-
Home Page of our app called Matra AI
-
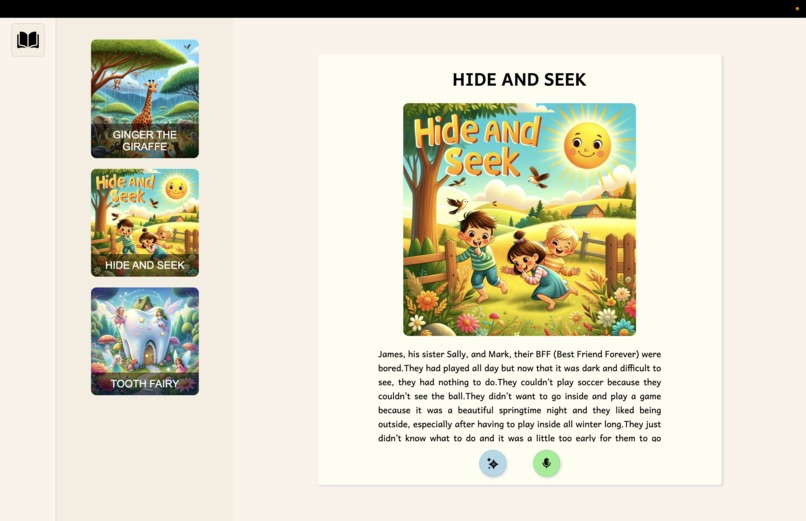
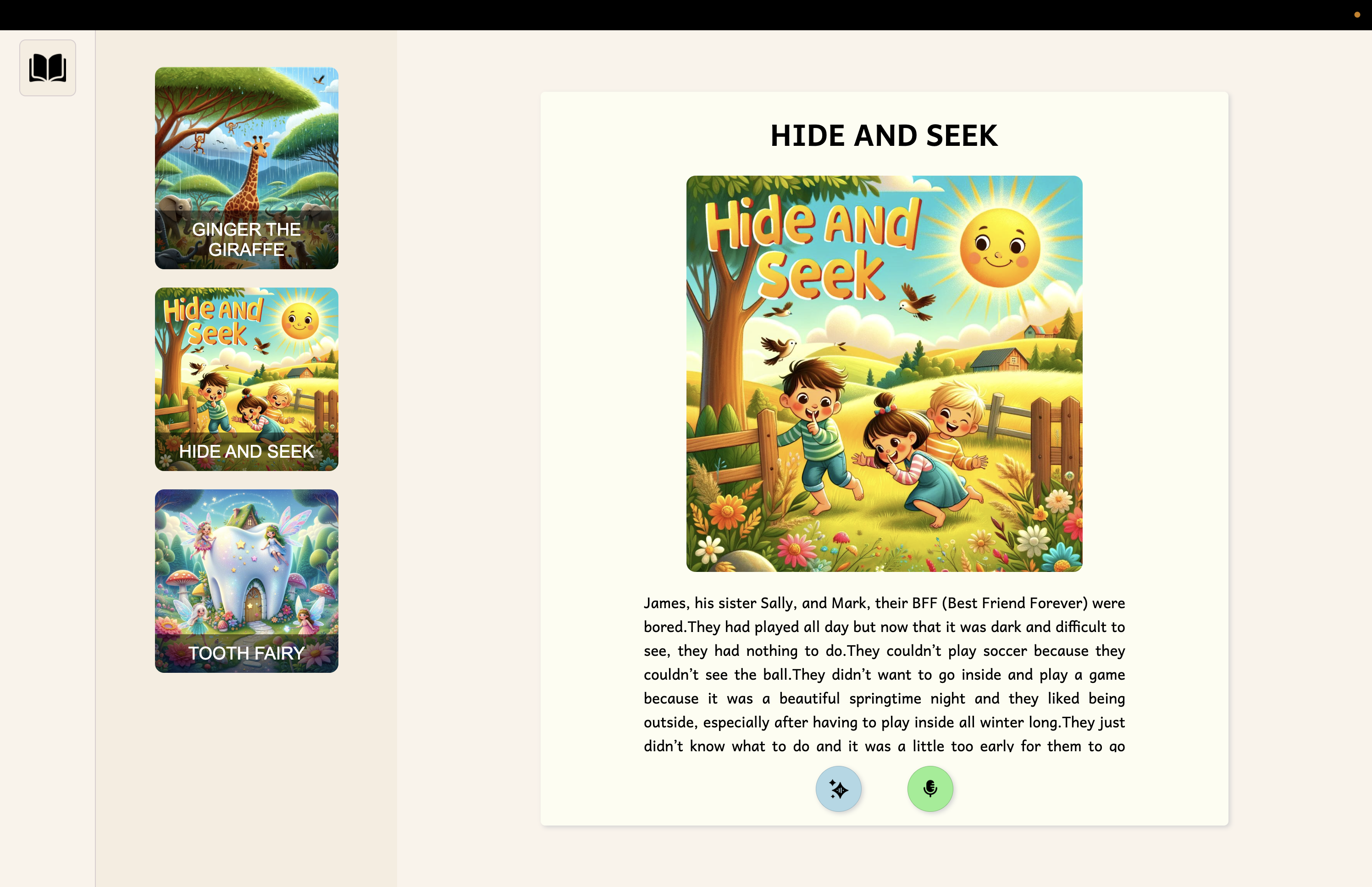
Screenshot of our working web application
-
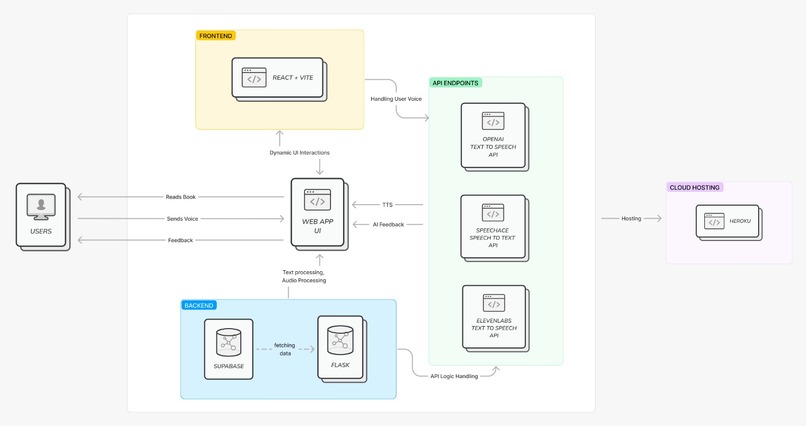
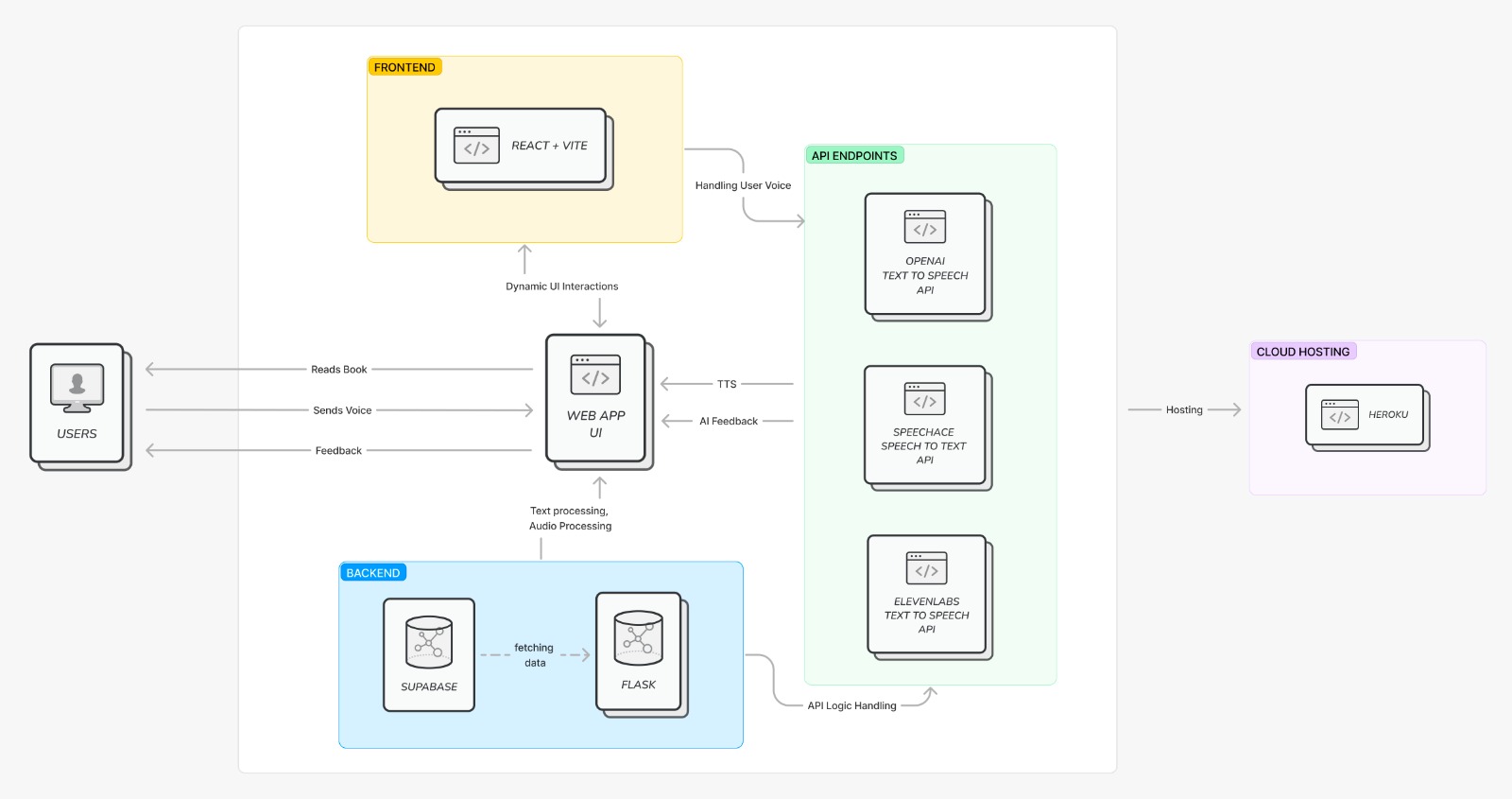
Picture of architecture of our application
-

Picture of us coding and keeping the ideas flowing with lots of coffee

Inspiration
We live in a neighborhood where we meet a lot of Spanish Families. the often talked about problem is how kids face the difficulty to learn/understand languages being taught in classroom. One of our teammate was a kinder-garden teacher and he explored this problem, where he taught kids how to enjoy the process of learning the language by reading picture based short stories. We came across this problem back in India as well, where kids wanted to learn the language but didn't have proper resources to learn the right pronunciation which was fun and easy. We identified this problem, that irrespective of where the kids are from, the problem of learning a new language at a quite early age can be challenging. Solving this problem early on, makes the kids become confident orators. We took this as our inspiration to build an application with the current AI technology and make the process easy and fun to the leaders of our future.
What it does
The user selects a book of his favorite choice. The AI reads a sentence and prompts the user to read the next sentence, and the application then compares the audio files of both the actual sentence audio with the correct pronunciation and the one the user spoke, our AI analyzed both files and then gives the result of how correct the pronunciation of the words were. The user can choose any sentence to read and the AI will tell what was wrong with the pronunciation or give a positive feedback and move on to the next sentence.
How we built it
The backend is built using Flask and our beautiful frontend is made in React. The server is powered by chatgpt-3.5-turbo and uses ElevenLabs for Text-To-Speech to bring out the motherly, nurturing and caring voice of Sophia. For Speech-To-Text, we made use of Speechace API to get the statistics on the pronounced sentence by comparing it with actual sentence and this statistic is preprocessed in python and then fed to OpenAI to get response and suggestions on how to pronounce the words which were mispronounced. This response is then again converted into speech using Elevenlabs API for our Sophia to read it. and all of this database is saved in the Supabase
Challenges we ran into
We faced a lot of roadblocks while making this application. One of them being finding the APIs required for our exact use case. Initially, we tried to convert the speech to text and then compare it to actual text but every api auto-corrects the translation and it cannot be compared in terms of text. Fortunately, we found the an API which gives statistics on the pronounced word from the sound of phonetics, stress level, syllables and many more. The backend team was able to pre-process that and feed it to LLM for analysis with actual sentence to get us the suggestions we need for the app. We also faced many other challenges but I guess all we needed was huge load of research and many more shots of espresso.
Accomplishments that we're proud of
We are proud of building an end-to-end application from scratch within the allocated time. The application we have built now is far ahead of the existing applications out there. We achieved a human like audio. We learnt a lot about Speech-to-text and all the technologies we used to build, as we all team members were proactive in communicating what has been done and built, so we got a chance to learn each other's tech expertise.
What we learned
This is our first hackathon ever. We finally were about to build a complete application, made new friends. Deciding early on what to work on, what goals and milestones to achieve, helped us divide the tasks. we faced quite a bit challenges, and we are glad we overcame them thanks to the mentors, who are always available to help us. Coming to the Technical details, we learned a lot about speech-to-text models, APIs and its integration, as it is overlooked compared to speech-to-text, we wanted to build an AI that sounds calm and as human as possible. We thank hackdavis for this oppurtunity
What's next for Mātrā AI
We plan to take this product to different parts of the world. As we believe this product is scalable. We plan to include different languages where kids can learn other language pronunciation and from different parts of the world. We plan to build our own AI model to train the speech-to-text and text-to-speech where we can give better voice selection such as user's favorite voice character to read the books and overall accuracy of the analyze the AI does. we also plan to increase our database by including more books for different age group of kids, such as harry potter, the wizard of oz etc.






Log in or sign up for Devpost to join the conversation.