-
-
5 custom tools!
-
Architecture!
-
Triage agent too!
-
Backed up responses!
Inspiration
US maternal mortality keeps rising. Over 80% of pregnancy-related deaths are preventable per the CDC, but the signals that predict them (rising BP, falling platelets, elevated AST, worsening proteinuria, transportation barriers, food insecurity) live across completely different parts of the chart. No single clinician sees them aggregated in one view, and rule-based EHR alerts don't fire on constellations of data. The pediatric downstream gets ignored too: every preeclampsia-driven NICU admission, every macrosomic baby born to a GDM mother, is a $25K+ cost that prenatal care isn't currently pricing in.
I wanted to test whether giving an LLM the right structured slice of FHIR could let it do the mother-baby pattern-matching a busy OB can't always do in the 15 minutes before a prenatal visit.
What it does
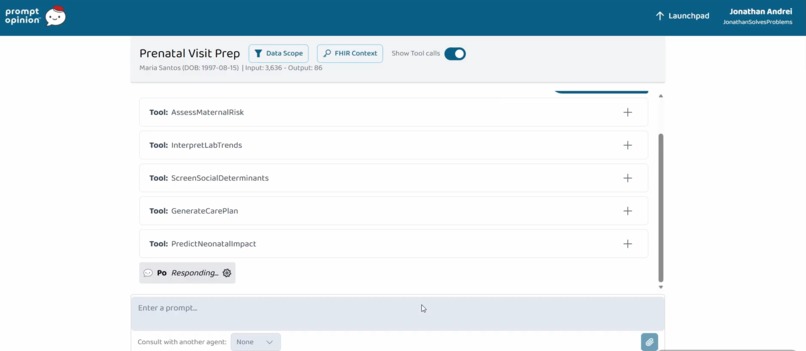
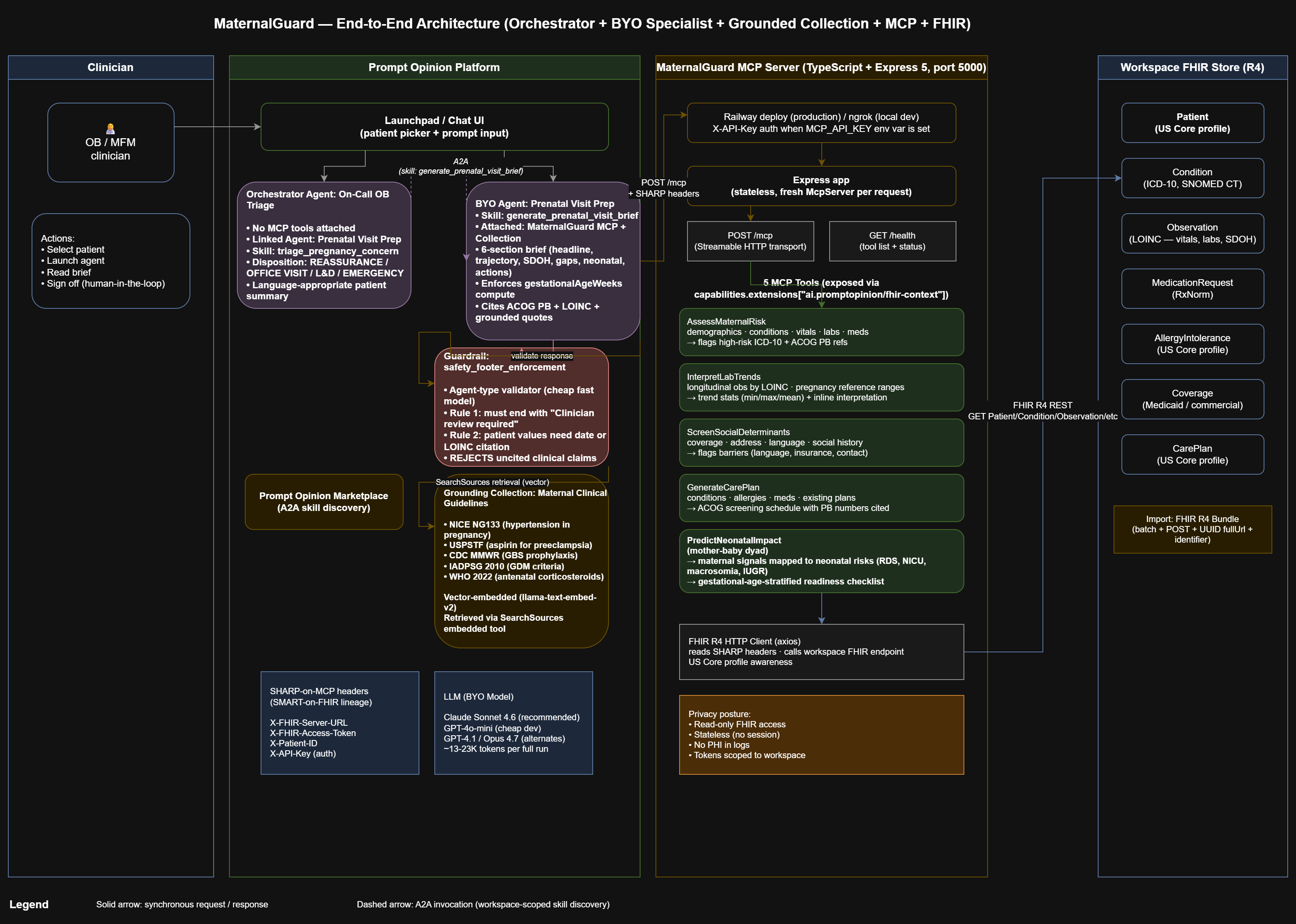
MaternalGuard is an MCP server with 5 tools that read a pregnant patient's FHIR R4 data and return it as decision-ready context for the Prompt Opinion platform's AI:
- AssessMaternalRisk: demographics, conditions, recent vitals, labs, meds, with high-risk ICD-10 flags and ACOG Practice Bulletin references
- InterpretLabTrends: longitudinal lab and vital readings grouped by LOINC code with pregnancy-specific reference ranges
- ScreenSocialDeterminants: insurance, language, address, social history observations, flagged barriers
- GenerateCarePlan: conditions, allergies, meds, existing care plans plus ACOG-aligned screening recommendations with Practice Bulletin numbers
- PredictNeonatalImpact: maps maternal data to projected neonatal outcomes (macrosomia, RDS, NICU admission, IUGR, hypoglycemia) with a gestational-age-stratified neonatal readiness checklist
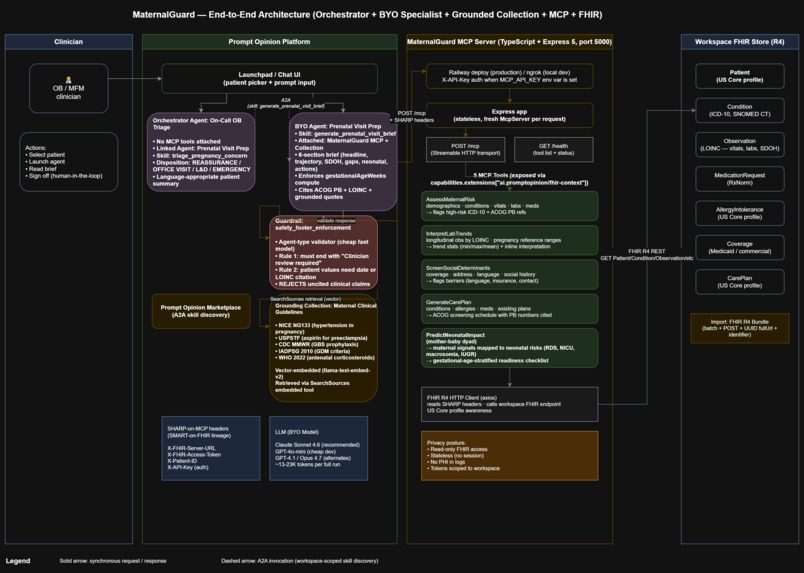
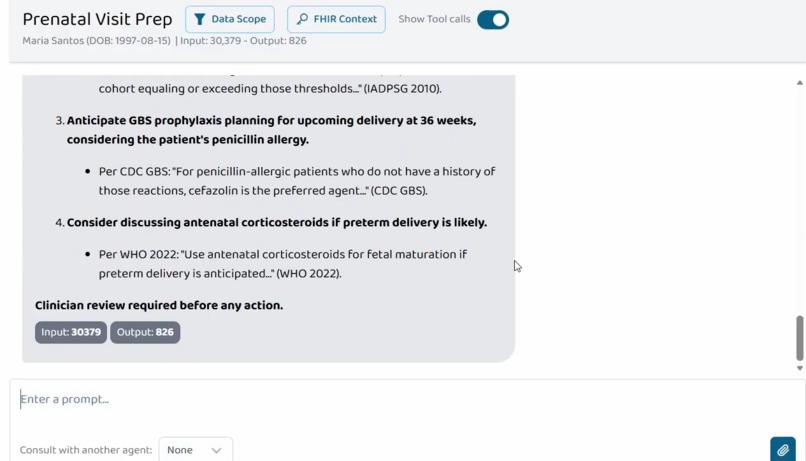
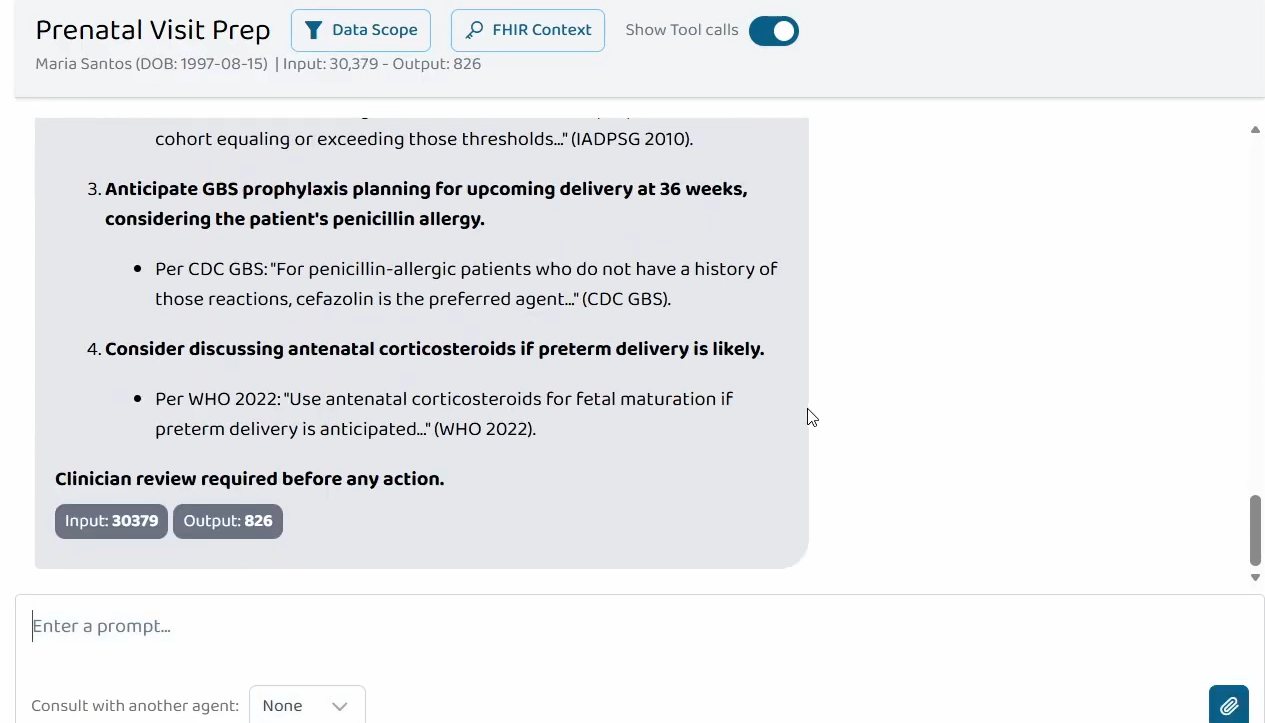
Two composed agents demonstrate the "Agents Assemble" thesis. Prenatal Visit Prep is a BYO Agent that orchestrates all 5 MaternalGuard tools and retrieves from a grounded clinical-guidelines Collection (NICE NG133, USPSTF, CDC, IADPSG, WHO) into a single 6-section consolidated pre-visit brief. Every claim is cited with values, dates, LOINC codes, and ACOG Practice Bulletin numbers; grounded claims quote directly from the Collection PDFs.
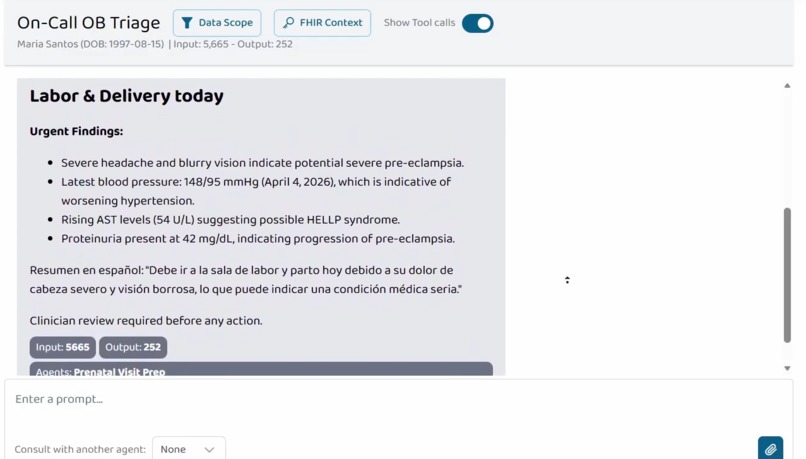
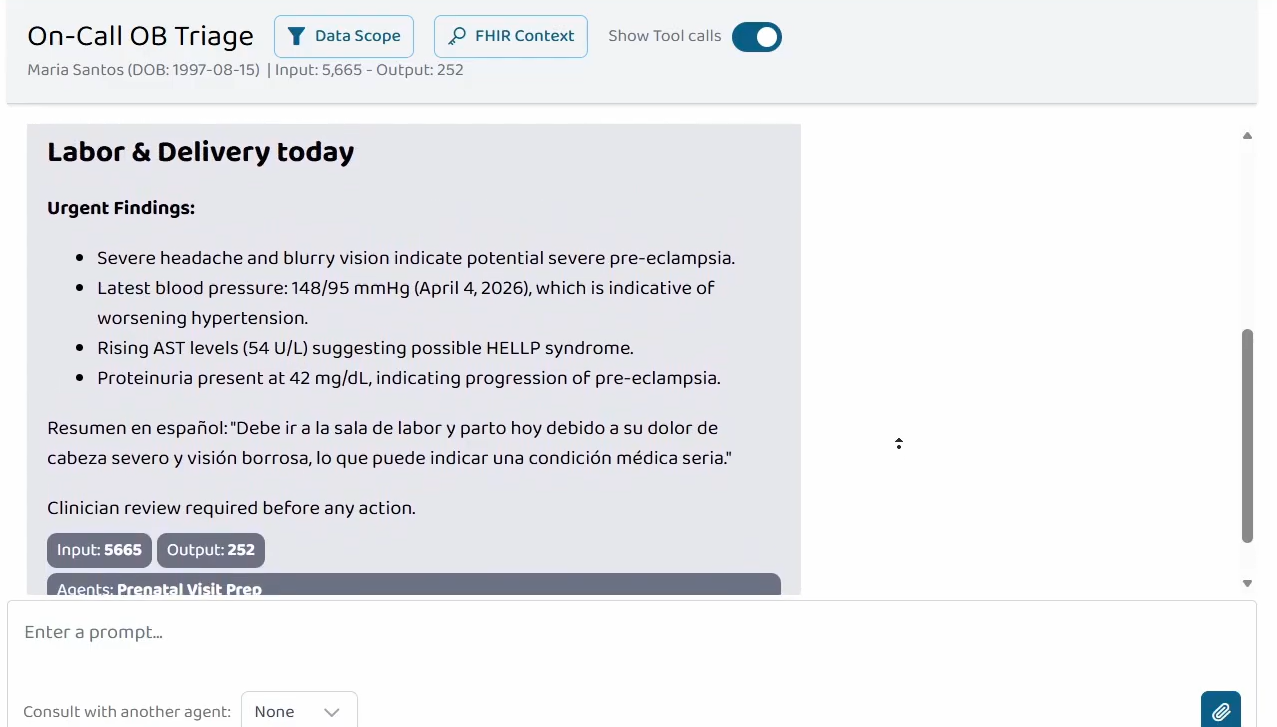
On-Call OB Triage is a Prompt Opinion Orchestrator Agent with no MCP tools of its own. It A2A-delegates to Prenatal Visit Prep for acute symptom triage and converts the returned brief into a triage disposition (REASSURANCE, OFFICE VISIT, L&D EVALUATION, or EMERGENCY) plus a language-appropriate patient-facing summary. Two-level agent composition entirely over open standards (MCP, A2A, SHARP, FHIR R4, US Core).
How I built it
- Language and runtime: TypeScript on Node.js with Express 5
- MCP:
@modelcontextprotocol/sdkusing the Streamable HTTP transport in stateless mode (a freshMcpServerper request) - FHIR: R4 over standard REST with US Core profile declarations on Patient, AllergyIntolerance, and CarePlan resources; an axios client that reads SHARP headers (
X-FHIR-Server-URL,X-FHIR-Access-Token,X-Patient-ID) off each inbound request - Extension: declared
ai.promptopinion/fhir-contextin MCP capabilities so the platform forwards SHARP context (lineage from SMART-on-FHIR) - Clinical references: every ACOG-anchored recommendation cites the specific Practice Bulletin number (PB #222 preeclampsia, PB #190 GDM, PB #234 antenatal corticosteroids, PB #713 late-preterm steroids, PB #797 GBS prophylaxis, PB #201 pregestational diabetes, PB #203 chronic HTN, PB #231 multifetal gestations, PB #197 thromboembolism)
- Production deployment: Railway-hosted Express server with X-API-Key authentication on the
/mcpendpoint; ngrok for local development only - Test data: a hand-crafted FHIR R4 batch bundle with 40+ resources for a synthetic pregnant patient (Maria Santos) designed to exercise each tool's edge cases. Includes the HELLP constellation in labs, SDOH barriers, an active care plan, and a penicillin allergy for GBS prophylaxis reasoning
- Vector-grounded retrieval: a curated clinical-guidelines Collection attached to the specialist agent so retrieval at runtime grounds clinical claims in real guideline text rather than LLM training recall
- Two-level orchestration: Prenatal Visit Prep enforces the 5-tool workflow, Collection retrieval, and 6-section brief format. On-Call OB Triage links Prenatal Visit Prep as a sub-agent and A2A-delegates every clinical triage question. Both agents publish A2A skills (
generate_prenatal_visit_brief,triage_pregnancy_concern) for marketplace exposure - Structural safety: a Prompt Opinion Agent-type guardrail validates every response before it reaches the user, rejecting anything missing the "Clinician review required" footer or inventing patient-specific values without a date or LOINC citation
Challenges I ran into
- FHIR bundle import quirks. The platform requires
POST(notPUT), every entry needs a real UUIDfullUrl(arbitrary strings silently fail), and Patients need anidentifierarray or they import "successfully" but never appear in the patient picker. Three bundle rewrites and direct Q&A with the platform team to land on the format that actually works. - SHARP header debugging. Early tests with the General Chat Agent showed tools being discovered but never invoked with patient context. Switching to a BYO Agent with Patient Context enabled, and selecting a patient in the picker before launching, fixed it. I added structured logging to the
/mcphandler so I could see exactly which headers were arriving. - Zod null handling. The platform's LLM passes
"patientId": nullexplicitly in tool arguments rather than omitting the field, which caused zod validation errors onz.string().optional(). Fixed by adding.nullable()to every optional parameter across all 5 tools. - Token budget. GitHub Models' free tier caps request bodies at 8K tokens, too small for a 5-tool agent over a rich FHIR bundle. I trimmed redundant "general clinical knowledge" from tool outputs (disclaimers, guideline text the LLM already has from training) and switched to paid BYOM (Claude Sonnet 4.6) for the demo recording.
- Gestational age passing. The LLM was passing
nullforgestationalAgeWeeksto GenerateCarePlan, which collapsed the ACOG screening recommendations. Fixed with a system-prompt rule telling it to compute the value from theZ34.XXcondition code oronsetDateTime. - Keeping the mother-baby dyad in scope. Most maternal AI demos ignore the pediatric downstream. I added a 5th MCP tool, PredictNeonatalImpact, that maps maternal conditions and abnormal labs to specific neonatal outcomes (macrosomia, RDS, NICU admission, IUGR) and returns a gestational-age-stratified readiness checklist. Updated the system prompt to require explicit maternal-to-neonatal connections.
- Demonstrating agent composition. The hackathon explicitly rewards agents calling agents. I added an On-Call OB Triage Orchestrator agent that has no MCP tools of its own but A2A-delegates to Prenatal Visit Prep via the Linked Agents mechanism, which calls 5 MCP tools and retrieves from the grounded Collection. Finding the right pattern required iterating through several failure modes including LLM hallucinating fake A2A agent IDs, embedded-tool shortcutting the specialist, and Spanish-only translation logic.
- Vector retrieval wiring. After attaching the Collection, retrieval would not fire. Input tokens stayed tiny and the LLM hallucinated quoted passages. Root cause was a "Disable Embedded Tools" toggle I'd turned on earlier to suppress unwanted tool calls. That same toggle blocked Po's
SearchSourcesretrieval tool that grounded Collections depend on. Re-enabling embedded tools plus adding explicit prompt rules forbidding their misuse restored retrieval.
Accomplishments that I'm proud of
- End-to-end multi-signal pattern recognition. The agent correctly identifies the HELLP progression pattern on Maria Santos from the combination of rising BP, rising AST, falling platelets, rising proteinuria, and elevated uric acid. A constellation no single-metric rule engine would fire on.
- Mother-baby dyad as one clinical unit. PredictNeonatalImpact maps maternal signals (GDM, preeclampsia, prior preterm birth, abnormal labs) to projected neonatal outcomes with ACOG references and a gestational-age-stratified neonatal readiness checklist. Most maternal AI projects forget the baby; this one makes the pediatric handoff explicit.
- SDOH-to-clinical synthesis. The brief connects a Spanish-language primary barrier to the need for interpreter-supported preeclampsia warning sign counseling, and a transportation gap to hospitalization threshold planning.
- Allergy-aware recommendations. GBS prophylaxis guidance at 36 weeks automatically flags the patient's penicillin allergy and recommends alternatives (cefazolin for low-severity, clindamycin or vancomycin for anaphylactic) per ACOG PB #797.
- Two-level A2A agent composition. On-Call OB Triage A2A-delegates to Prenatal Visit Prep, which calls 5 MaternalGuard MCP tools and retrieves from the grounded guideline Collection. All over open standards.
- Every claim cited. Values, dates, LOINC codes, and ACOG Practice Bulletin numbers appear inline in the brief, making it auditable rather than a black box.
- Graceful degradation. The tools work with any patient in the workspace. On a data-sparse patient they return what exists and flag what's missing rather than failing.
- US Core profile declarations. Patient, AllergyIntolerance, and CarePlan resources declare
meta.profilereferencing US Core R4. - Structural safety via platform guardrail. An Agent-type guardrail on Prenatal Visit Prep validates every response before it reaches the clinician. Safety isn't a prompt hope; it's a second-model check.
- Vector-grounded clinical citations. 5 curated guideline PDFs in a Prompt Opinion Collection. Retrieval at runtime means clinical claims come from the guideline text itself, not LLM training recall. The guideline corpus is checked into the repo for judge verification.
- Language-agnostic patient communication. The on-call triage disposition produces a one-sentence patient-facing summary in whatever primary language the patient prefers (per SDOH data), with proper clinical terminology (e.g., Spanish "sala de labor y parto" for L&D, never the false-friend "laboratorio").
What I learned
- The SHARP-on-MCP protocol is simpler than it sounds. Three HTTP headers and an extension declaration. Getting the extension string exactly right (
ai.promptopinion/fhir-contextundercapabilities.extensions, notexperimental) mattered. - Stateless MCP servers on
StreamableHTTPServerTransportwithsessionIdGenerator: undefinedare the right default for public-internet MCP endpoints. No session state to corrupt, no memory pressure under load. - The LLM doesn't need clinical boilerplate. I initially packed tool outputs with HELLP criteria, IADPSG thresholds, and "SDOH domains to assess" descriptions, assuming that would help the AI reason. Trimming all of it made responses better because the model stopped being distracted by its own training knowledge restated back to it.
- The LLM does need specific citations. The opposite of boilerplate (concrete ACOG Practice Bulletin numbers, LOINC codes, ICD-10 references per tool response) made the output dramatically more auditable and clinician-trustworthy.
- Tool orchestration beats clever individual tools. The 5 tools are each pretty simple, just structured FHIR fetches with flag logic. The leverage comes from composing them inside a BYO Agent with a disciplined system prompt that enforces order and output structure.
- Agent composition is the real unlock. When one agent A2A-calls another agent that calls 5 MCP tools plus retrieval, you're building a network of specialists. The On-Call OB Triage Orchestrator is roughly 60 lines of prompt with no tools of its own. All the clinical smarts come from the downstream Prenatal Visit Prep specialist, MaternalGuard, and the grounded guideline Collection.
- Safety has to be structural. I tried prompting the LLM to "be safe" and it worked inconsistently. Requiring citations per claim, ending every brief with "Clinician review required before any action", and adding a platform-level guardrail that validates every response before it reaches the user moves safety from a vibe into architecture.
- Template variables in system prompts matter. Prompt Opinion uses fragments like
{{ PatientContextFragment }},{{ OrchestratorAgentsFragment }}, and{{ A2ATaskInfoFragment }}to inject platform-managed context. Omitting them from a custom prompt breaks retrieval, A2A discovery, and patient-context propagation silently. Including the right set per agent role is non-obvious but critical.
What's next for MaternalGuard
- More conditions: peripartum cardiomyopathy risk (cardiac observations + family history), expanded hemorrhage risk model (prior PPH, placenta previa, coag labs), mental health and PPD screening across the perinatal window.
- Postpartum continuity: extend the tool set to cover the 12-week postpartum window, where over a third of pregnancy-related deaths occur.
- Better InterpretLabTrends: derived metrics like mean arterial pressure (MAP) and trimester-aware reference ranges instead of a single pregnancy range.
- Pediatric downstream composition: publish a companion NeonatalPrep agent that subscribes to PredictNeonatalImpact output and coordinates with NICU, L&D, and anesthesia agents via A2A.
- Real FHIR integration: test against live Epic and Cerner sandboxes and expose the MCP server via a fully production URL.
- Go-to-market hypothesis: high-risk OB clinics at academic medical centers (MFM workload + quality metrics), Medicaid MCOs with perinatal quality incentives, FQHCs serving low-resource populations where SDOH-aware triage has the biggest delta. Unit economics: roughly $0.05 to $0.08 per brief at GPT-4 pricing; break-even versus one avoided NICU admission ($25K+) at roughly 300K briefs.
- Feedback loop: collect clinician feedback on the brief structure and iterate on the Prenatal Visit Prep system prompt; A/B test disposition accuracy on the On-Call OB Triage agent against retrospective case data.
Built With
- acog-practice-bulletins
- agent-to-agent-(a2a)
- axios
- cors
- date-fns
- dotenv
- draw.io
- express-5
- fhir-r4
- hl7
- iadpsg-criteria
- icd-10
- jose
- loinc
- model-context-protocol-(mcp)-sdk
- ngrok
- node.js
- prompt-opinion-agent-type-guardrails
- prompt-opinion-collections-(vector-grounded-retrieval)
- prompt-opinion-platform
- railway
- rxnorm
- sharp-on-mcp
- smart-on-fhir-(lineage)
- snomed-ct
- tsx
- typescript
- us-core-r4-profiles
- zod



Log in or sign up for Devpost to join the conversation.