Inspiration
I'm a genealogist myself. Often I find myself flipping through huge volumes of vital records "birth or death records", looking for an ancestor. This can take hours, and often times you won't find what you're looking for, depending on who published the resources. Then once you find your birth record, you end up having to do these sweeps all over again to find the death record. This project aims to resolve some of that tedium.
What it does
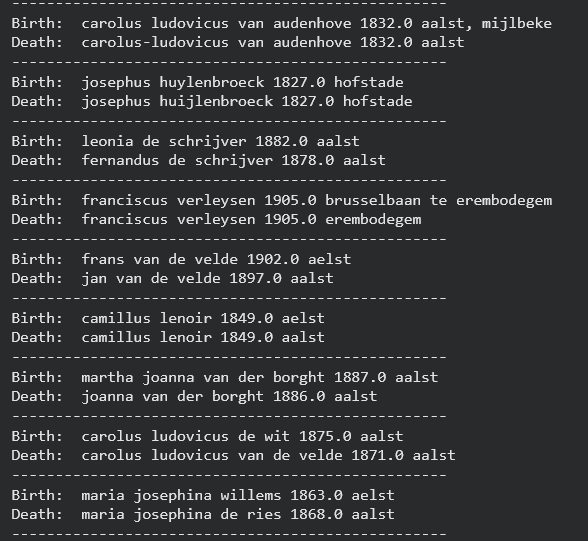
This project flips through two collections of vital records, births and deaths, from the city of Aalst, Belgium. For each individual birth record, it searches for corresponding death record using markers like name similarity, birth year, and birth location.
How we built it
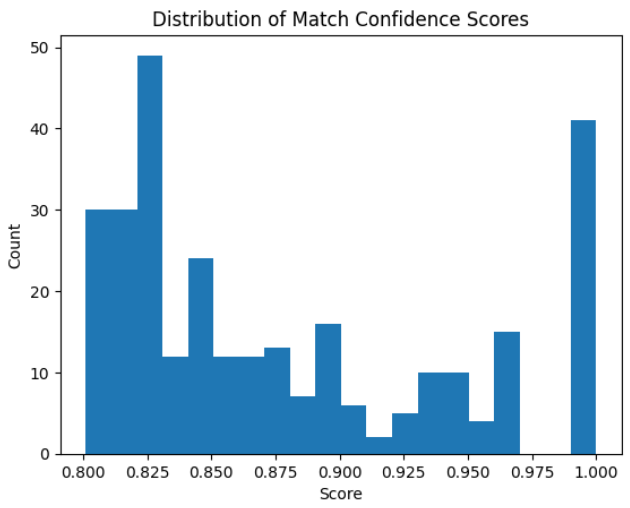
I downloaded and cleaned this genealogical data from the OpenArchiven project. Then, I used the fuzz feature from the package RapidFuzz, to calculate name and hometown similarity scores between each record in the two collections. Finally, I threw away all similarity scores below a certain quality bar (0.8), and printed information about the high quality matches.
Challenges we ran into
Calculating these matches for the full datasets, (which total approximately 200k lines), is not very time efficient. I only was able to run the program on a small subset of each collection (5k lines each). At first, I spent a lot of time attempting to use classification models, which was not a realistic approach given we would need such a large number of clusters with small, accurate members. Another challenge was that the first two datasets I tried to use were lacking information about birth dates.
Accomplishments that we're proud of
Just using these 5,000 lines of each collection, I managed to identify 298 quality birth/death record matches, with a runtime of two minutes.
What we learned
The technique of blocking is incredibly powerful for speeding up typically $O(n^2)$ comparison operations like these. I managed to save a lot of computation by filtering for candidates with similar birth years, before running the fuzz similarity loop.
What's next for Dutch Vitals Match
The project lacks a user interface. It would be most useful as a database of pairs, so that if a user knows the birth record of an ancestor they're searching for, they can see associated records. Adding baptism records, marriage records, and funeral records would also be incredibly helpful, especially since they exist for this sampled region. Another awesome feature would use the names of the ancestor's parents listed on these records to build pseudo-family trees with these already very useful record pairs.

Log in or sign up for Devpost to join the conversation.