-
-
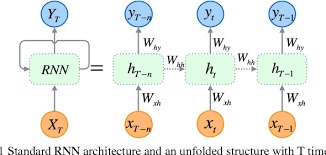
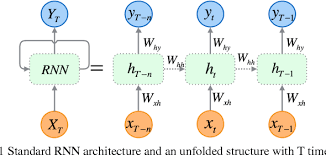
RNN
-
-
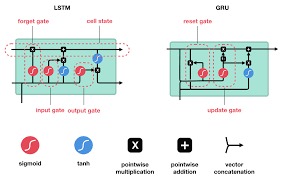
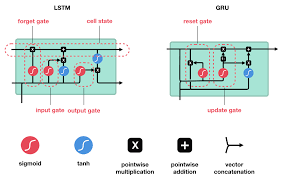
Inspiration
During valentines day, many of us are left wondering regarding the different crushes and emotions people have for each other. What if you were able to judge based on the writing they may send within a chat? What if simply from their writing style you could figure out what they felt? Are you reading too much between the lines? Are you two a good match? This is exactly what we did creating an application that uses Natural Language Processing and Machine Learning to predict accurately what the sender of the message is feeling to save you the headache.
What it does
In this project, what we have done is created a fully functioning discord scraping, message sentiment analysis machine learning model which determines compatibility and feelings between individuals based on messages for the upcoming Valentine's Day on a flask application.
How we built it
First, we created a recurrent neural network featuring a long short-term memory layer which would be used to predict the sentiment and “love” in the messages we will scrape. Our recurrent neural network trained on thousands of sentences, recursively applies input, allowing for the time series of the data to be taken into consideration through layers such as Dense and LSTM. The lstm layer is made up of 3 gates, in control of filtering all data passed optimized for natural language processing. We scraped messages directly from our discord server, however, to be fed into the model, we passed it through several stages of natural language preprocessing such as regex filtering, tokenization, lemmatization, part of speech tagging, and stop word removal. Next, math and weighting were then applied to the results of the model to achieve our final judgments such as “In love” or “bad match” along with individual “affection scores” separate from other users. Finally, these results were applied to a rudimentary flask application which we plan to later develop. Python libraries such as keras, flask, pickle, csv, nltk, requests, re, and tensorflow were used.
Challenges we ran into
Throughout this project, the initial idea was to create a fully functioning app. However, as we quickly progressed through the hackathon, we realized the time constraint did not allow for this. This is due to the thousands of data iteration filtering along with the extensive machine learning model training time to get the best possible predictions. In the end, we decided to focus on the core concept application and results rather than more surface-level ideas. Another challenge was the research and building of the machine learning model itself. Natural language processing models need a lot of hyperparameter tuning along with the right type of data. Multiple datasets were attempted before one was settled on. Finally, the preprocessing of data was extremely difficult involving concepts such as lemmatization and perception taggers.
What we learned
Throughout this hackathon, many libraries were explored such as nltk and requests. This brought a deeper understanding of natural language processing along with the human language in general. The logic behind recurrent neural networks along with the layers used (lstm, dense, etc.) was greatly increased. Data preprocessing is an extremely important part of our project, and as such, a great amount of research and learning was put into the techniques (regex, NLP, etc.), tips (formating), and tricks (shortcuts). Implementing a rudimentary flask website on localhost was also a new experience.
Built With
- discord
- flask
- keras
- lstm
- machine-learning
- natural-language-processing
- python
- webscraping

Log in or sign up for Devpost to join the conversation.