-
-
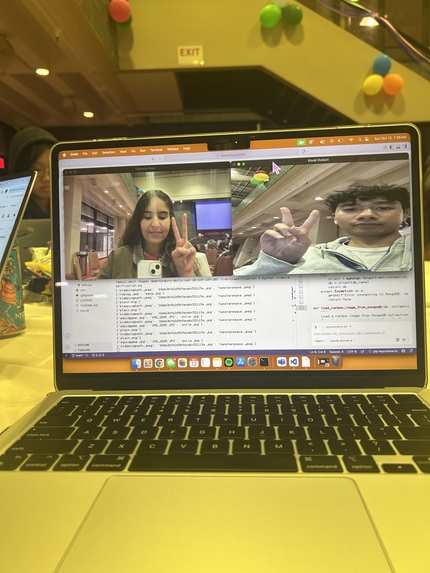
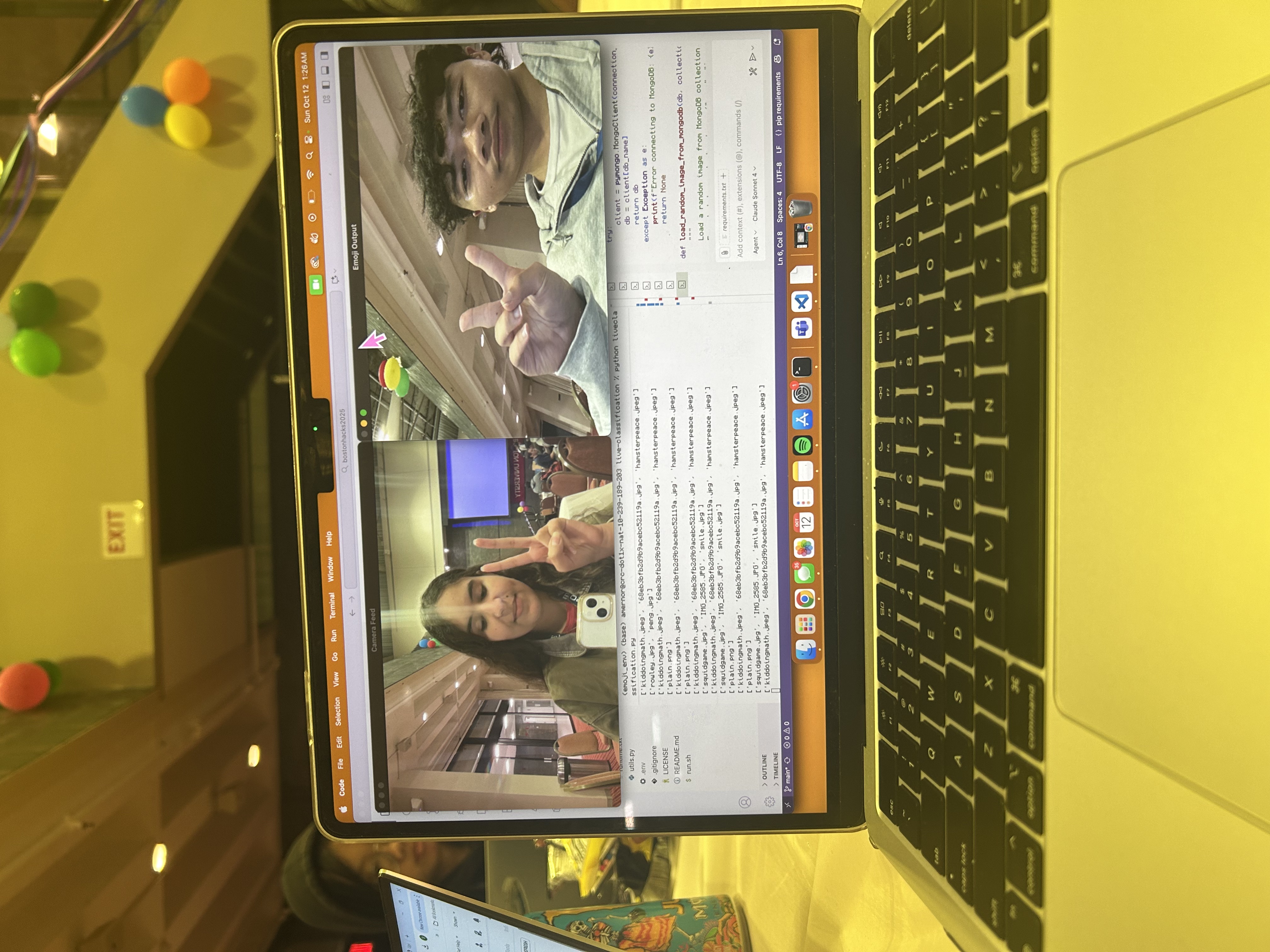
classification of peace sign!!!
-
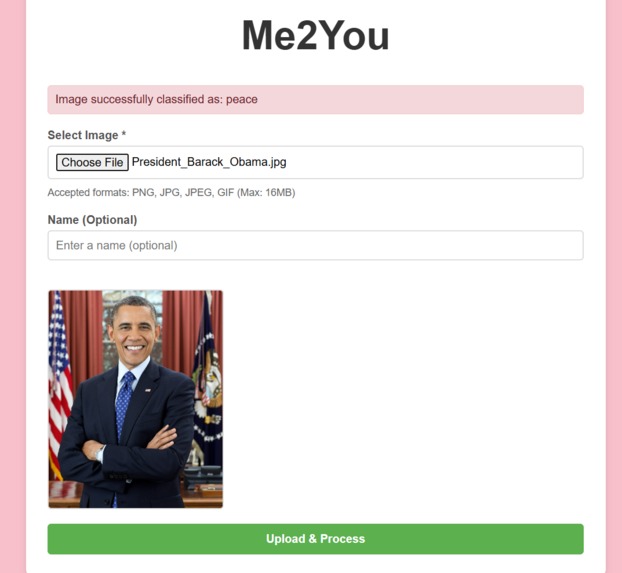
User Interface to upload image + message
-
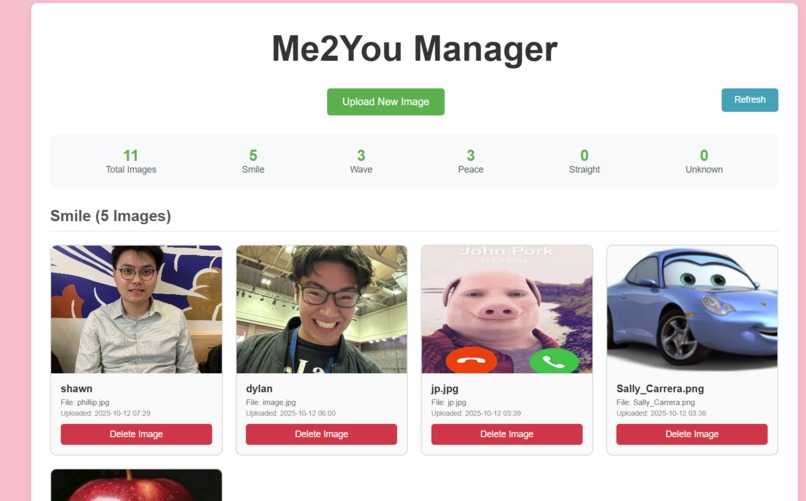
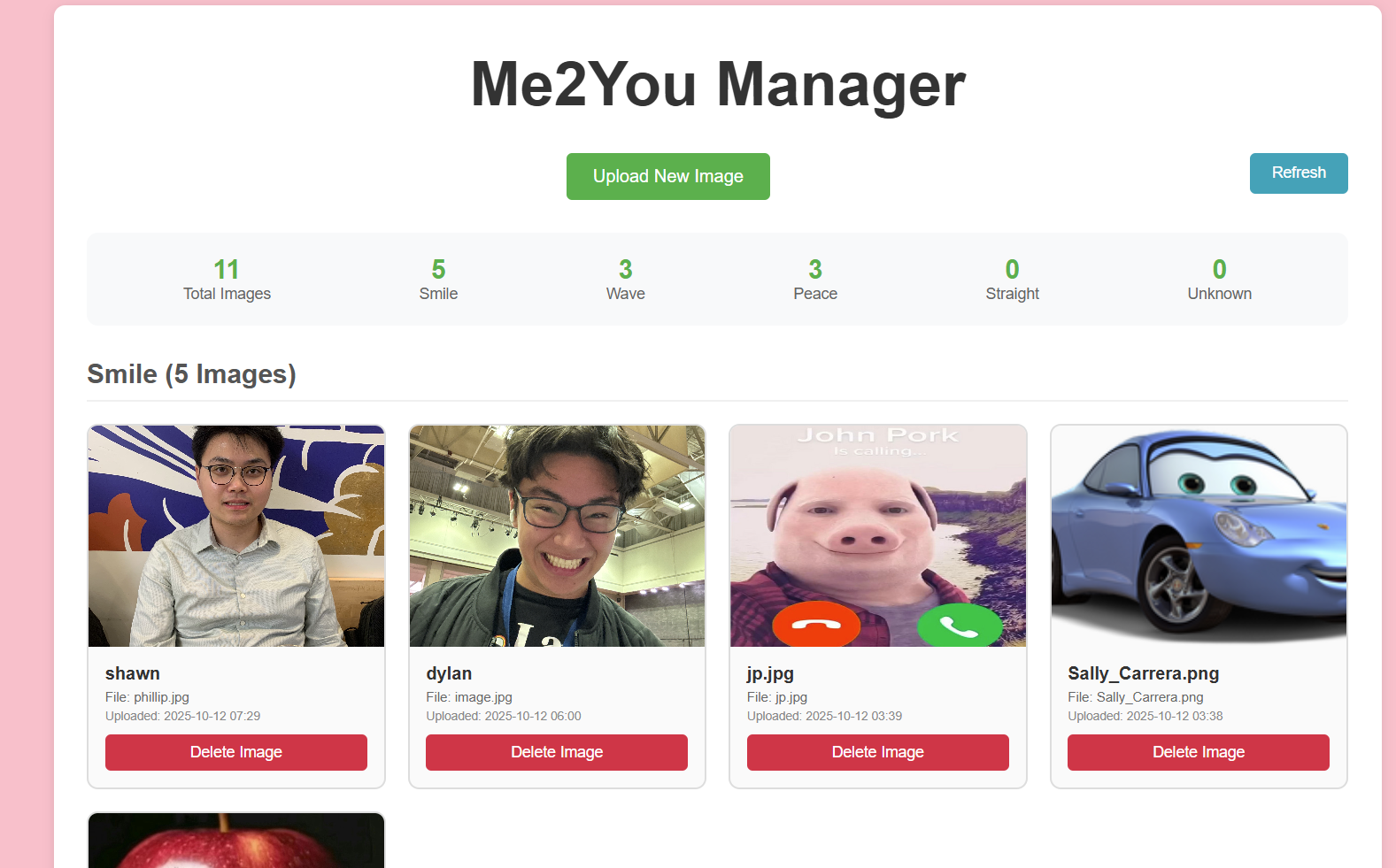
Uploads Manager to visualize classification

Inspiration
We wanted to have an interactive project where people in the community can play with computer vision, but also be able to have fun and interact with others! We first thought about classifying live faces to translate to memes… but we then thought— why not make it so you connect with others? (and still have a good laugh of course).
What it does
Our project transforms the SPARK! space in the CDS department into a playful, interactive community space. Users submit daily photos of themselves, and later, the system allows anyone in the room to interact with an expression-based display. When an expression or gesture is recognized — for example, a peace sign — the corresponding photo(s), the user’s name, and any user-submitted text appear on the screen. This creates spontaneous social interactions, encourages recognition among peers, and fosters a fun, collaborative environment.
How we built it
The project was split into two main parts: a frontend web app for user input, and a computer vision app for live interaction. The frontend and file handling for this project was created with a combination of Flask and MongoDB. We designed a basic interface for users to input images and names. From here, we broke down images into binary representations and passed them to a Python image classification model.
This model identifies four categories — happy, neutral, wave, and peace sign — from testing images. We set up a minimal file structure with classifier.py for model inference, utils.py for preprocessing and helper functions, and a tests folder with sample images and a test script. We used TensorFlow Lite with OpenCV to handle both human faces without training a custom model, adding a fallback to “unknown” for low-confidence cases. The initial model correctly detected faces.
After classification, these images and their newly determined classifications are passed to MongoDB. We then designed the live classification portion of the project.
For live classification, we used openCV, a computer vision package in Python. We used it to connect to a device's camera, classify faces moving in real time, and display a randomly chosen image that mirrored your given action. To differentiate between smiles and straight faces, and waves and peace signs, we used MediaPipe’s landmark features to classify those categories according to ratios between the corners of your mouth or angle of your fingers. From there, to be able to actually call these images and text inputs, we utilized MongoDB change streams to track image updates in real time, while also calling our users personal text added onto their submission.
Finally, we deployed the web app on Railway, to allow users to access the application and upload their images in real time.
Challenges we ran into
Initially, we wanted to include user-submitted emojis or memes in the package, but we discovered that the libraries and models did not tune very well to yellow, round blobs like emojis— or random memes. Because of this, we pivoted our approach and thought about how else people could interact within the SPARK! spaces, creating a far more interconnected image and facial detection system.
Some other challenges were trying to optimize the live detection system, as well as the submitted-image classification system. They took some different approaches and trial and error to find our best performance. We also had some issues
Additionally, implementing the live image update system was challenging. The original idea was to create a polling system, however this raised concerns of overpolling the database. Eventually we settled on Mongo change streams, which allows real-time updates anytime a new image was uploaded or deleted.
Finally, deploying the input web application portion was very difficult. Since part of the web app involves a classification model, this required the OpenCV Python library. Although this library was easy to install locally, deploying it on Railway was a challenge, since OpenCV requires system libraries like libGL, which most server providers do not have. After many unsuccessful deployment attempts, our solution was to use a Dockerfile to specify exactly the build environment for the deployment.
Accomplishments that we're proud of
We successfully built a lightweight image classification pipeline that can categorize user-submitted images as smiling, straight-faced, waving, or holding up a peace sign without needing a custom training dataset. We’re proud of how cleanly the system integrates pre-trained models and handles some edge cases, laying a solid foundation for future improvements. We are also proud of being able to store user inputted images into our database and be able to have it consistently update live in our program.
What we learned
We learned that using a generic pre-trained image classification model works decently for human facial expressions but struggles with emoji-style images, which don’t have the same facial features or gesture landmarks. We also saw how important good file organization is early on, since separating logic and different functionalities makes development much easier. We also learned a lot about handling edge cases in our user-input data, but also live input data. Finally, we learned much more about computer vision than we ever have, and have gained new skills using other libraries like MediaPipe that help better classification.
What's next for Me2You
Hopefully we can add more classifications! Everyone really wanted to try out a thumbs up, or maybe sticking your tongue out too. This also hinges on an increased dependability and reliability on the classification algorithm. With personalized training of images and an enhanced algorithm, it’s possible to make Me2You even more personalized and advanced. We would also improve the UI, maybe add different features like colors, designs, or gifs in the interface.


Log in or sign up for Devpost to join the conversation.