
Inspiration
Justin’s father is low vision, and watching sports with him made one problem impossible to ignore: broadcasts are still designed for people who can clearly see the screen. Soccer commentary captures the emotion of a match, but it often skips the visual context that sighted fans take for granted. A commentator might yell “what a chance,” but a low-vision fan may still not know where the ball was, who was open, which direction the attack was moving, or why the stadium reacted.
Existing accessibility solutions for sports are still limited. Most tools focus on subtitles, screen readers, or generic text-to-speech, but those do not solve the core problem of live sports: the most important information is spatial and visual. Fans need to understand the field, the movement, the pressure, and the moment, not just hear a transcript.
This is not just one family’s problem. Vision impairment affects approximately 2.2 billion people worldwide, and sports remain one of the most shared cultural experiences in the world. MatchVision was built to make that experience more accessible, independent, and emotionally complete.
What it does
MatchVision is a voice-first accessibility companion for blind and low-vision soccer fans. It acts as a missing visual layer for the match, turning soccer video into concise audio-descriptive commentary and natural voice Q&A.
Instead of giving generic commentary, MatchVision explains the visual details that matter:
- where the ball is
- who has possession
- which direction the attack is moving
- where pressure is coming from
- who has space
- what key event just happened
- why the crowd reacted
Users can ask questions like:
- “What just happened?”
- “Where is the ball?”
- “Who has space?”
- “Give me tactical detail.”
MatchVision responds with short, spoken answers designed for live play.
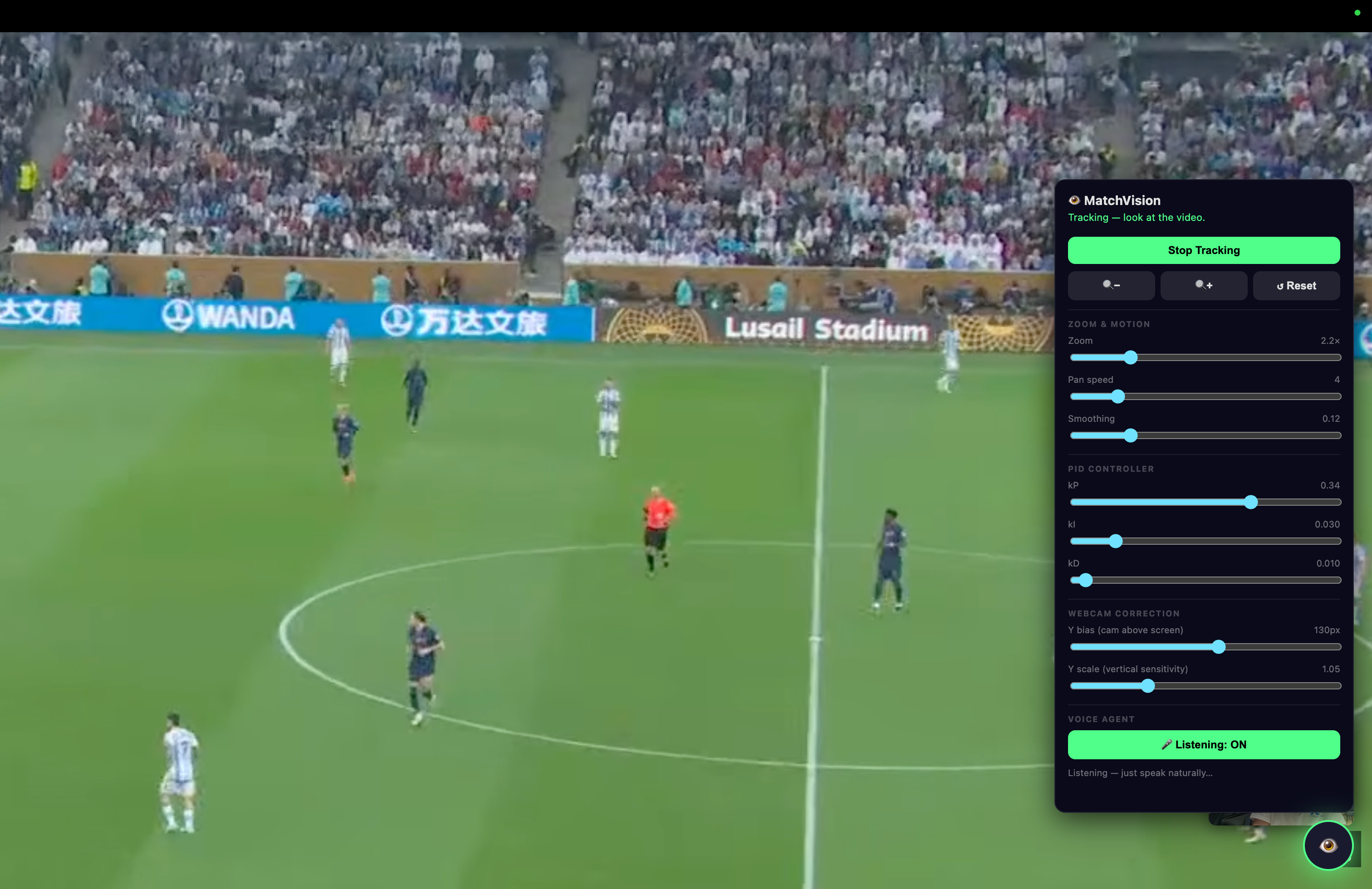
The key idea behind MatchVision is that not every part of a frame matters equally. We used human gaze heatmaps to identify the regions people naturally focus on during soccer clips, then used those heatmaps to guide the vision-language model toward the most important parts of the play. We also used human annotations from Terac to improve the captions themselves, teaching the model to produce descriptions that are useful for accessibility: spatially clear, concise, grounded, and focused on the moment.
Conceptually, each visual region is weighted by human attention:
$$ \text{Attention Weight} \propto \text{Heatmap Intensity} $$
Then the captioning objective is guided by both visual attention and human caption quality:
$$ \mathcal{L}{\text{total}} = \mathcal{L}{\text{caption}} + \lambda \mathcal{L}{\text{heatmap}} + \beta \mathcal{L}{\text{human}} $$
This lets MatchVision learn not only what is in the frame, but what parts of the frame matter most to explain.
How we built it
We built MatchVision as a full human-in-the-loop accessibility pipeline.
First, we collected gaze data from users watching soccer clips. Using webcam-based eye tracking with WebGazer.js and MediaPipe FaceMesh, we took advantage of the human annotation marketplace Terac to capture where people looked during each play. We aggregated those gaze points into heatmaps, which showed the visually important regions of the field over time. These heatmaps became an attention signal for the model, helping it focus more on the hottest regions of the frame instead of treating the entire video equally.
Using Terac, we also collected human annotations for audio-descriptive commentary. Annotators reviewed soccer moments and ranked or improved captions based on what would be most useful to a blind or low-vision fan. We focused on features like ball location, direction of attack, key-event coverage, concision, and hallucination avoidance.
We then used these two human signals together to fine-tune a vision-language model. The heatmaps guided the visual side of the model by emphasizing the parts of the frame humans cared about most, while the Terac captions guided the language side by teaching the model what high-quality accessibility commentary sounds like.
Our pipeline looked like this:
- Collect soccer clips.
- Record human gaze while users watch each clip.
- Convert gaze points into frame-level heatmaps.
- Use Terac annotators to create and rank accessibility captions.
- Fine-tune a vision-language model with heatmap-weighted frames and human-improved captions.
- Generate audio-descriptive commentary.
- Let users ask voice questions about the match.
On the product side, we built the app with JavaScript, HTML, CSS, and Node.js. We created a Chrome Extension using Manifest V3 for gaze-controlled video interaction, a web app for audio-descriptive commentary and Q&A, and API routes for storing labels, sessions, and context.
Technologies we used include:
- JavaScript / HTML / CSS
- Node.js
- WebGazer.js
- MediaPipe FaceMesh
- Terac MCP
- Redis / Upstash
- Deepgram
- LLM/VLM APIs
- Python analytics scripts
- JSON match timelines and event logs
Challenges we ran into
One of the biggest challenges was defining what “good” actually means. A caption can be grammatically correct and still be bad for accessibility. If it says “a dangerous chance develops” but does not say where the ball is, who is attacking, or why the chance is dangerous, it fails the user. We had to design our annotation rubric around accessibility quality instead of generic caption quality.
Another challenge was aligning gaze heatmaps with model attention. Human gaze data is noisy, especially when collected through webcams in different lighting conditions and screen setups. We had to smooth the signal, calibrate users, aggregate data across sessions, and think carefully about how to turn heatmap intensity into a useful training signal.
Sports video itself was also difficult. Soccer is fast, crowded, and often ambiguous. The ball is small, important actions happen off-ball, and camera angles change constantly. We had to make the model concise while still grounded, and we had to avoid hallucinations because incorrect descriptions can be worse than no description at all.
We also had to combine a lot of moving parts into one coherent system: gaze tracking, heatmaps, Terac annotation, caption fine-tuning, voice Q&A, Redis-backed storage, and browser-based playback. Making all of those pieces feel like one product instead of separate demos was one of the hardest parts of the project.
Accomplishments that we're proud of
We are proud that MatchVision is grounded in a real accessibility need. The project began with Justin’s father, but the problem extends to millions of blind and low-vision fans who are excluded from the full visual experience of live sports.
We are especially proud of building a human-in-the-loop model improvement pipeline. Instead of just prompting a model to “describe this soccer clip,” we used two forms of human feedback: gaze heatmaps to show where people look, and Terac annotations to show what people find useful. That made the system more intentional and more accessibility-focused.
We are also proud of making the product voice-first. A low-vision user should not need to navigate a complicated visual interface to understand a visual moment. They should be able to ask a question naturally and hear a useful answer immediately.
Finally, we are proud that MatchVision reframes sports accessibility. We are not trying to replace commentators. We are building the missing visual layer that helps fans understand the parts of the match that normal commentary assumes they can already see.
What we learned
We learned that accessibility is not just a feature. It changes the entire objective of the system. A normal video captioning model optimizes for fluent descriptions. MatchVision has to optimize for trust, timing, spatial clarity, and usefulness.
We also learned how powerful human data can be. Heatmaps gave us a way to teach the model what parts of the frame mattered visually, while Terac annotations taught it what kinds of descriptions mattered linguistically. Combining those two signals helped us think about model fine-tuning in a more human-centered way.
We learned that live sports are uniquely hard because the important context is constantly changing. It is not enough to identify objects. The system has to understand movement, direction, pressure, spacing, and why a moment matters in the match.
Most importantly, we learned that personal motivation makes technical decisions sharper. Thinking about whether this would actually help Justin’s father made us focus less on flashy AI output and more on clarity, reliability, and dignity.
What's next for MatchVision
Next, we want to move MatchVision closer to real-time live match support. Our goal is for blind and low-vision fans to use it during a live broadcast, not only on preprocessed clips.
We also want to collect more gaze and caption data from blind and low-vision soccer fans directly. Their feedback should define what the model optimizes for. We plan to expand the Terac annotation pipeline, improve the heatmap-guided fine-tuning process, and evaluate the system on more matches, camera angles, and levels of play.
On the product side, we want to improve personalization. Some users may want one-sentence updates, while others may want tactical detail or beginner-friendly explanations. MatchVision should adapt to each fan’s preferences.
Long term, we want to expand beyond soccer. The same approach could support basketball, tennis, racing, concerts, theater, and any live visual experience where important context is trapped on screen.
Our vision is simple: when the crowd erupts, everyone should know what happened, where it happened, and why it mattered. MatchVision is our step toward making live sports accessible to everyone.




Log in or sign up for Devpost to join the conversation.