-
-
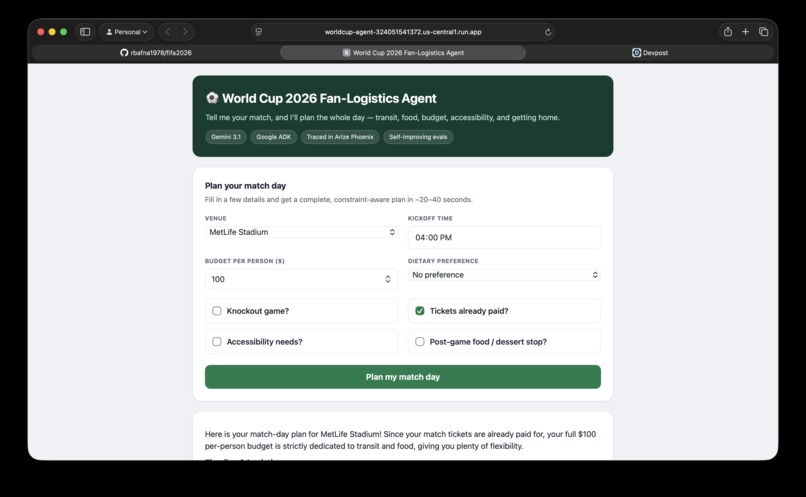
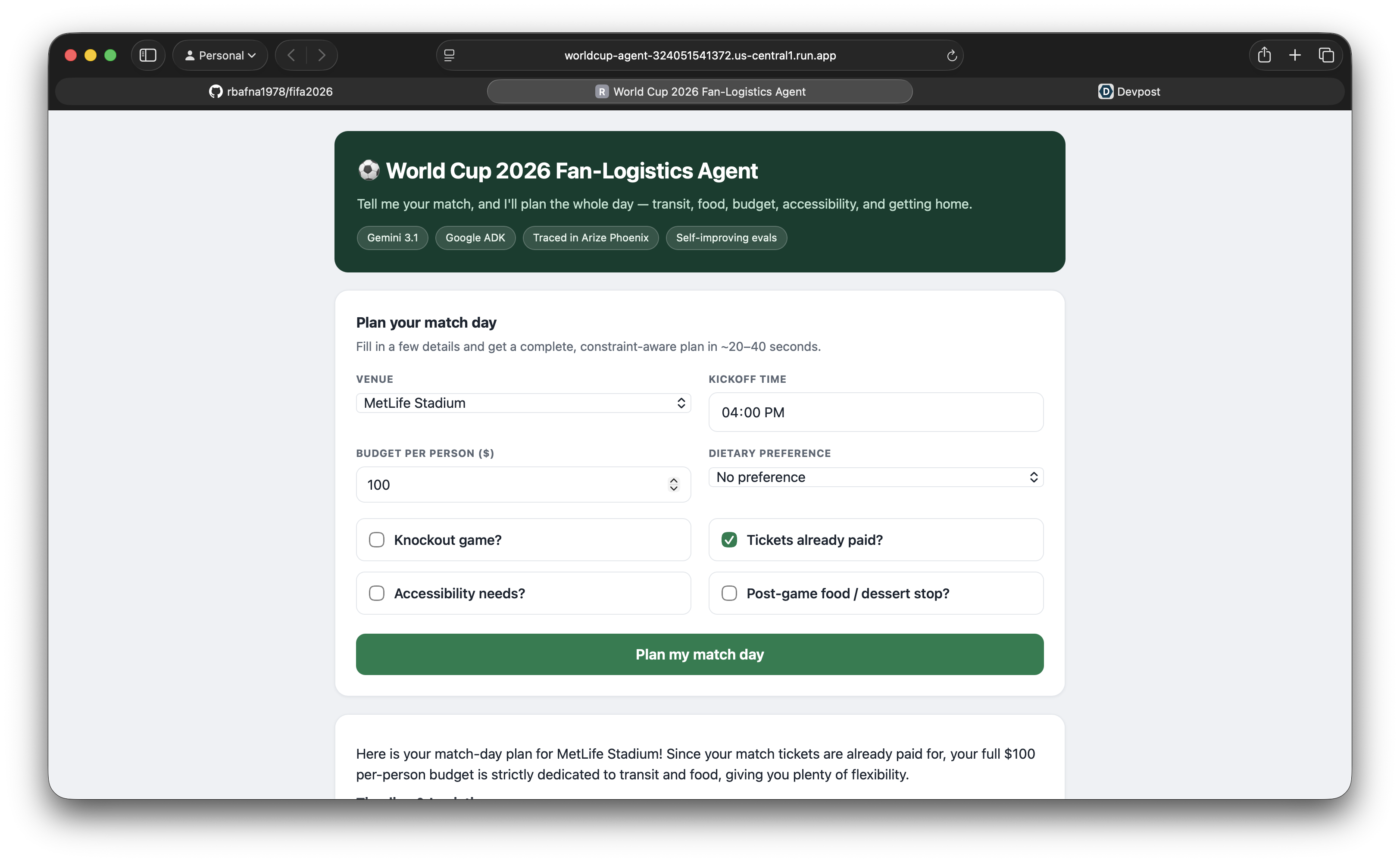
Form for user to fill out
-
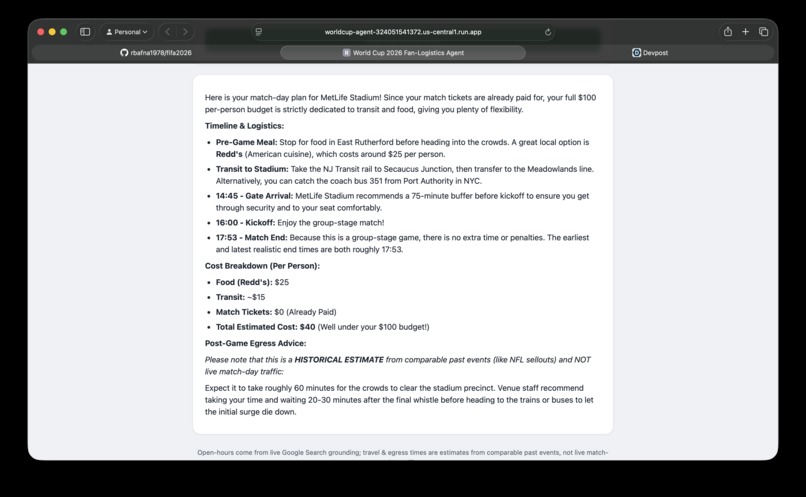
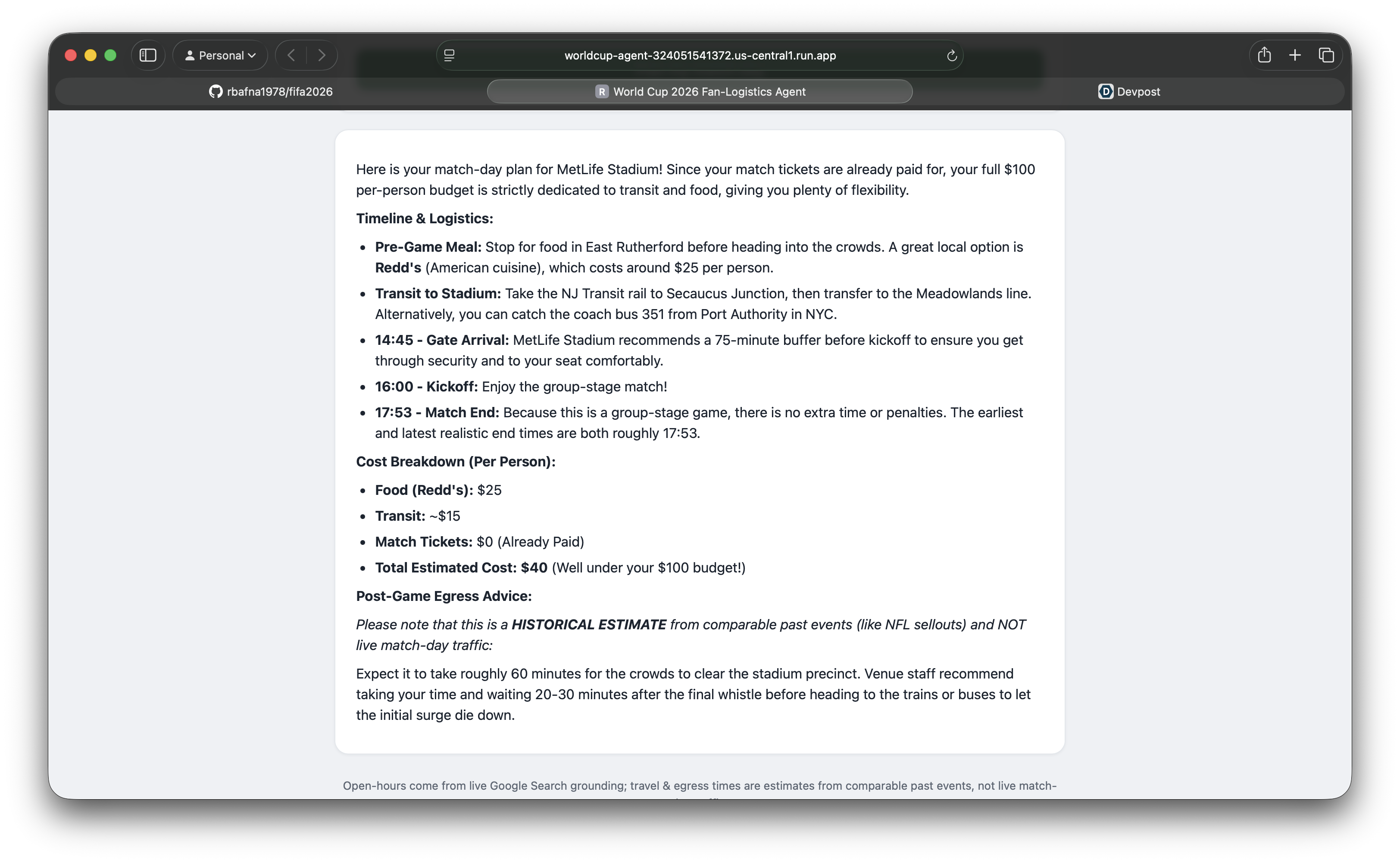
Output from the agent
Inspiration
The 2026 World Cup is the largest ever — 48 teams, 16 host cities across three countries, and millions of fans, many of whom have never set foot in these stadiums. Getting to a single match is deceptively hard: which transit actually works, where to eat on a budget, what time to really leave, and what to do about constraints like dietary needs or accessibility. We wanted an agent that doesn't just answer questions about a match day — it plans the whole thing and gets better the more it works.
What it does
Match Day is an agent that plans a complete World Cup 2026 match day from a simple form — venue, kickoff, budget, and constraints. It chains real tools to produce a usable plan:
- Transit & logistics from curated, venue-specific routes (e.g. Metro K Line + shuttle for SoFi).
- Food filtered by budget and dietary preference (vegan, vegetarian, halal, gluten-free), verified with live search.
- Accurate gate timing — arrival worked back from kickoff using each venue's recommended buffer.
- Constraint awareness — tickets already paid, accessibility needs (accessible parking/entrance from each venue's official info), and a post-game stop that checks a place is still open.
- Knockout-match reasoning — it computes a realistic end-time envelope (regulation + stoppage + half-time, plus the extra-time-and-penalties tail), so a post-game plan reserves against a match that could run ~170 minutes.
Most importantly, it observes and improves itself: every plan is scored, the score is written back to its observability platform, and the agent reads its own history to correct recurring mistakes.
How we built it
- Reasoning: Gemini 3.1 (
gemini-3.1-pro-preview) on Vertex AI. - Agent framework: Google's Agent Development Kit (ADK), with a root planner that delegates to specialist sub-agents.
- Observability + the Arize integration: the agent is fully traced in Arize Phoenix via OpenInference. It uses the Phoenix MCP server to introspect its own traces at runtime, and writes evaluation scores back as Phoenix span annotations.
- Live data: keyless Google Search grounding (no paid APIs) for facts like fixtures and business hours.
- Serving: deployed on Google Cloud Run as a public form-based web app, with Vertex auth via the runtime service account and the Phoenix key in Secret Manager.
The self-improvement loop
This is the core of the project. An LLM-as-judge scores each plan $0$–$1$ on concrete, checkable criteria — total per-person cost $\leq$ budget, gate time $=$ kickoff $-$ buffer, transit references a real route, and plan completeness. The overall score is computed in code as the mean of boolean criteria (never trusted to the model):
$$\text{score} = \frac{1}{n}\sum_{i=1}^{n} \mathbb{1}[\text{criterion}_i \text{ passed}]$$
That score is logged to Phoenix as a plan_quality annotation. The agent then reads its own recent scores and rationales, identifies what it got wrong, and corrects the next plan. The result is reproducible and measurable: a naive plan scores 0.50, and after the agent reads its own evaluations it scores 1.00.
Challenges we ran into
- MCP payloads that broke the model. The Phoenix MCP trace-listing tools returned entire span bodies — a single call ballooned to multi-GB JSON and blew past Gemini's ~1M-token input limit. We solved it with a bounded toolset that whitelists only safe summary tools, clamps result limits, and prunes spans to summary fields — cutting a representative payload from ~190k to ~3.8k characters.
- Mixing built-in and custom tools in ADK. Gemini's built-in
google_searchcan't share an agent with function tools, so we isolated it in a dedicated sub-agent exposed viaAgentTool— and reused the same pattern to keep the heavy MCP tools out of the planner. - Local vs. cloud parity. Vertex auth, the Phoenix key, and Node-based MCP all behave differently on Cloud Run than locally. We moved auth to the runtime service account, the key to Secret Manager, and made the MCP reflection path degrade gracefully when Node isn't present — so the hosted self-improvement loop runs on a fast, reliable direct read.
What we learned
- Observability isn't a dashboard you check later — it can be a tool the agent uses on itself. Letting the agent read its own traces and evaluations turned monitoring into a feedback loop.
- A trustworthy eval keeps the score out of the model's hands. Scoring in code from boolean checks made the self-improvement claim defensible.
- Scope discipline matters under a deadline. We deliberately drew lines (below) instead of shipping shaky features.
What's next
- Live traffic-aware timing (currently estimated from comparable past events, not live conditions — this needs a paid maps API).
- Crowd/queue modeling for stadium egress and post-game lines.
- Expanding curated venue, fixture, and accessibility coverage to all 16 host cities.
- Constraint-aware evaluation criteria feeding the self-improvement loop.
Built with: Gemini 3.1 · Google ADK · Google Cloud Run · Arize Phoenix · Phoenix MCP
Built With
- arize-phoenix
- cloud-run
- docker
- fastapi
- gemini
- google-adk
- google-cloud
- mcp
- openinference
- opentelemetry
- python
- uv
- vertex-ai

Log in or sign up for Devpost to join the conversation.