-
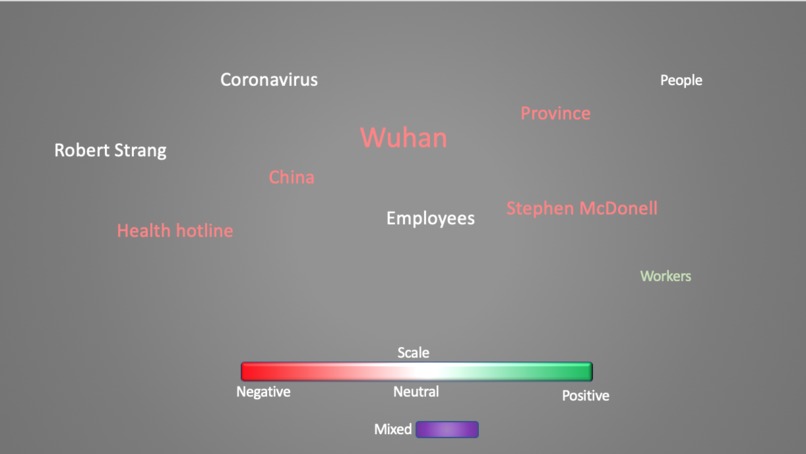
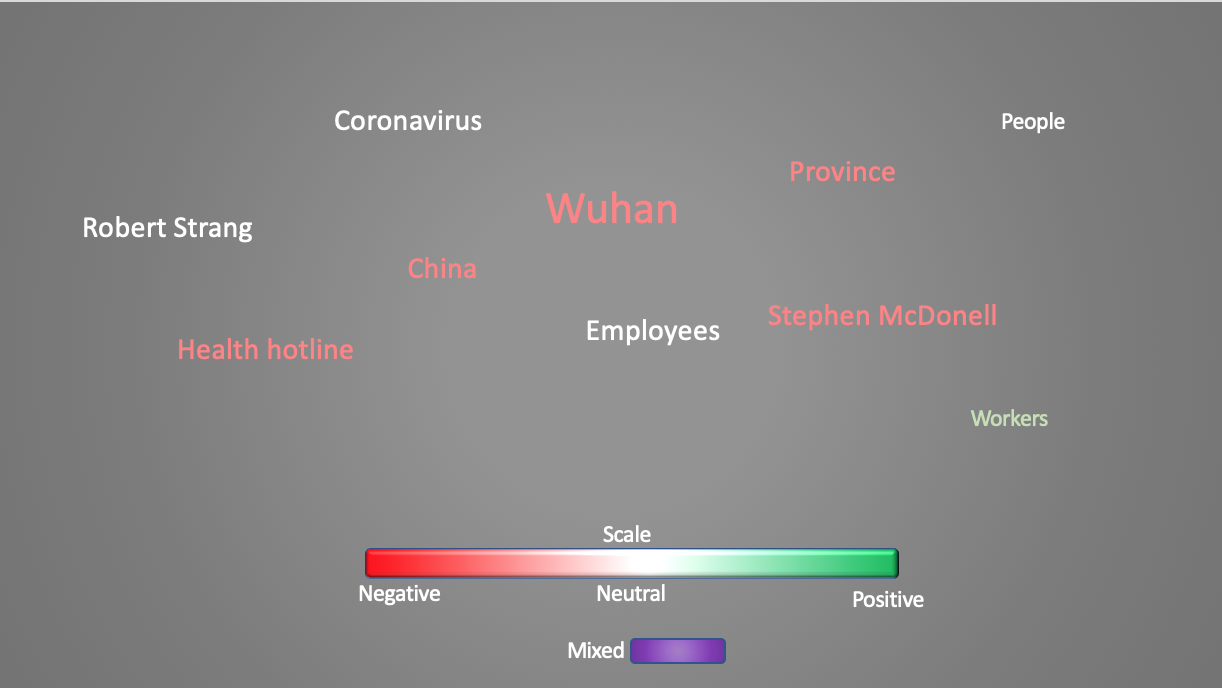
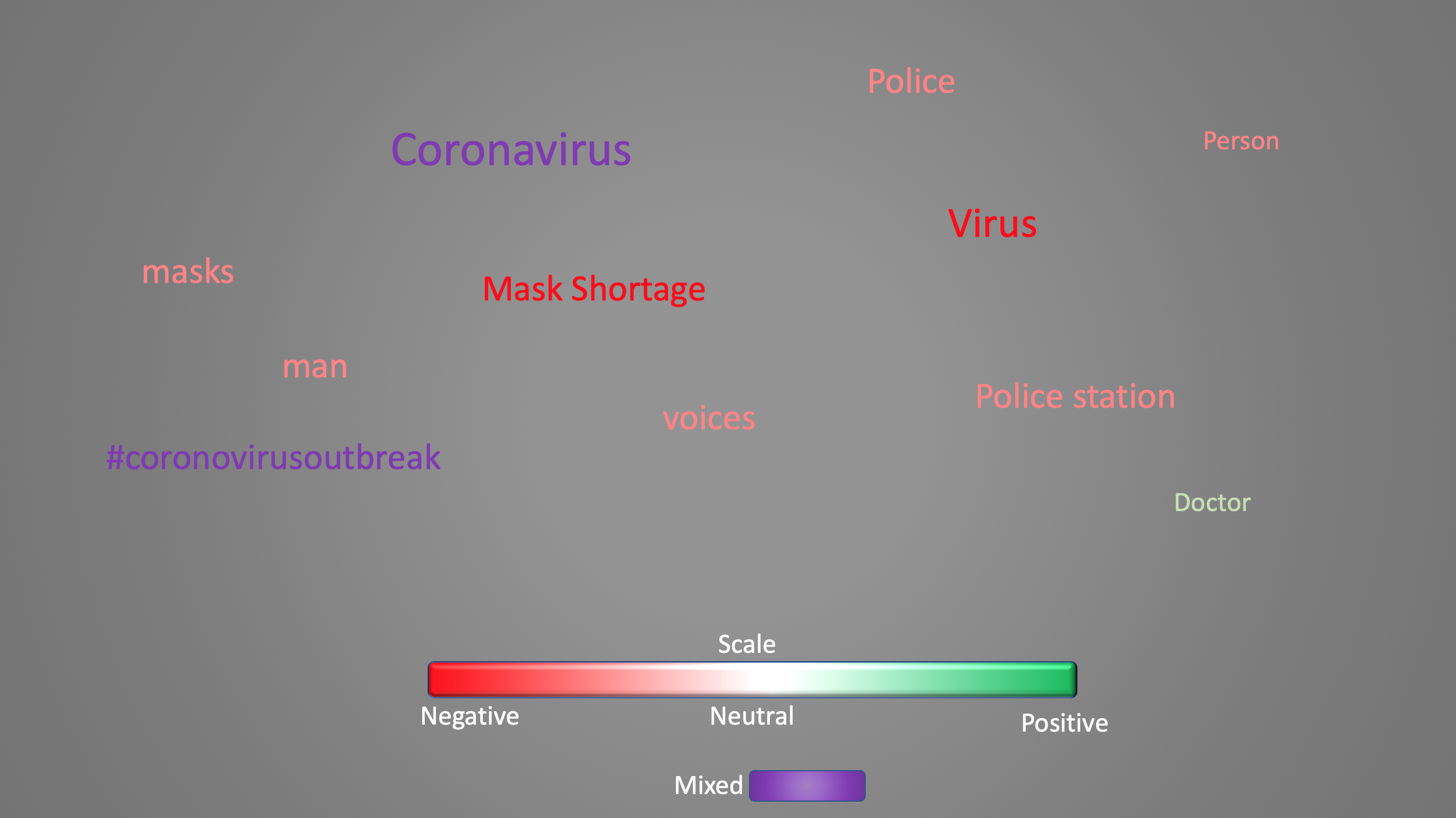
Coronavirus attitudes in News, processed by NLP algorithm
-
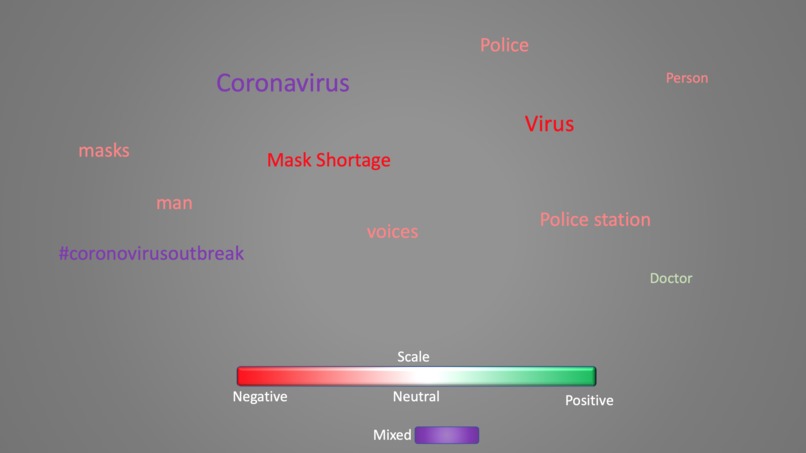
Coronavirus attitudes on Twitter, processed by NLP algorithm
-
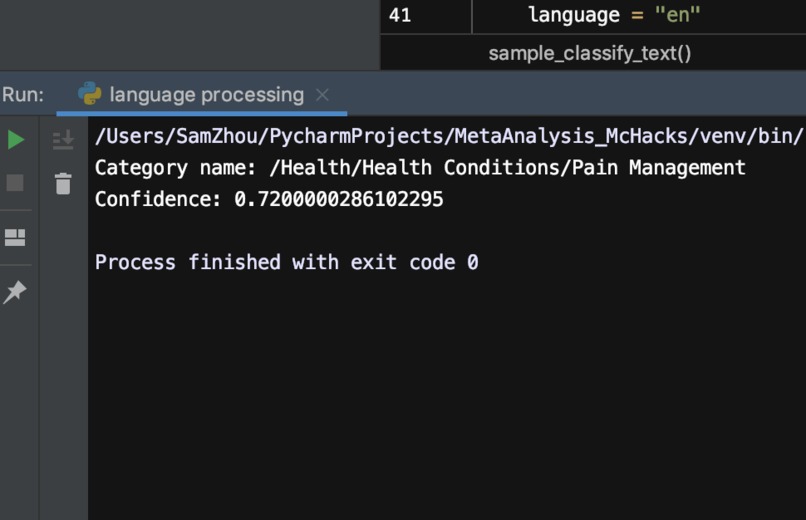
NLP algorithm on Journal Article (https - website)
-

NLP algorithm on Journal Article (text file)

Initial Idea
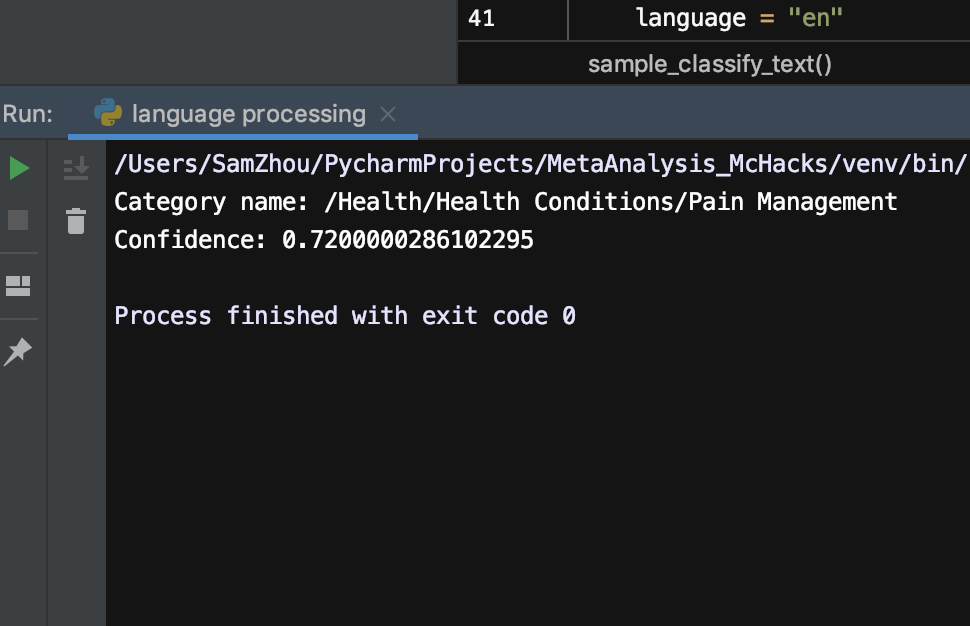
There were two ideas at first. One was to construct a Natural Language Processing (NLP) algorithm to look at successfulness of treatments in Randomized Controlled Trials (RCTs), accessible via PubMed, and the other was to analyze properties of scientific literature published within a certain time period in one type of journal to visualize information such as type of study, subject characteristics, etc. However, these ideas were not the most compatible with NLP as the categorizations were often too general.
Inspiration for Change
Roadblocks tend to spur inspiration, and that was what happened here. One of our biggest challenges was linking the API to Python, we tried to use the IBM Natural Language Understanding API at first but after many failed attempts decided to switch over to the Google Natural Language API. But after we finally managed to get it to work, the categorization of journal article data fed into the algorithm was extremely broad. Thus we decided to adjust the project to a topic that was more suited for this NLP API. Seeing as how the impact of the recent coronavirus outbreaks are still highly salient for many people's everyday lives, we decided to look at the media attitudes towards the topic with the NLP algorithm. We adjusted the NLP algorithm to look for entity sentiment instead of classification.
Learning is the Journey
In this McHacks we definitely learned a lot in the process of creating this project. We came from various fields of study with varying levels of experience. For half of us it's our first Hackathon! But within these 24 hours we managed to learn how to extract information from a website, implement a NLP algorithm with a Google API, and analyze data generated by these algorithms. Overall we learned a lot from this experience and created an exciting and socially relevant algorithm for analyzing attitudes for a topic in media.
Built With
- google-natural-language-api
- natural-language-processing
- python




Log in or sign up for Devpost to join the conversation.