-

Putting the LaTex Code I parsed into a LaTex compatible editor to see the conversion.
-

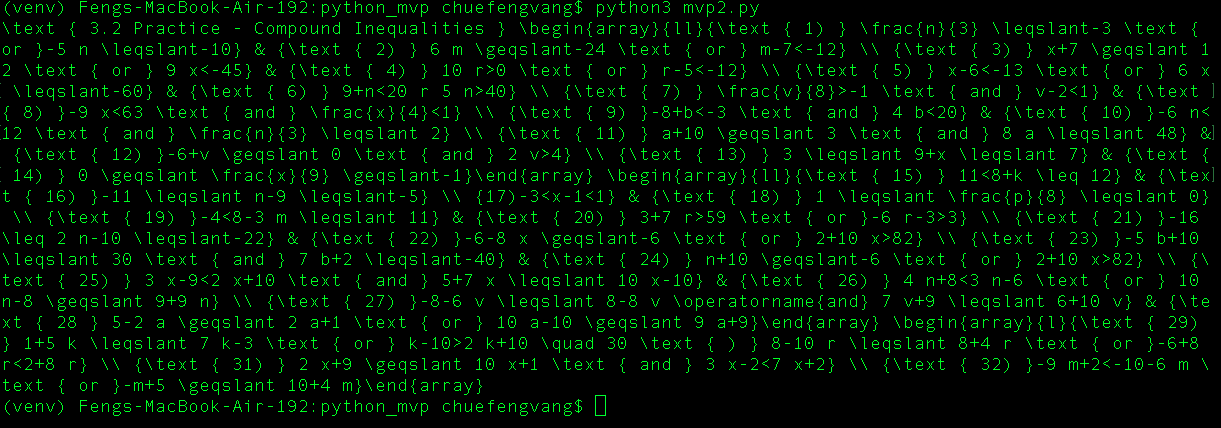
Raw LaTex syntax received from parsing the image.
-

Original test paper that was used for reading.


Inspiration
I was amazed when I saw how accurate and quick Mathpix was during the opening presentation. It caught my eye because of the possibilities it could lead to, and building on top of the API today showed me how great the potential is for this technology.
What it does
Mathpix is a great piece of software that is able to detect text AND handwriting and turn it into LaTex, a mark up language, where it is then printed on to the screen for digital use. What I created was a program that took the Mathpix API and made it so instead of being able to only parse a couple lines of writing, it is now able to scan through a whole PDF page and convert that into LaTex. No more having to manually partition the photos yourself.
How I built it
The program was built with Python, and utilized many python libraries such as json, pdf2image, PIL, and more.
Challenges I ran into
I had no knowledge of what LaTex was going into this, and minimal idea of how to even work with JSON and APIs. I was also in a team by myself, so I was short on manpower, data processing, and skills.
Accomplishments that I'm proud of
I am extremely proud of being able to learn so much about JSON, APIs, and LaTex, but most of all I am happy that I was able to create an application that satisfied the hacking criteria all by myself.
What I learned
Aside from the bigger pieces of code that I mentioned earlier, the biggest take away from this project was reading and understanding library documents and sample code. Without these I would have been no where.
What's next for Math Pix PDF Full Scan
I really wanted to incorporate OpenCV OCR and have the text be partitioned in a more precise and mathematical way, but it was out of my scope at the moment. With more time I would add functions that reduce the time complexity because the program is just a bit too slow for my liking.


Log in or sign up for Devpost to join the conversation.