

Inspiration
The problem we are solving is the inconvenience and expense of doctor appointments for common health concerns. We chose this problem because we aim to address the barriers to accessing timely healthcare, including long waits at the hospital. Additionally, factors such as language and cultural barriers, primary care access issues, and challenges in doctor-patient communication further emphasize the need for a recommendation system to improve healthcare accessibility and quality.
What it does
Our project aims to offer a reliable medicine search system that recommends appropriate medications, leveraging extensive datasets, including medicine reviews, side effects, and interactions, to provide users with cost-effective and rapid healthcare guidance.
How we built it
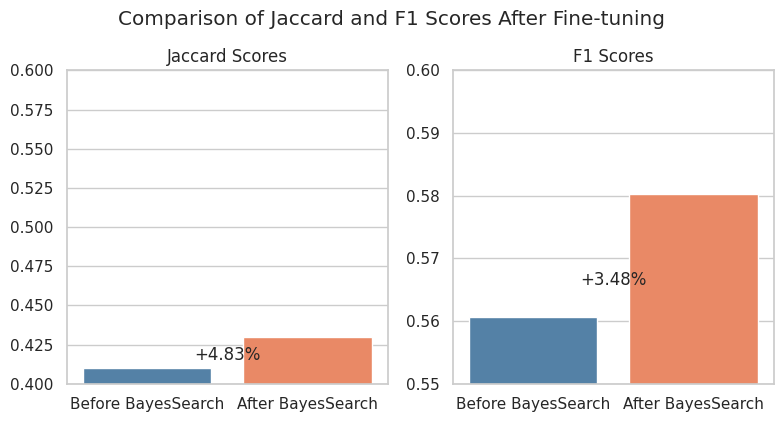
We initially experimented with a Random Forest Classifier using the MultiOutputClassifier with specific hyperparameters, which yielded Jaccard scores of 0.4100 and F1 scores of 0.5607. After fine-tuning using BayesSearchCV, we selected a refined configuration for the MultiOutputClassifier with the following hyperparameters: max_depth=37, min_samples_leaf=4, min_samples_split=14, n_estimators=112, and bootstrap=False, resulting in improved performance.
Challenges we ran into
We initially encountered challenges when attempting to train our model using a small dataset containing only 350 data points, resulting in poor training results. As a solution, we transitioned to the MIMIC dataset and faced difficulties in mapping medication names to their real names since they were represented as ATC codes.
Accomplishments that we're proud of
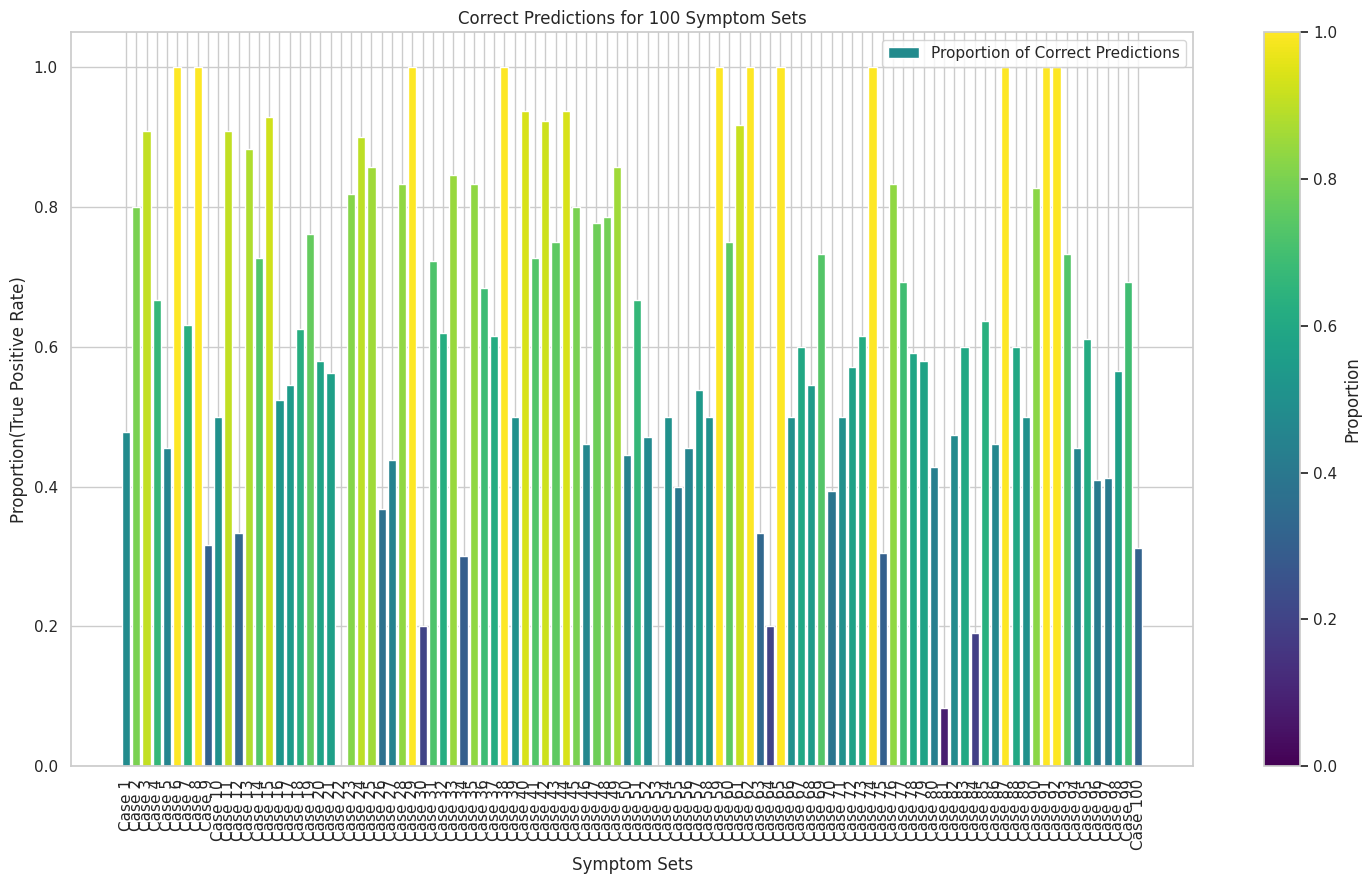
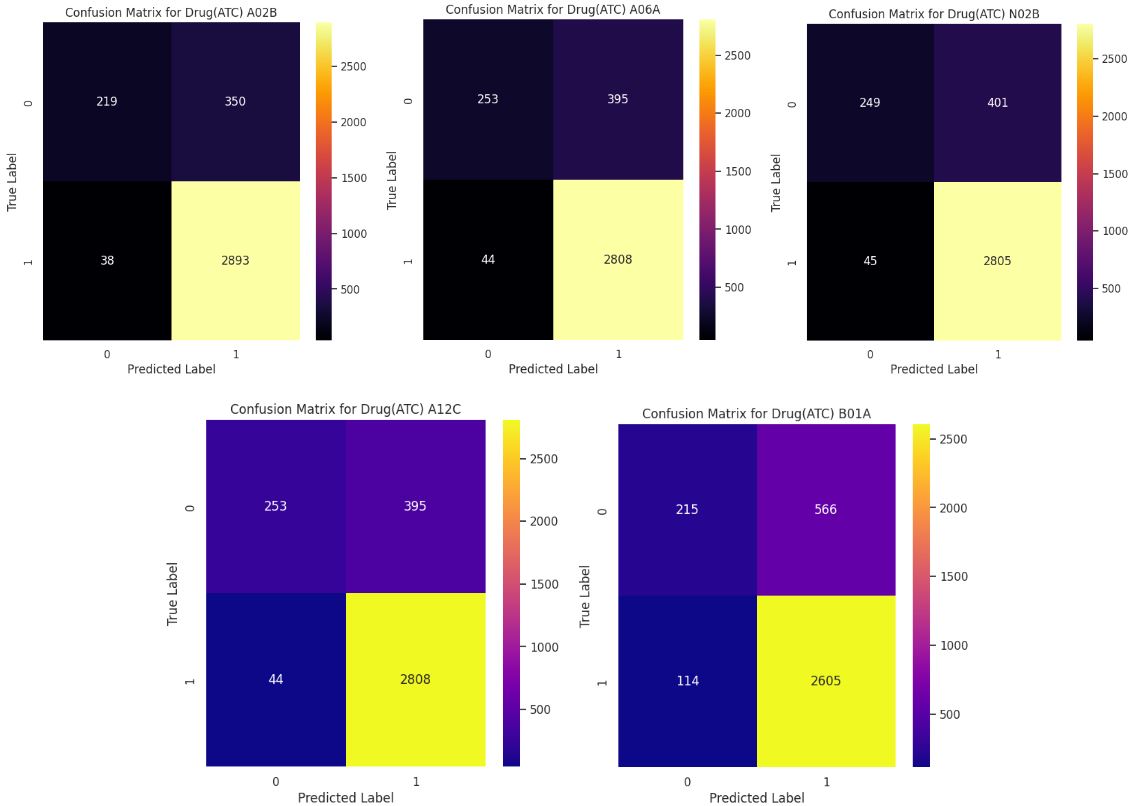
The result we are most satisfied with is the improvement in Jaccard scores and F1 scores after fine-tuning, which indicates better model accuracy. Additionally, the high true positive rate and low number of false negatives in the confusion matrix demonstrate the model's strong performance in accurately predicting common drug prescriptions, reducing the risk of ineffective treatments and patient health complications.
What's next for MedAdvisor
If we were to continue this project, we would focus on addressing the increasing false positive rate that occurs after training on larger datasets. It's essential to continuously monitor and refine the model to maintain its reliability, particularly in the context of drug prescription tasks where overlooking essential medications can have severe consequences, ensuring its practical applicability in real-world healthcare scenarios.

Log in or sign up for Devpost to join the conversation.