Overview
This Web App predicts the performance of your movie/TV-show based on its analysis of over 300,000 IMDB titles.
Acknowledgements
Special thanks to Rick and Li of the McGill AI Society. This project won't have gone this far without their tips on encoding high-cardinality data and presenting this model. :D
Credits to IMDB for the datasets.
Showcase
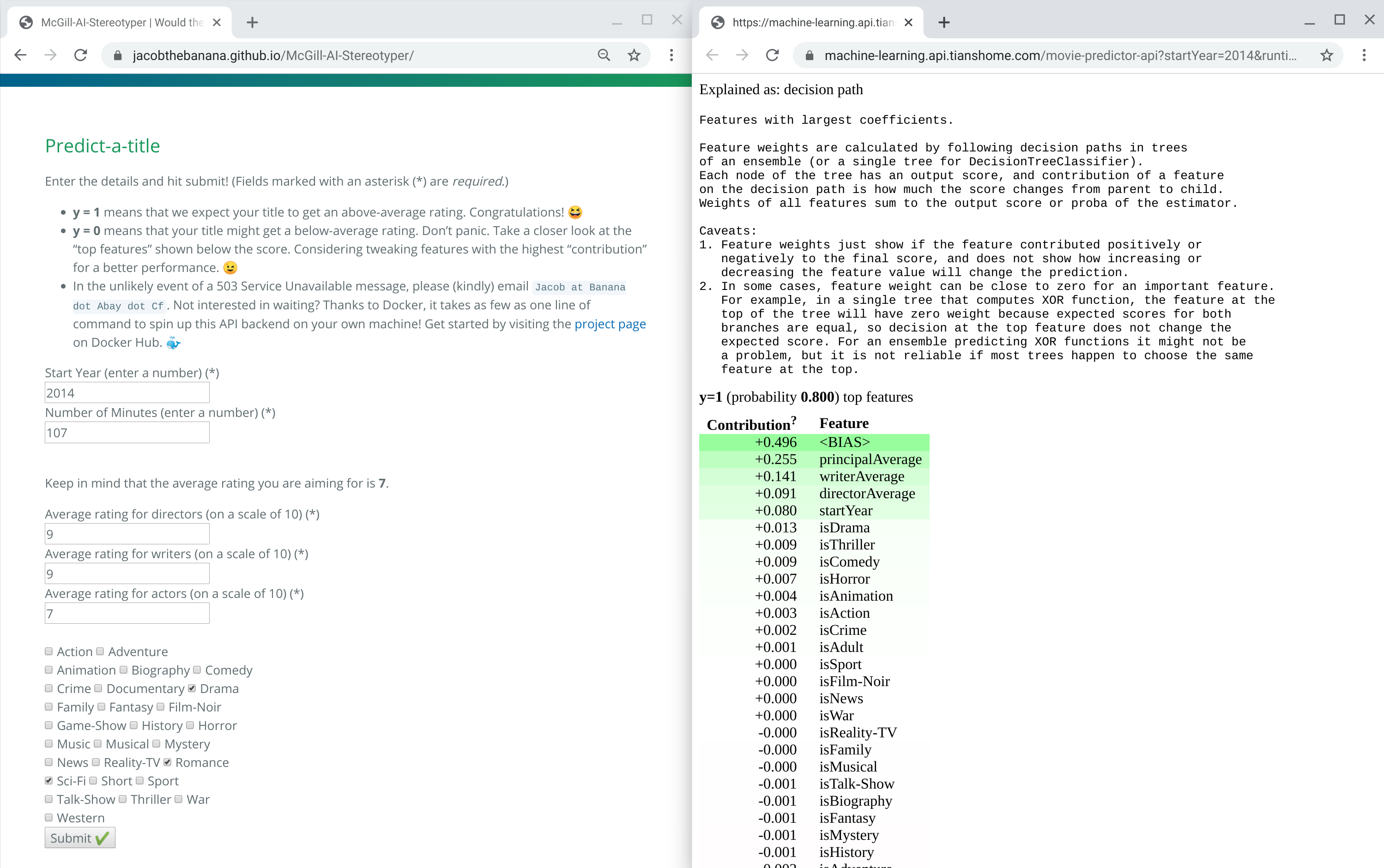
Prediction for the Giver (2014)
The 2014 movie "The Giver" (based on Lois Lowry's Newberry-winning novel, one of my all-time favorite read) received a below-median rating of 6.5 out of 10 (the median rating is 7 out of 10.) IMDb: tt0435651.
- Director: Phillip Noyce (nm0637518). The average rating for his titles is approximately 6.742693.
- Writers: the average rating for titles of these three writers is approximately 6.9058.
- Michael Mitnick (nm2276729) received an average rating of approximately 6.689943 for his titles.
- Robert B. Weide (nm0004332) received an average rating of approximately 7.527469 for his titles.
- Lois Lowry (nm0523342, author of the Newberry-winning novel) received an average rating of approximately 6.499987 for her titles.
First three Principals: the average rating for titles of these three principals is approximately 6.936133.
- Nikki Silver (nm1012185, producer) received an average rating of approximately 6.55559 for her titles.
- Brenton Thwaites (nm4154798, as Jonas) received an average rating of approximately 6.60018 for his titles.
- Jeff Bridges (nm0000313, as the Giver) received an average rating of approximately 7.887843 for his titles.
Year: 2014.
Length: 97 minutes.
Genres: Drama, Romance, Sci-Fi.
Prediction: y=0 (probability 0.900) (in other words, the auto-classifier is about 90% sure that the movie will receive a below-average rating.) Here's the link to a detailed analysis of this conclusion.
The Autoclassifier Model
These resource-intensive computations were performed in Google Colab.
Pre-processing
(Check out the notebook.)
The input comes in multiple datasets. The first step to do is to load and merge them into a single dataframe.
The next step is to discard some of the unused features such as names and multilingual titles.
The notebook would then condense the actor, writer, and director data by taking the average rating for each of the actor. (Thanks to Li from the McGill AI society for the tip.) Entries where such data are unavailable were discarded.
The dataframe is then pickled and stored as titles-with-ratings.pkl.
Fitting
(Check out the notebook.)
The pickled dataset is loaded and further processed. The genre information is converted to a multi-label binary representation. The rating is split into two categories: below average and above average. That categorical information is represented as a scalar number (0 or 1) because that seemed to be the simplest way to get ELI5 to work with the verrsion-1 model.
A 10-estimator random forest auto-classifer (from Scikit-Learn) is fitted onto the training dataset (more than 300,000 entries.) With only 10 decision "trees" in the "forest" (i.e., 10 estimators,) the model achieved a test accuracy of around 80% while using only about 500 MB of RAM. Adding 20 more estimators would improve the test accuracy by less than 1%. That was deemed not worthwhile, for adding 20 estimators would more than double the RAM requirement and make the model more costly to deploy to the cloud.
The model is then dumped to a joblib file.
The Webapp
Frontend
The frontend of this Webapp is simply an HTML form embedded in a markdown document. That markdown document is then styled and published using Github Pages.
Behind the scene: why's the averages 9-9-5 by default? What about the length, year, and genre? A movie with the default 9-9-5 setup would likely be below the average of 7.That would (supposedly) encourage kids to explore the interactive Webapp and see how various features contribute to the conclusion. On the other hand, the genres, year, and runtime are chosen specificall in honor of the 2014 Drama, Romance, and Sci-Fi movie "The Giver" (based on the Newberry-winning Lois Lowry novel.)
Backend
A Flask App listens for GET requests to the API address. Once a request arrives, the Flask app would scan through its arguments and fill in any missing blanks with default values. The Webapp would beep (with a 400 Bad Request) if any of the required values is missing.
The user input would be converted to a Pandas dataframe and fed into the autoclassifier. The explanation is part of an SEP®️ (Someone-Else's Problem) and is handled with the ELI5 library. Displaying the explanation in HTML, yet another SEP®️, is handled by asking ELI5 to render the eli5.explanation object in HTML, and directly returning the rendered HTML object to Flask.
Note that the model (in Joblib format) is loaded into RAM immediately at the start of the Flask App.
Other practical stuff
Reverse Proxy & SSL Gateway
An Apache2 (Ubuntu) web server acts as the SSL reverse proxy gateway for the backend. This gateway is hosted on Amazon Lightsail in Montreal and is proudly Canadian.
Containerization
The backend is turned into a Docker image. With the help of docker run, it takes as few as one line of command to spin up an instance of this API backend.
Log in or sign up for Devpost to join the conversation.