-
-
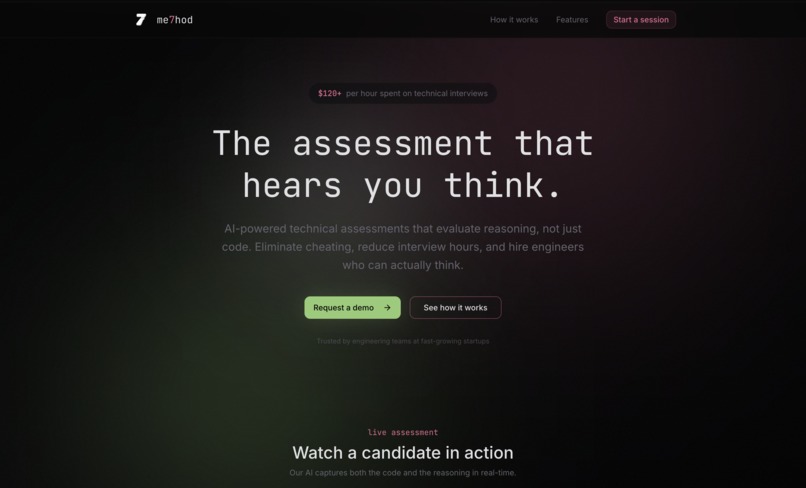
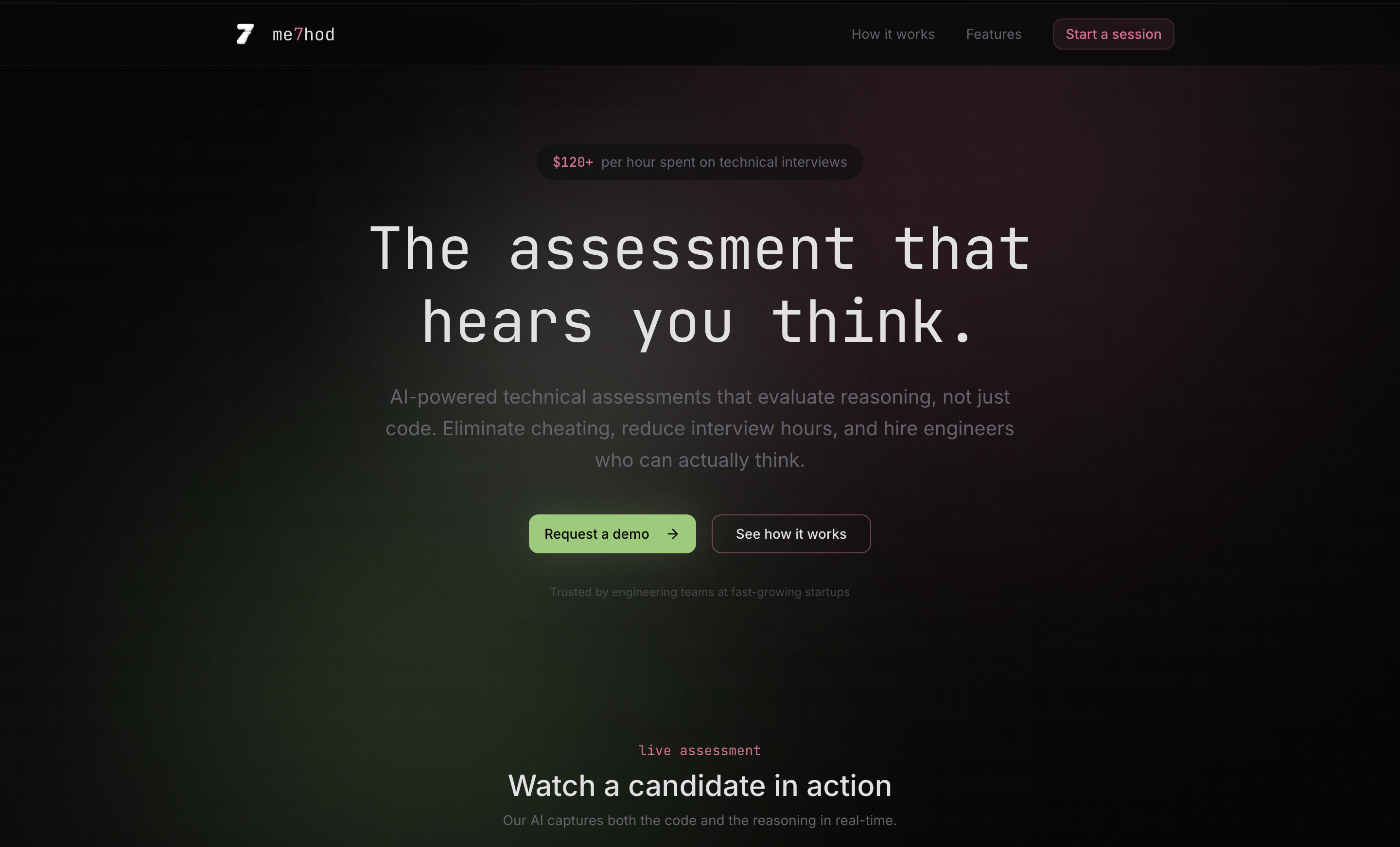
Landing Page
-
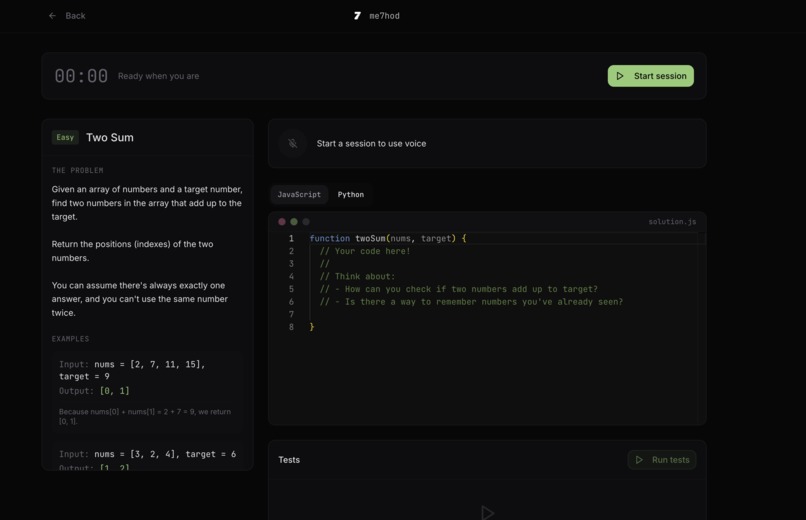
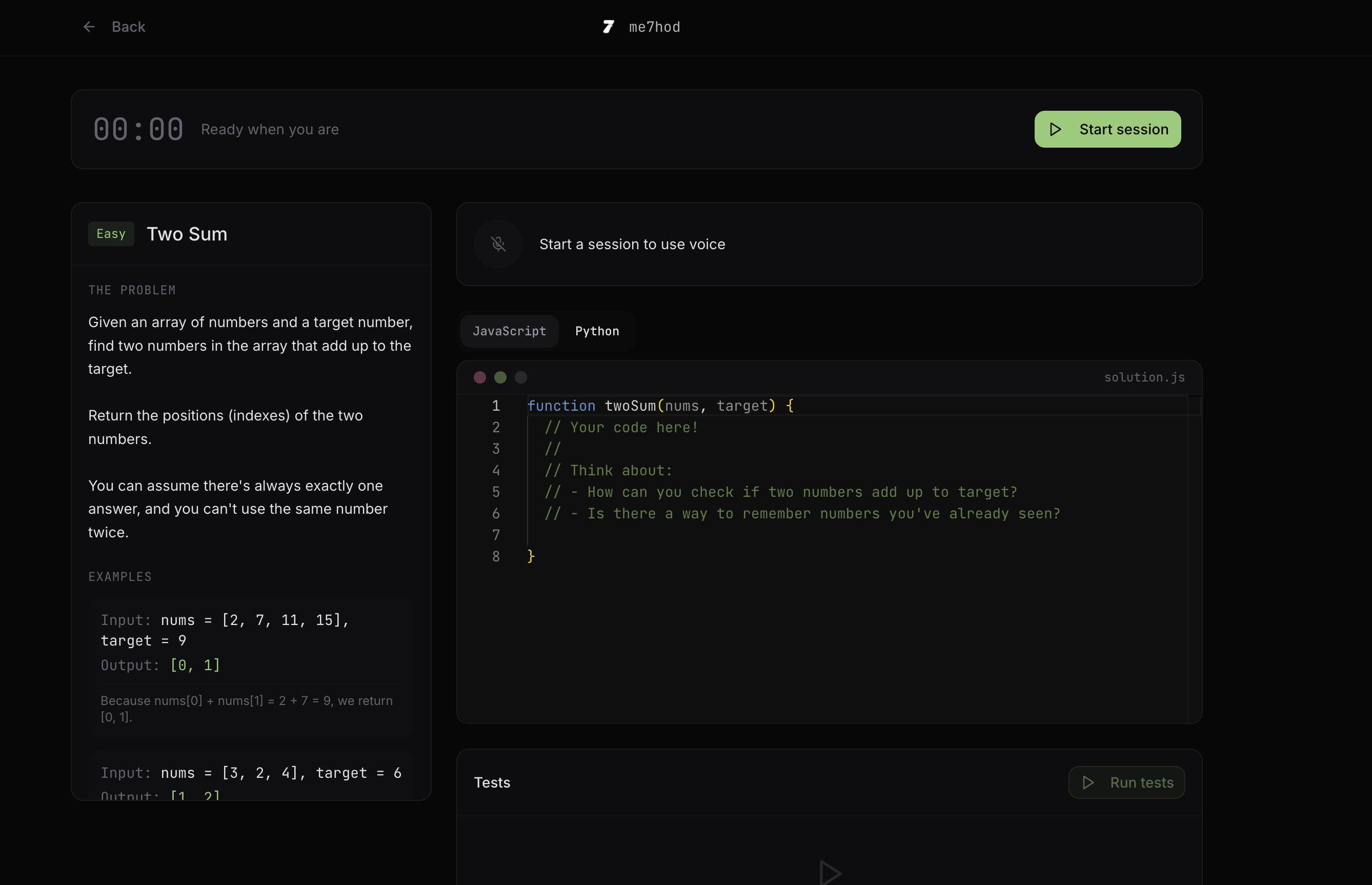
Assessment Page
Project Story
About the Project
me7hod.ai (SignalFlow) is a reasoning-required coding assessment platform. Candidates solve a coding problem while explaining their thought process out loud. The system captures their voice, summarizes their reasoning, runs their code, and produces a report that grades both reasoning and code—so hiring decisions reflect understanding, not just a correct answer.
What Inspired Us
We built this because we noticed how flawed the current technical interview process is.
- Proctoring isn’t enough. Platforms like CodeSignal and HackerRank use proctoring, yet candidates still find ways to cheat—copy-pasting solutions, using external help, or sharing answers. Proctoring alone doesn’t stop it.
- Grading is one-dimensional. Most assessments grade only the final answer (did the code pass the tests?). They ignore how the candidate got there: reasoning, trade-offs, debugging, and communication. That rewards people who can look up a solution without understanding it.
- Unfair and noisy signals. When hiring is based purely on "did it pass?", everyone doesn't get a fair shot. Strong thinkers who make a small bug get penalized the same as someone who pasted code they don't understand. Companies miss great engineers and sometimes hire people who can't reason under real conditions.
We wanted a more robust and honest grading platform so that:
- Everyone has a fair chance—reasoning is visible, not hidden.
- Companies hire the best engineers—those who can think, explain, and code—not just those who can produce a passing output.
So we made reasoning mandatory: you have to explain what you're doing while you code. The system records that, summarizes it, and scores both your thought process and your code. Cheating is harder when you can't submit code without showing your reasoning.
How We Built It
- Stack: Next.js 15 (App Router), React 19, TypeScript, Tailwind CSS, Prisma with PostgreSQL (and Prisma Accelerate). Monaco Editor for the code editor; OpenAI for summarization and report generation; ElevenLabs for speech-to-text (STT).
- Flow:
- Candidate opens the practice page, sees a problem (e.g. Two Sum) and starter code.
- They code and talk through their reasoning; we capture voice via STT and store transcript chunks.
- They can Run/Test (JavaScript in-browser, Python via a server-side harness).
- On "End session," we run a summarizer (e.g. ( \text{gpt-4o-mini} )) over the transcript to get a concise picture of their reasoning, then a report model (e.g. ( \text{gpt-4o} )) that outputs a structured report: thought process (e.g. "Thinking" rating) and code (e.g. percentage of tests passed).
- The report is shown in a modal so both dimensions are visible—reasoning and code—instead of a single pass/fail.
We kept the MVP scoped: one problem, no login, no AI interviewer—just "explain while you code" and an honest, dual-score report.
What We Learned
- Reasoning as a signal: Making reasoning explicit (voice → transcript → summary → report) surfaces understanding in a way that code-only scoring cannot. Even when code fails, strong reasoning shows up in the report.
- Integrity by design: Requiring spoken reasoning raises the bar for cheating; it's much harder to fake a coherent thought process in real time than to paste code.
- Trade-offs: We learned where to use lighter models (summarization) vs. stronger ones (final report), and how to keep latency and cost reasonable while still producing a useful report.
Challenges We Faced
- Docker + Prisma: The app's
postinstallrunsprisma generate, but in the Dockerfile we runnpm cibefore copying the rest of the repo—so the Prisma schema wasn't in the image yet and the build failed. We fixed this by copying theprismadirectory beforenpm ci(or by movingprisma generateto afterCOPY . .). - Database on serverless: We started with SQLite; Vercel serverless doesn't support it well. We migrated to PostgreSQL with Prisma Accelerate and set
DATABASE_URL(and optionallyprisma generate --no-engine) for production. - Python execution on Vercel: Our Run/Test supports Python via a small harness and
spawnSync; Vercel's runtime doesn't havepython3by default, so we had to handle "Python not available" gracefully (e.g. 503 or a clear message) or reserve Python execution for Docker/self-hosted. - LLM and API keys: We had to ensure
OPENAI_API_KEY(and laterELEVENLABS_API_KEYfor STT) were correctly set in.envand in deployment (e.g. Vercel); missing or invalid keys caused silent fallbacks or quota errors that we debugged by checking env and usage. - Report design: Deciding how to combine "thought process" and "code" into one report (e.g. separate scores, wording, and weight) took iteration so that the output is fair and interpretable for hiring.
Future Vision
This is an MVP. We're building toward:
- Video monitoring — Proctoring and attention detection during the interview so you know candidates are focused and present.
- Voicebot that conducts real technical interviews — A voicebot that talks back and forth with the candidate: asking follow-ups, giving hints, and probing reasoning—just like a live technical interviewer.
- More LeetCode-style problems — Integration of many more problems beyond Two Sum—arrays, trees, graphs, and more—so assessments match your bar.
Today's product is a minimal version; these features are on the roadmap.
Summary
We built me7hod.ai to make technical assessments fairer and more honest: by requiring and grading reasoning as well as code, we give everyone a fairer chance and help companies hire engineers who can actually think—not just those who can produce a correct answer under proctored-but-cheatable conditions.
Built With
- docker
- elevenlabs
- jest
- next.js
- openai
- postcss
- postgresql
- prisma
- python
- radix
- react
- tailwindcss
- typescript
- vercel











Log in or sign up for Devpost to join the conversation.