-
-
Test_1
-
Patients
-
Arquitecture
-

Multilingual
-

Cover
-
Trust FHIR
-

Postpartum_watch
-

Pregnancy_AI_care




Inspiration
The U.S. has the highest maternal mortality rate in the developed world, and most of those deaths are preventable. Black women die from pregnancy related causes at three times the rate of white women. Rural mothers travel hours to see an OB. Spanish speaking moms get postpartum education in a language they cannot fully read.
We wanted to ship something that could plug into a real EHR, ground every recommendation in a published guideline, and meet a clinician inside the workflow they already use.
What it does
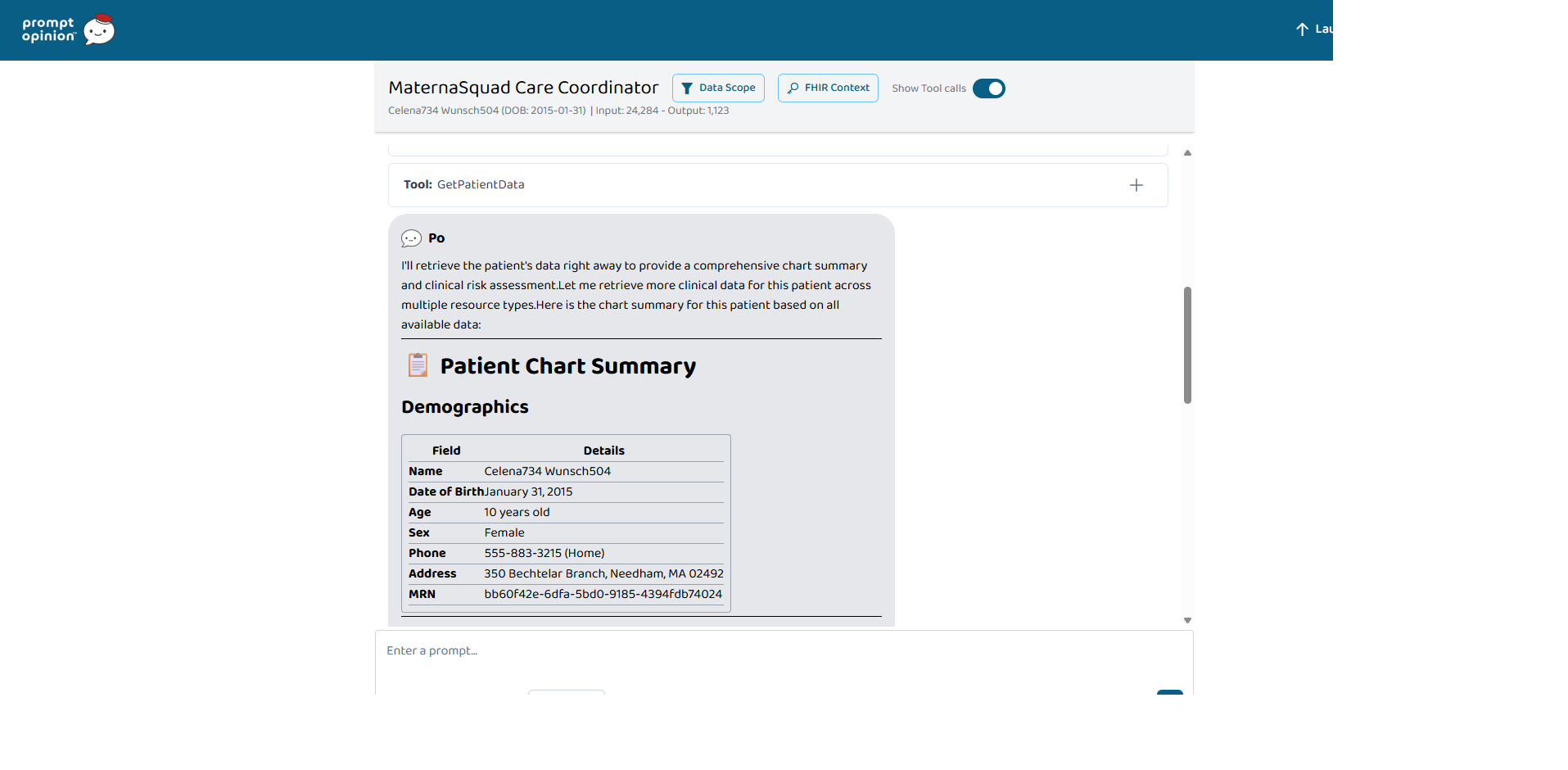
MaternaSquad is a five agent system that surrounds one expecting or postpartum mother:
- Risk Agent scores preeclampsia, gestational diabetes, and preterm birth risk against ACOG and USPSTF rules.
- Coverage Agent drafts Da Vinci PAS shaped prior authorization evidence packets.
- Education Agent writes teach back patient education in the mother's preferred language.
- Postpartum Watch triages CDC Hear Her warning signs.
- Orchestrator routes the clinician's natural language question, fans out to sub agents, and merges the answers into one SBAR summary.
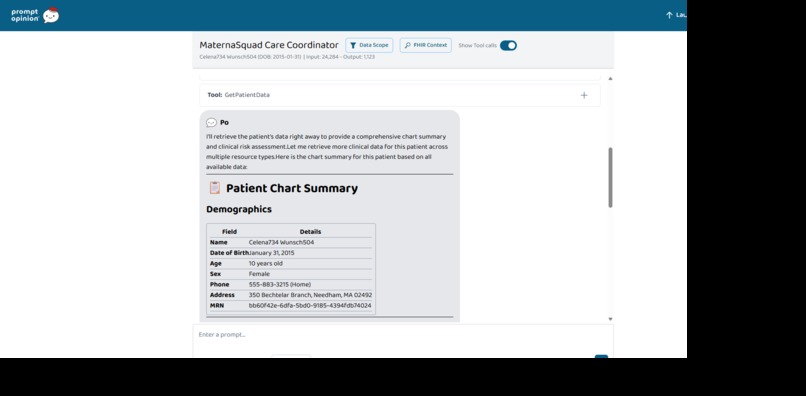
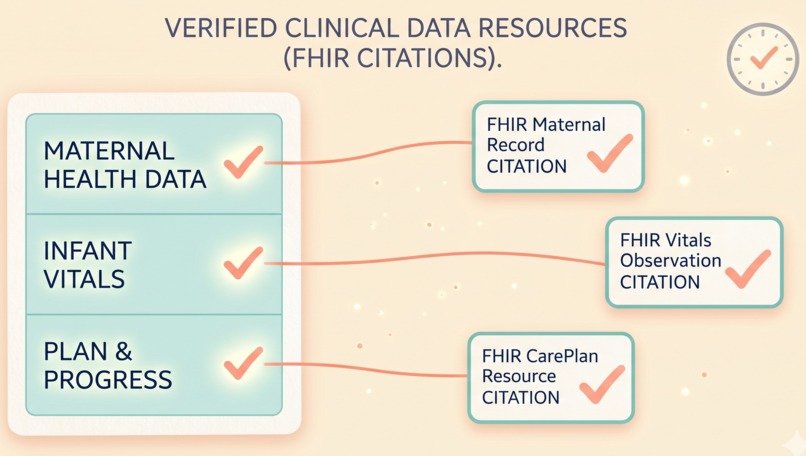
All five agents share one MCP server with eight clinical tools that read FHIR R4 records, run the rule based scorers, translate patient messages, and write an audit trail. Every clinical claim is cited to the source FHIR resource, and every step is logged.
We tested the system against three Synthea generated personas: Aisha (Detroit, preeclampsia), Sofia (Houston, GDM, Spanish locale), and Jordan (rural Kentucky, mental health).
How we built it
- Python 3.11 backend, FastAPI for each A2A agent, FastMCP for the shared MCP server over streamable HTTP.
- Claude Sonnet 4.6 (Anthropic API) for all reasoning, with adaptive thinking and forced tool use for structured outputs (a Pydantic schema is converted to a JSON schema tool,
tool_choiceis pinned to that tool, and every response is validated before it leaves the boundary). - HAPI FHIR R4 for the data tier, in Docker locally and on Cloud Run for the demo.
- Synthea generated the three personas. No real PHI ever.
- SHARP healthcare context (patient ID, FHIR URL, locale, trace ID) is propagated as HTTP headers across every agent and every MCP tool call, so the same patient stays in scope through every hop.
- Google Cloud Run, Cloud Build, Artifact Registry, and Secret Manager for deploy, all driven by one idempotent PowerShell script.
- structlog writes one JSON line audit entry per tool and agent invocation. Trace ID, actor, action, patient ID, and FHIR references. Never the resource body.
The Risk Agent uses deterministic rule based scorers; Claude provides the narrative interpretation only. This keeps the system inside the four 21st Century Cures Act non device CDS criteria so it stays out of FDA SaMD scope.
Challenges we ran into
- MCP transport drift. FastMCP 3 returns
result.structured_contentas the plain dict, whileresult.datais atypes.Rootwrapper. Our agents were reading the wrapper and getting empty objects until we swapped the priority. - Synthea bundle ordering. Patient bundles reference practitioners by conditional URL, so hospital and practitioner bundles have to load first. We added a two pass loader.
- Citation guard. The orchestrator's clinician summary kept falling back to generic text because the model was not emitting
[ResourceType/id]tokens, even though the sub agents returned correct citations. We rewrote the summary prompt to list the extracted FHIR resource IDs explicitly, and made the citation requirement conditional on whether any sub agent actually returned references. - PowerShell on Windows. A
2>&1redirect on a native exe in PowerShell 5.1 wraps each stderr line in an ErrorRecord and sets$?to false even when the exe returned 0, which broke our Java detection during Synthea generation. Fixed withGet-Command javapluscmd /c. - Cloud Run deploy. First pass had Gemini and Vertex references left over from an earlier prototype, plus a chicken and egg between the orchestrator and its sub agent URLs. We rebuilt the pipeline so HAPI deploys first, Synthea bundles load via curl from Cloud Build, and the orchestrator gets the real sub agent URLs in a second pass.
Accomplishments we are proud of
- One MCP server, five agents, one audit trail. Six clean Marketplace listings, no duplicated logic.
- Every clinical claim is grounded in a FHIR resource ID. The audit log is a receipt the clinician can read end to end.
- The whole stack runs locally on Docker plus PowerShell, and ships to Cloud Run with one script.
- 15 pytest tests stay green; mypy strict passes.
What we learned
- Agents are only as good as the data behind them. A rule based scorer over real FHIR beats a clever prompt every time.
- Structured outputs through tool use are far more reliable than asking the model to "return JSON". The schema is enforced at the API boundary.
- A shared MCP server beats per agent tools. One audit trail, one connection pool, one place to fix a bug.
- Healthcare safety is architecture, not paperwork. Rules like "every clinical claim cites a FHIR resource" and "the clinician decides, the agent drafts" shaped the design from day one.
What's next
- Replace keyword routing with a Claude tool use planning loop.
- Add a longitudinal memory tool that summarizes care plan deltas across visits.
- Add a doula companion agent for non clinical support, with a clear handoff to the clinical agents.
- Connect to a real EHR through SMART on FHIR for a pilot.


Log in or sign up for Devpost to join the conversation.