-
-
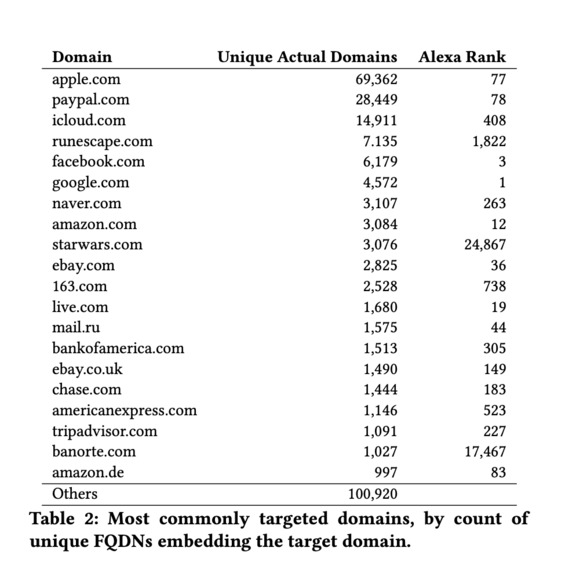
-
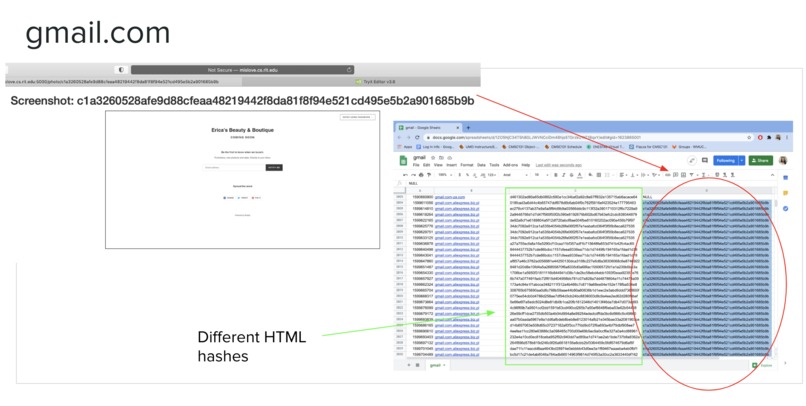
-

part of the phishing html
-
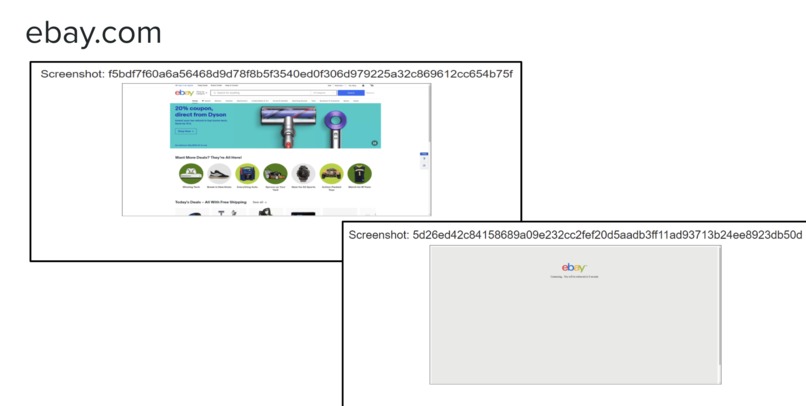
-

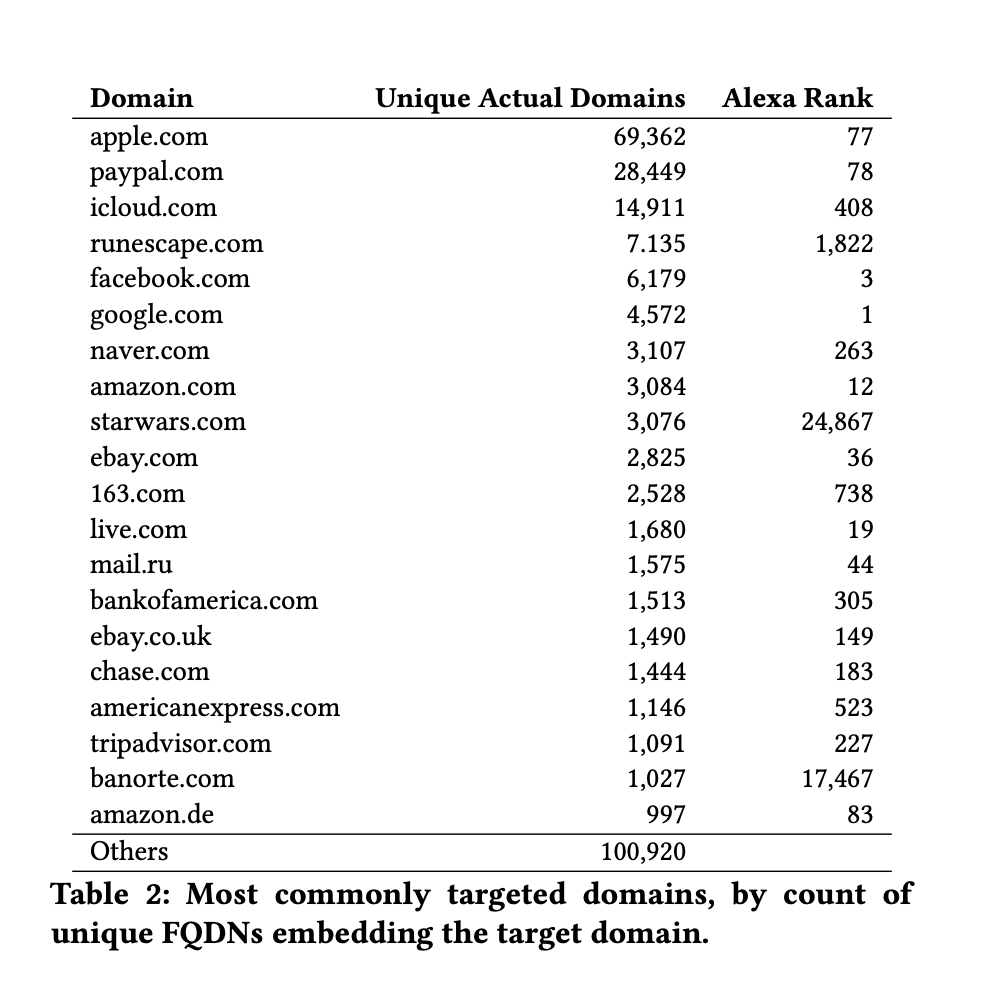



Inspiration
We were inspired by how phishing pages have changed over time, and how it might not be so easy for some people to recognize them since phishers have become more skilled in hiding their true intentions with a website.
What it does
We sorted through 300,000+ datasets and organized them by what type of page they were (Index of, account suspended, reroutes, etc.) and attempted to find the similarities between the data points in or data
How we built it
We were on the research track, so we are focusing on using the data we got and analyze them.
Challenges we ran into
We had a huge dataset to go over in a very short time. We had thousands of websites at different timestamps to go over. To get this done, we divided the work amongst the four of us. We did get a great start at analyzing the given data.
What we learned
We were the first ones to look through these data points and this data is going to be used in real research, so the fact that we got our hands on actual research data points is exciting. We learned about how data can be saved in the form of hashes to work around it effectively. We also saw how much work goes into not just collecting the data but also in analyzing and getting results from it.
What's next for Measuring the Evolution of Phishing Webpages
While we were looking at the similarities and differences of phishing, the next step is to look at how these phishing websites change over time.




Log in or sign up for Devpost to join the conversation.