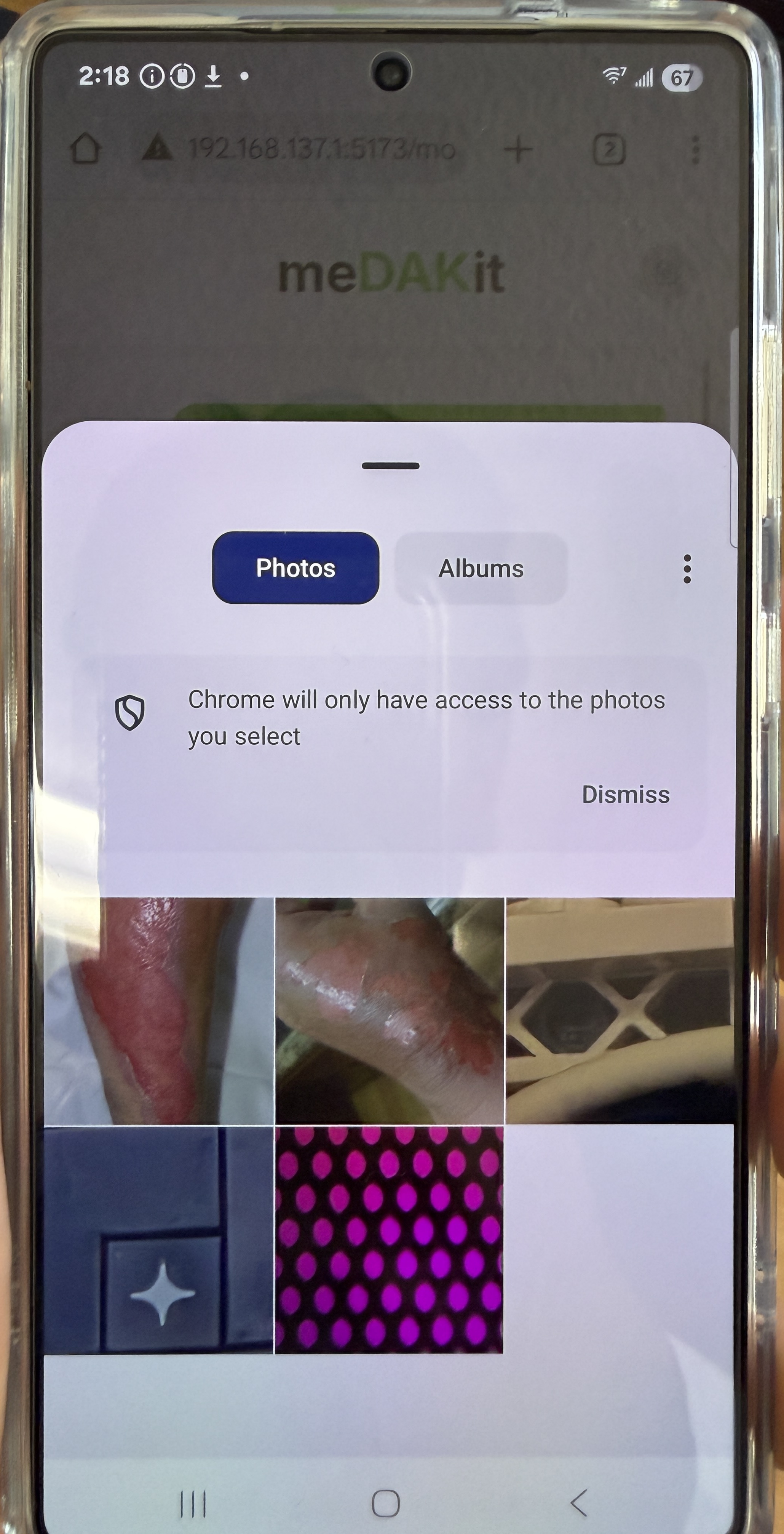
Photo Library on Phone
-
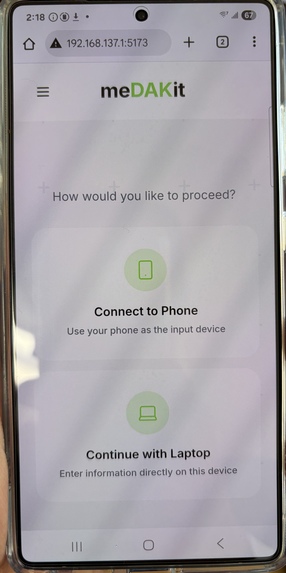
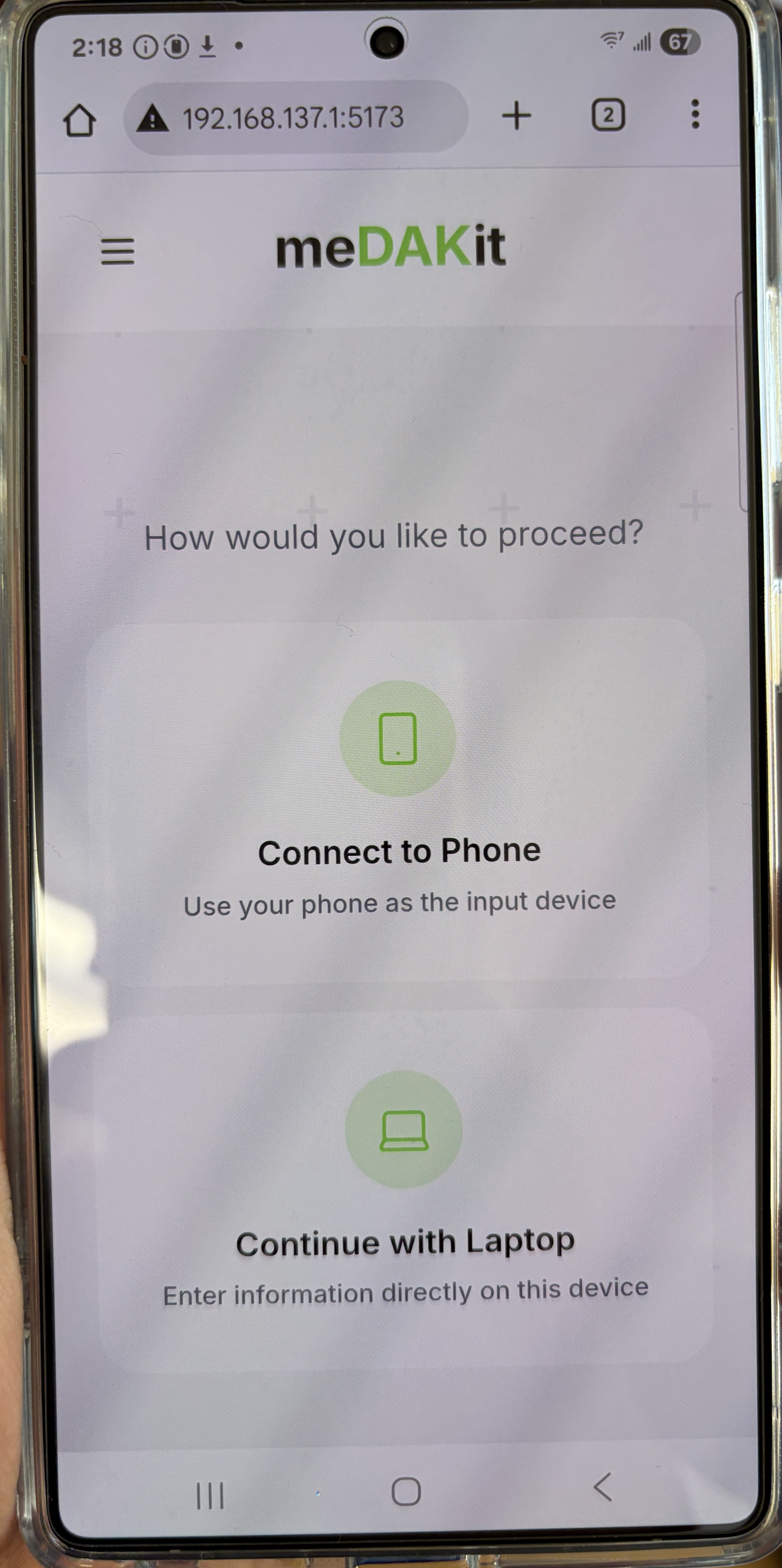
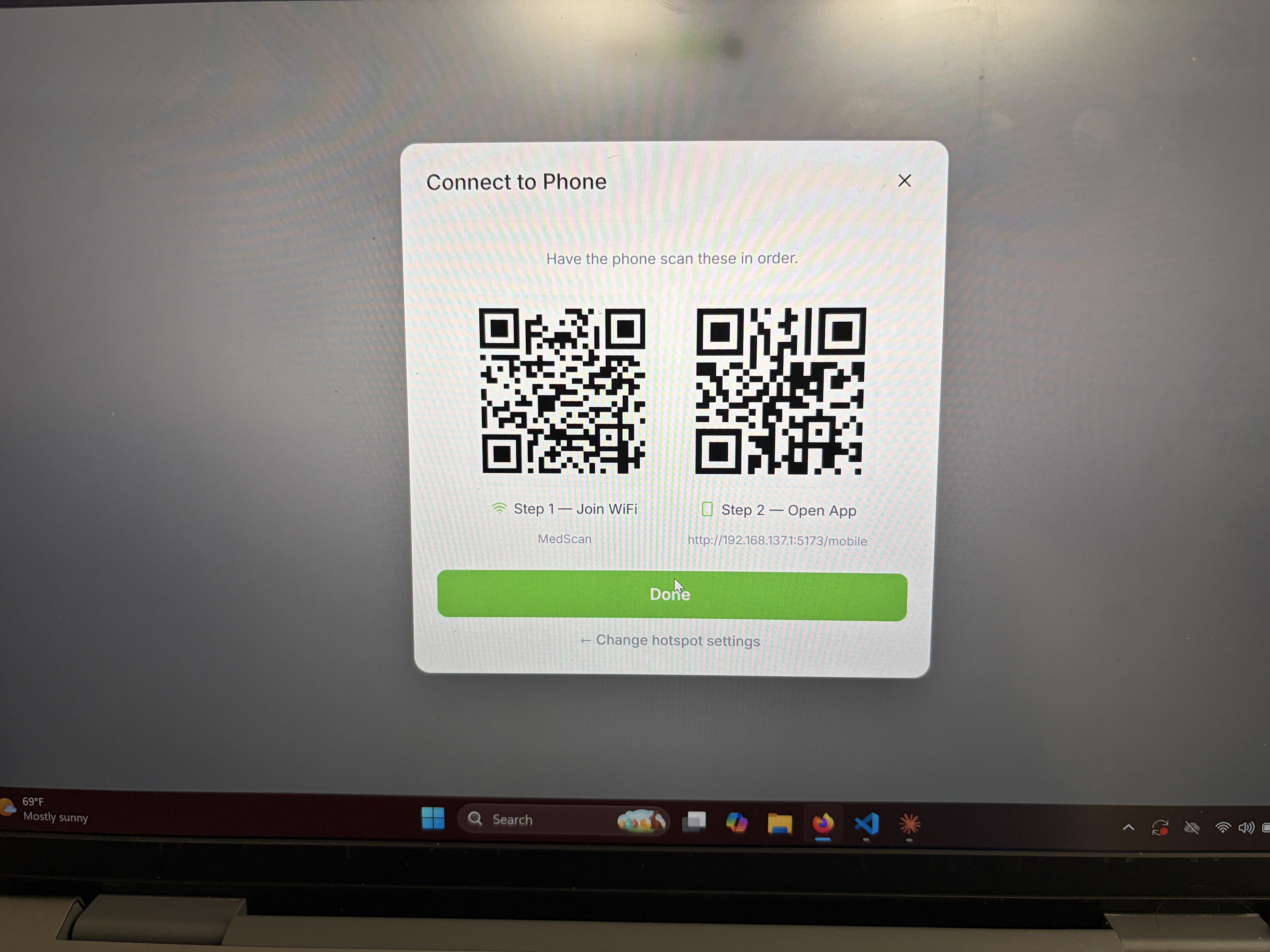
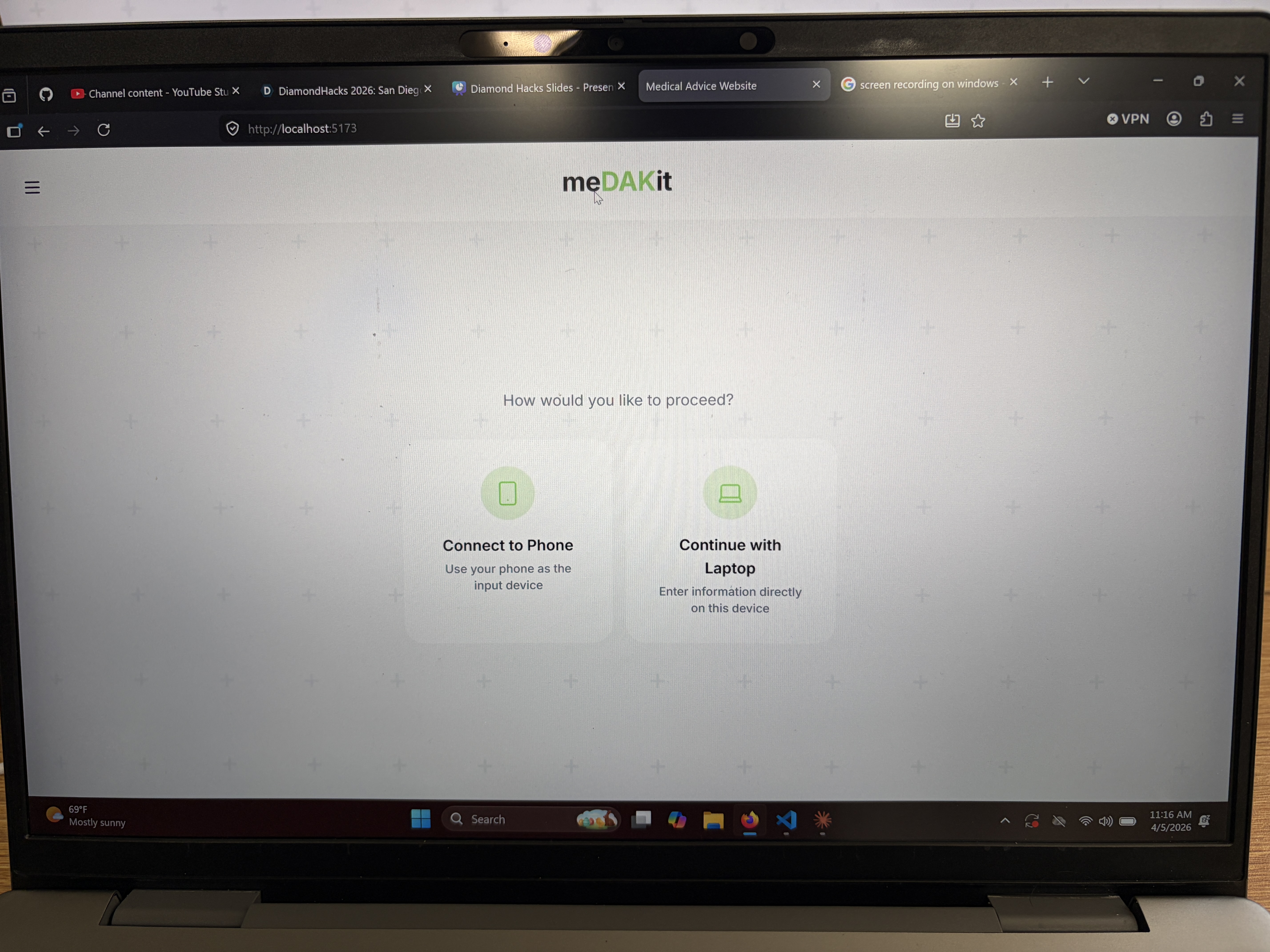
Phone Interface
-
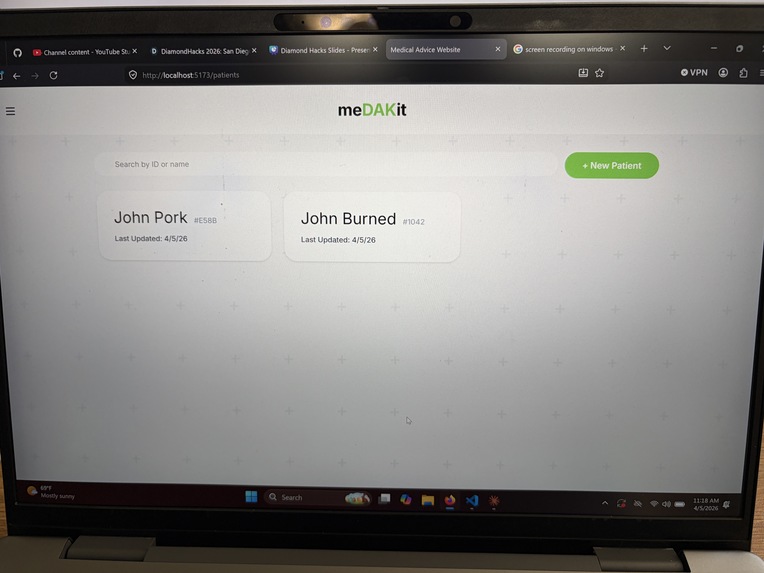
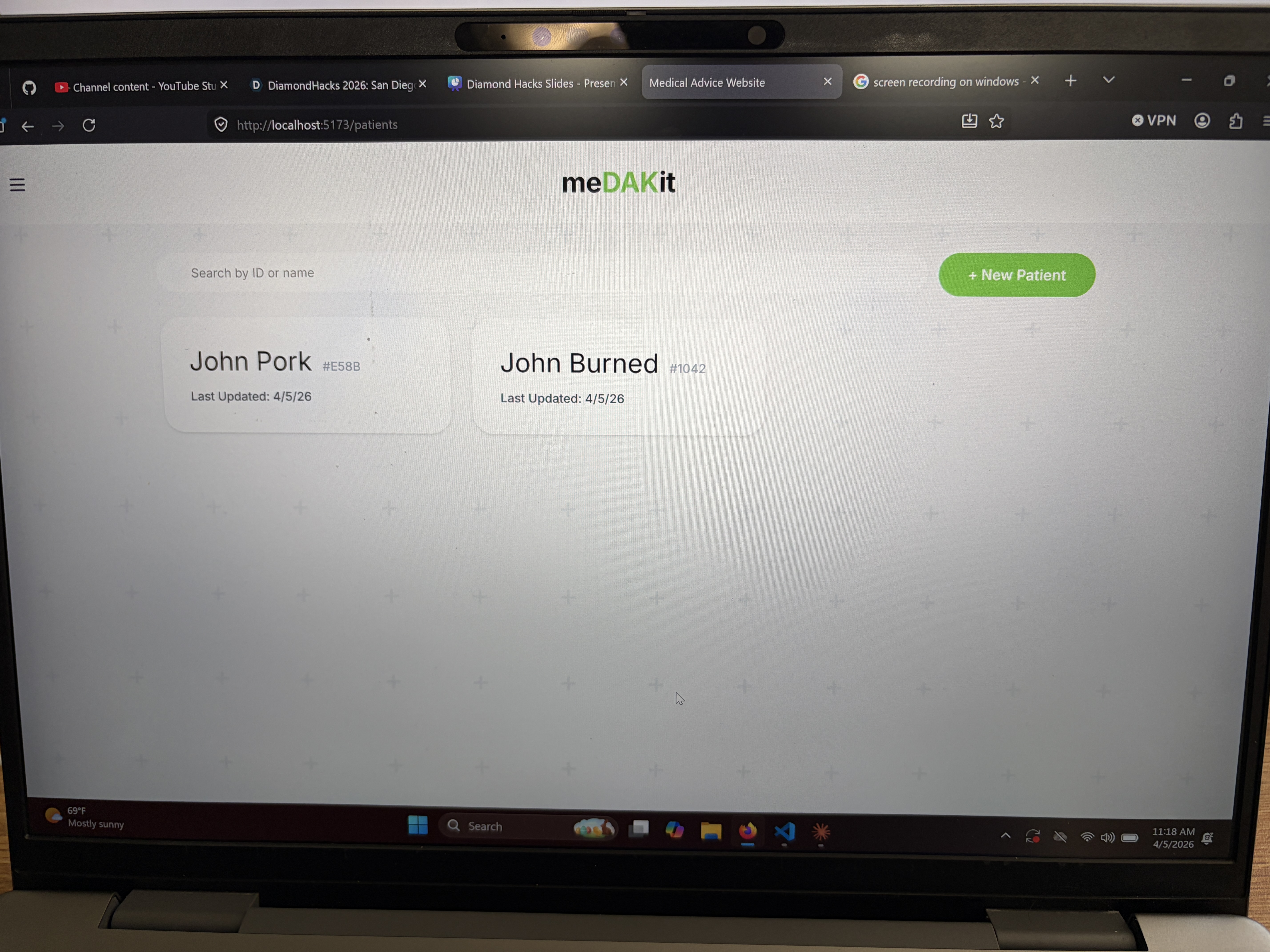
Patient Database
-
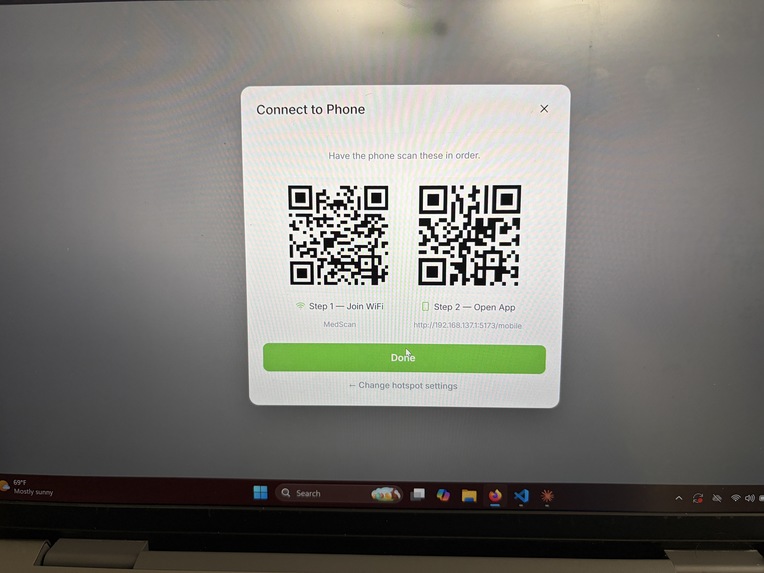
Wifi Connectivity
-
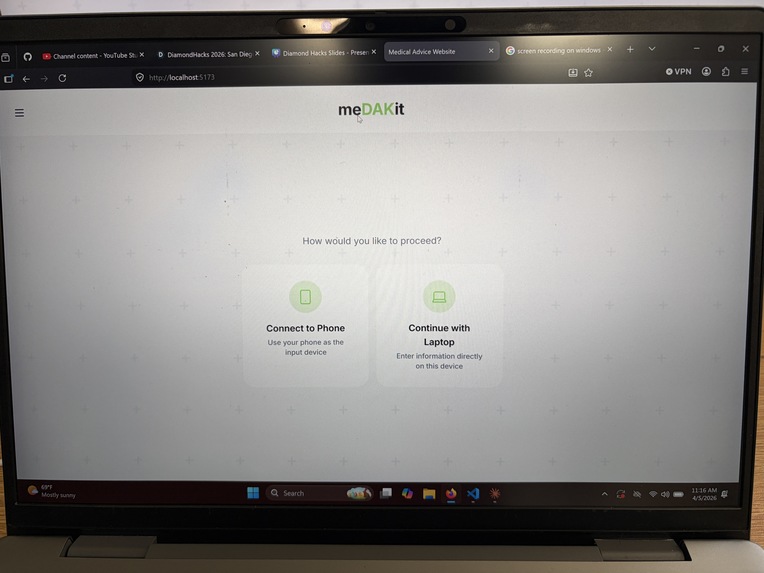
Landing Screen
-
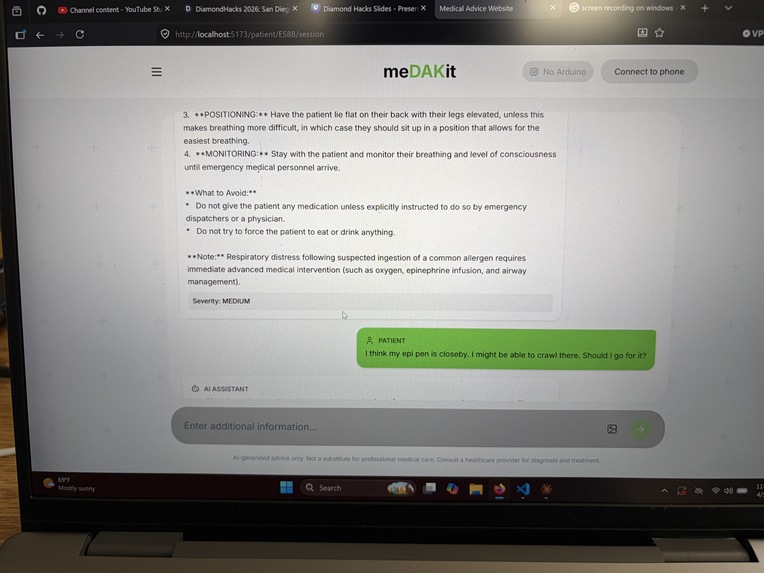
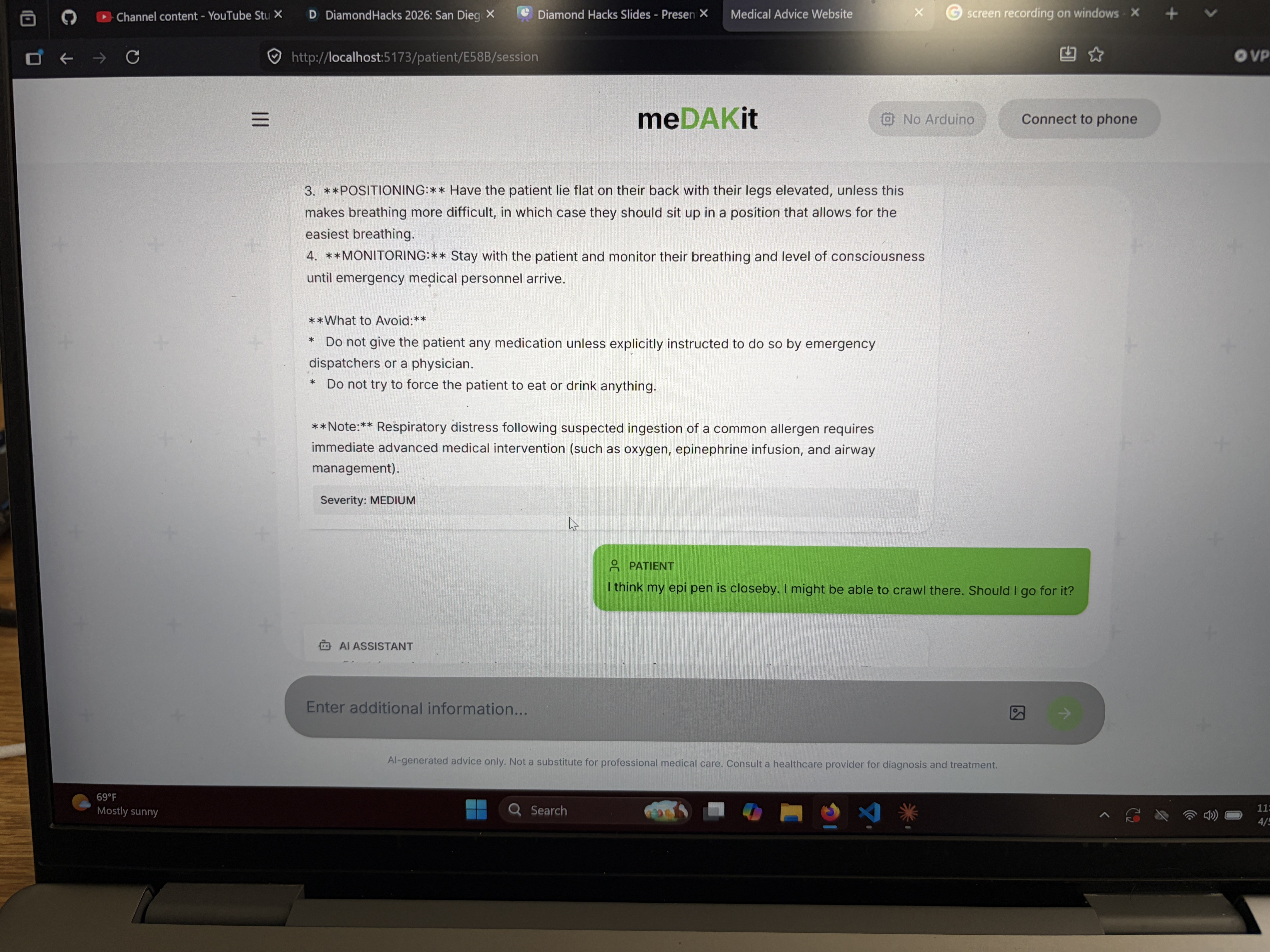
Chat With AI Model
MeDAKit: Devpost Write-up
Inspiration
Medical emergencies are high-stakes, time-sensitive situations where access to accurate, fast information can mean the difference between life and death. However, most AI health tools either rely on cloud APIs (which fail without connectivity) or are too generic to handle clinical nuance which end up providing the use no help. We wanted to build a local-first, medically specialized emergency assistant that would have real clinical knowledge, retrieves reference images, and runs entirely on your own hardware, no internet required.
What It Does
MeDAKit is an AI-powered medical emergency decision support tool. Given a set of symptoms or an emergency scenario, it:
- Reasons through the situation using a fine-tuned Gemma 4 model specialized for medical emergency response
- Retrieves semantically relevant medical reference images (rashes, wounds, anatomical diagrams, etc.) using text descriptions of symptoms
- Retrieves clinical facts from a curated medical dataset to ground responses in evidence
- Serves everything through a clean React/Vite web interface backed by a FastAPI API server
The entire pipeline of inference, retrieval, and embedding runs locally on consumer hardware.
How We Built It
The stack has three main layers:
1. Fine-Tuned LLM
We fine-tuned Gemma 4 on the MedRescue dataset, a clinical emergency response corpus. Training used 4-bit NF4 quantization via BitsAndBytes and LoRA adapters via the Hugging Face PEFT library, making it feasible on a single consumer GPU (RTX 5070 Ti, 16 GB VRAM). The resulting adapter is exported as a .gguf file and served locally via Ollama.
2. Two-Tower RAG Engine
Rather than one large monolithic embedding model, we built a dual-encoder retrieval system backed by ChromaDB:
- Text Tower: PubMedBERT (pritamdeka/S-PubMedBert-MS-MARCO): a compact, clinically accurate model that embeds medical facts from the MedRescue dataset. Optimized for domain-specific semantic similarity.
- Image Tower: SigLIP / CLIP (clip-ViT-B-32): a multimodal vision-language model that embeds 2,000+ medical images sourced from Kaggle and Roboflow, enabling retrieval by text symptom query.
The design intentionally keeps each tower small and specialized which has a a deliberate tradeoff for cross-platform portability, including NPU-accelerated devices like the Snapdragon X Elite.
3. Data Pipeline
A modular ingestion pipeline streams and purges datasets from Kaggle, Roboflow, and Hugging Face, then pre-computes the ChromaDB vector store. The resulting chroma_db folder is portable. This folder is generated once on a GPU machine, then it is dropped into any other device for instant retrieval without re-embedding.
Frontend
Built with React, Vite, Tailwind CSS, and Radix UI for accessible, fast-loading components.
Challenges We Ran Into
- Model access and gating: Gemma 4 is a gated model on Hugging Face, requiring token-based authentication and careful management of download credentials across machines.
- VRAM constraints during fine-tuning: Even with 4-bit quantization, fitting Gemma 4 into 16 GB VRAM required careful batch sizing and gradient checkpointing. Small errors in the training config led to OOM crashes that cost hours.
- Cross-platform RAG portability: Making the same ChromaDB index run smoothly on both an RTX 5070 Ti (CUDA) and a Snapdragon X Elite (NPU/CPU) required abstracting the embedding pipeline to avoid CUDA-specific dependencies.
- Multimodal retrieval quality: Aligning text symptom queries to relevant medical images is harder than pure text-to-text retrieval. Tuning the similarity threshold and choosing SigLIP/CLIP as the image tower took several iterations.
- Dataset heterogeneity: Medical image datasets from Kaggle and Roboflow have inconsistent formats, label schemas, and resolutions. The stream-and-purge pipeline design was essential to avoid bloating local storage.
Accomplishments That We're Proud Of
- Successfully fine-tuned a frontier-class model (Gemma 4) end-to-end on consumer hardware, producing a clinically adapted adapter that runs via Ollama with no cloud dependency.
- Built a two-tower RAG engine from scratch with clean separation between image and text retrieval paths.
- Achieved a fully offline-capable medical assistant: inference, retrieval, and embedding all run locally, making it viable in low-connectivity or privacy-sensitive environments.
- Designed the system to be portable across architectures, from high-end desktop GPUs to NPU-equipped laptops.
What We Learned
- LoRA + 4-bit quantization is genuinely powerful — fine-tuning a multi-billion parameter model on a single gaming GPU is no longer theoretical. The PEFT + BitsAndBytes combination makes it accessible.
- Domain-specific embeddings matter: swapping a general-purpose embedding model for PubMedBERT yielded meaningfully better clinical retrieval — generic cosine similarity over general embeddings frequently missed the medical context.
- RAG architecture decisions compound: choosing two lightweight specialized towers over one large model cascades into benefits for latency, portability, and memory — but requires more careful engineering at each stage.
- Building for offline-first forces good software hygiene: every dependency must be explicit, every artifact must be versioned and portable.
What's Next for MeDAKit
- Triage scoring: Incorporate a structured triage output (e.g., ESI levels or START triage protocol) alongside free-text reasoning, giving responders a numeric urgency signal.
- Voice interface: Add speech-to-text input so the tool is usable hands-free in field emergency scenarios.
- Mobile/edge deployment: Package the adapter and RAG engine for on-device inference on Android (Snapdragon) and iOS (Apple Neural Engine) using GGUF quantization and ONNX exports.
- Expanded dataset coverage: Integrate additional emergency medicine datasets (e.g., MIMIC-IV clinical notes, PhysioNet) to broaden the model's coverage of rare presentations.
- Multilingual support: Fine-tune on translated clinical datasets to serve non-English-speaking communities where emergency medical access is most constrained.

Log in or sign up for Devpost to join the conversation.