Inspiration
Create an immersive AI-powered language learning experience that goes beyond simple text chat by integrating real-time voice, grammar correction, and specific scenarios. My goal was to create an immersive AI-powered language learning experience that goes beyond simple text chat by integrating real-time voice, grammar correction, and specific scenarios.
I also wanted a way to improve my English and having the possibility of speaking with other people I decided to create this web app using the APIs that the Google Build tool makes available to me
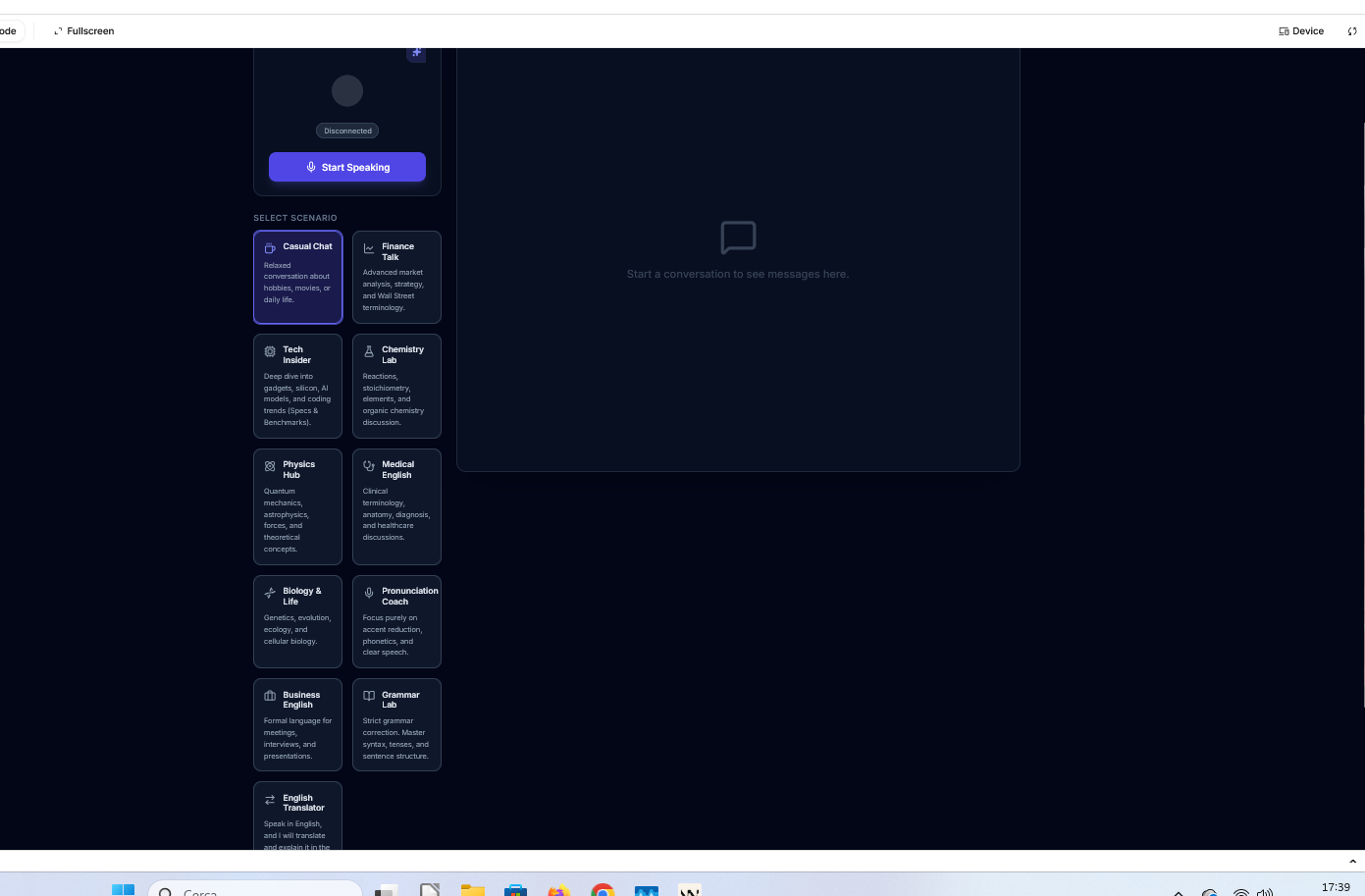
What it does
How built it : built the App using React and TypeScript for a responsive, modern frontend, styled with Tailwind CSS. The core of the application is powered by the Google Gemini Multimodal Live API.
Real-Time Audio Engine: We engineered a custom hook (useLiveGemini) that captures microphone input via the Web Audio API. We implemented a raw PCM audio processor that resamples browser audio to 16kHz in real-time to meet the strict requirements of the Gemini Live API.
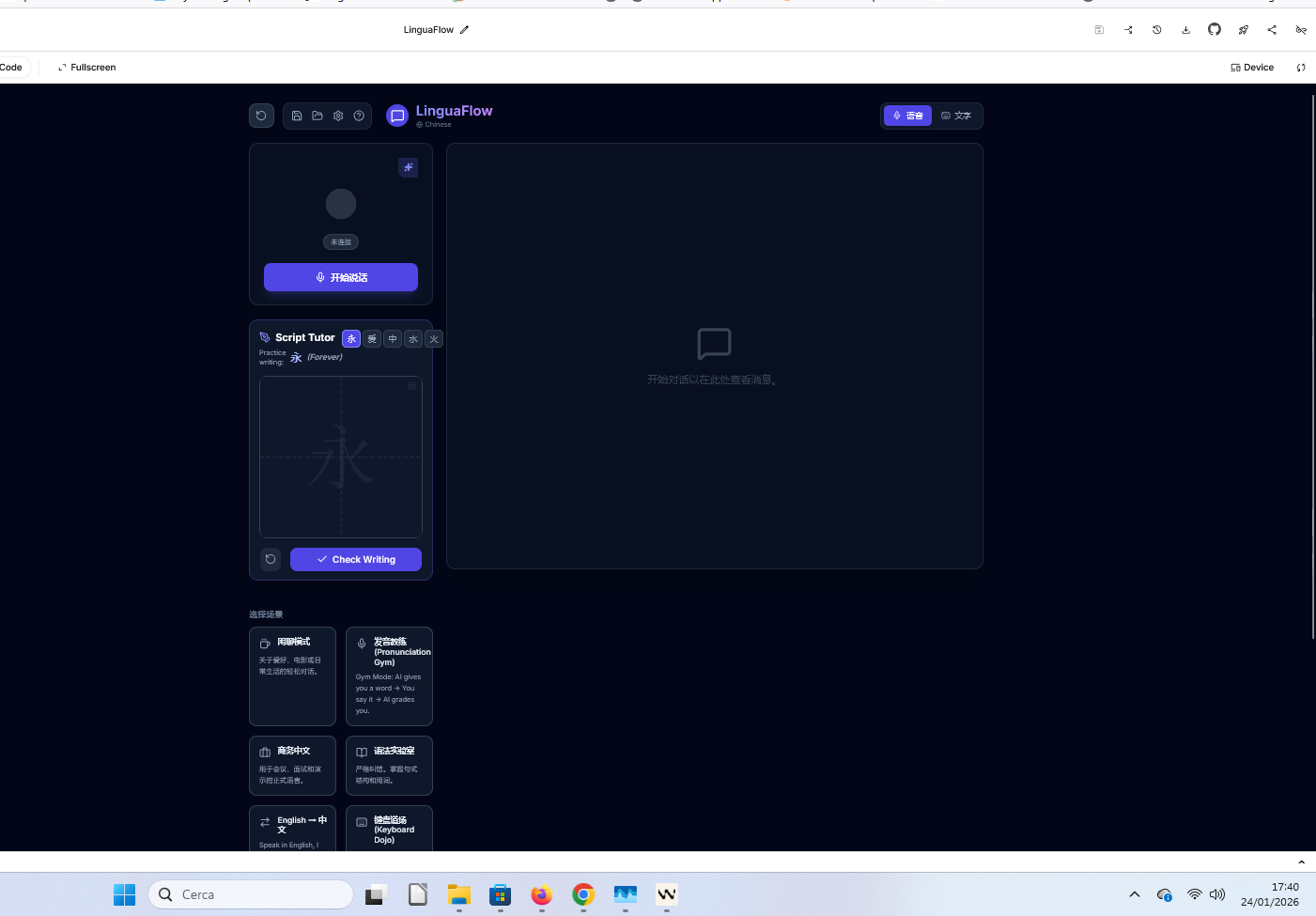
Multimodal Integration: We utilized gemini-2.5-flash-native-audio-preview for low-latency voice interactions. We also integrated the Vision capabilities by converting HTML5 Canvas drawings into Base64 strings to allow the AI to grade handwriting in the "Script Tutor" module.
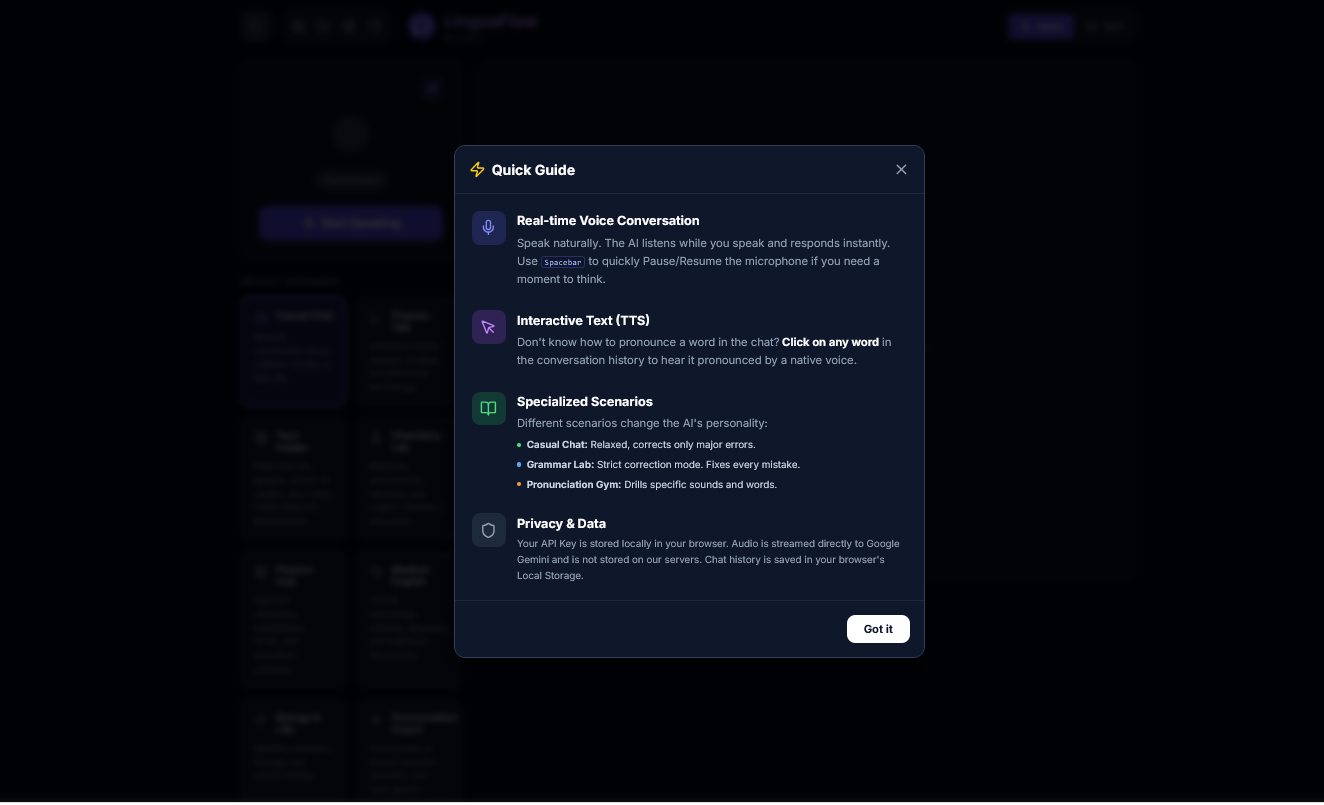
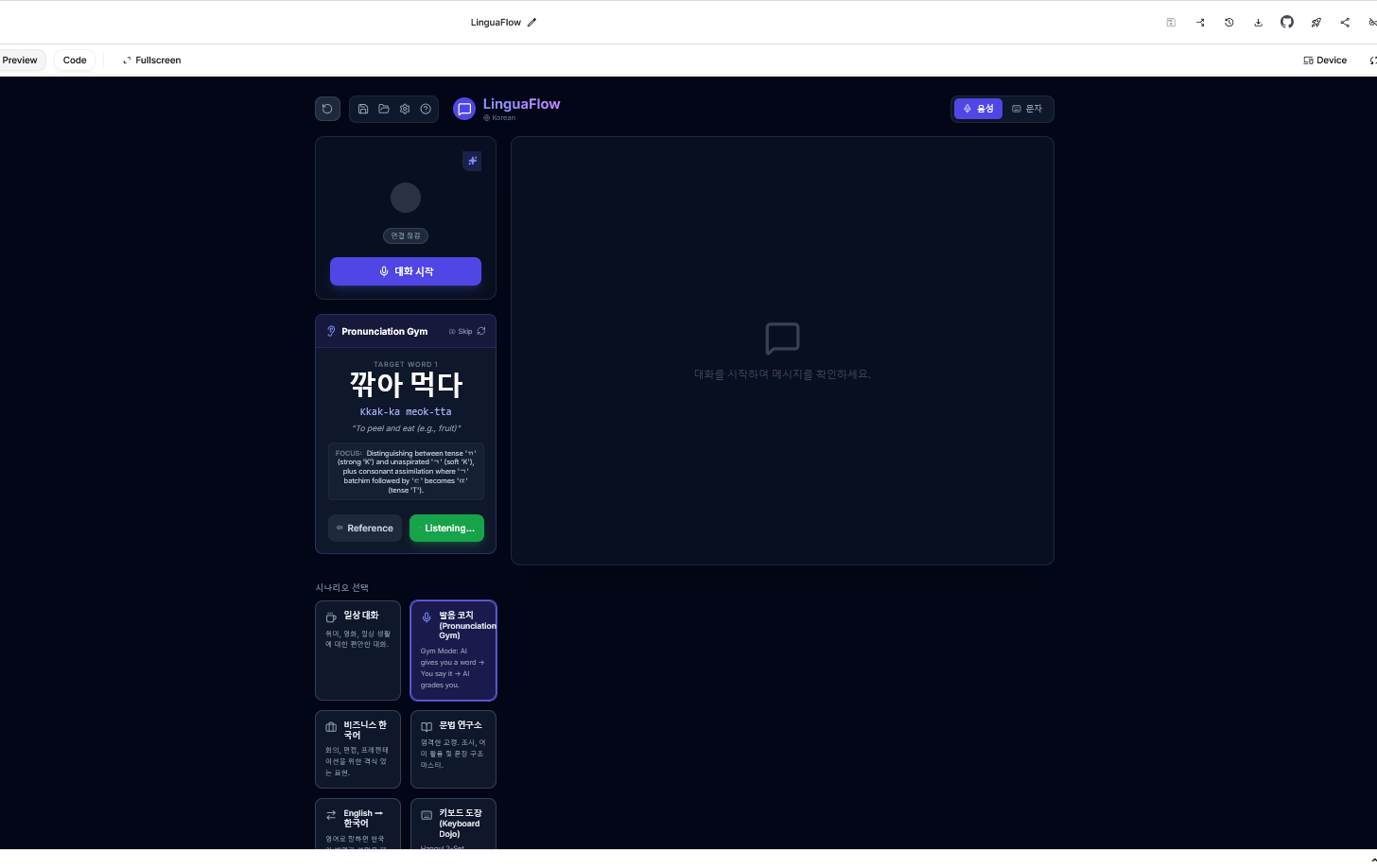
Dynamic context injection: I've created a robust prompt engineering system. When a user selects a scenario (e.g., "Wall Street Analyst" or "Strict Grammar Teacher"), the app dynamically inserts specialized system instructions and tool definitions (such as Google Search or Image Generation) into the live session without compromising the user experience. This feature will be improved in the future by adding new features. It's the core of the project.
Privacy-First Architecture: i built the session management system using LocalStorage, ensuring that API keys and chat history remain entirely client-side.
Challenges encountered: Audio synchronization and latency: One of the most complex aspects was managing the audio buffer queue. We had to ensure that the model's audio response played smoothly, without clipping or overlapping with the user's voice. We solved this problem by implementing nextStartTime slider logic in the AudioContext to perfectly schedule the blocks.
Another challenge was implementing the grammar and formatting the text correctly, and getting the project to correctly understand the voice inputs.
Handling Interruptions: Implementing the "barge-in" feature (where the user interrupts the AI) was tricky. We had to listen for the interrupted signal from the websocket and immediately purge the client-side audio buffer to stop the AI from talking over the user.
Prompt Engineering for "Personality": Getting the AI to switch from a "casual friend" to a "strict pronunciation coach" required extensive tuning of the System Instructions. Initially, the model was too polite when i wanted it to be critical of grammar errors but I had to make several attempts to try to correct the pronunciation correctly and I didn't succeed 100 percent and I should work on how the AI is able to understand the pronunciation and correct
Visualizing Voice: Creating a reactive audio visualizer that worked for both the user's microphone and the AI's incoming audio stream required analyzing byte frequency data from two different nodes in the audio graph.
Accomplishments that I 're proud of
The I didn't just build a chatbot; we built a suite of tools. iare particularly proud of the , which lets users draw Chinese/Japanese characters on a canvas, and the AI visually analyzes their stroke order and aesthetics in real-time.
Seamless Tool Use: We successfully enabled the AI to use Google Search for real-time financial data and Image Generation to visualize scientific concepts (e.g., generating a molecule structure during a chemistry lesson) during a voice conversation.
Accomplishments that I 're proud of
The I didn't just build a chatbot; we built a suite of tools. iare particularly proud of the , which lets users draw Chinese/Japanese characters on a canvas, and the AI visually analyzes their stroke order and aesthetics in real-time.
Seamless Tool Use: We successfully enabled the AI to use Google Search for real-time financial data and Image Generation to visualize scientific concepts (e.g., generating a molecule structure during a chemistry lesson) during a voice conversation.
Interactive Text: I implemented a feature where users can click on any word in the chat log (even in complex scripts like Arabic or Russian) to hear immediate native pronunciation, bridging the gap between reading and listening.
Keyboard Dojo: I've created a custom virtual keyboard engine that teaches users how to type in foreign alphabets (like Pinyin or Hangul) by highlighting the exact keys they should press, making the typing experience more enjoyable, but I need to finish implementing it properly for all languages. Getting all the characters to appear in the various language layouts is extremely complicated, but I've managed to create their respective accents and symbols for almost all languages, but it still needs improvement.
What i learned
The Power of Multimodality: Ilearned that language learning isn't just text or audio—it's visual. Combining voice conversation with real-time image analysis (for handwriting) created a much more immersive loop than we expected.
Web Audio API Depth: I gained a deep understanding of AudioWorklets, sample rates, and PCM encoding. Handling raw binary audio streams over WebSockets gave us a new appreciation for the engineering behind tools like Zoom or Discord.
Latency is Key: In language learning, even a 500ms delay breaks the immersion. Using the Gemini Live API over standard REST calls was a game-changer for creating a "flow" state in conversation.
What's next for MasterAdvanceLanguages
What's next for MasterAdvanceLanguages (LinguaFlow)
User Accounts & Cloud Sync: Moving from LocalStorage to a backend (like Firebase) to allow users to sync their progress and saved sessions across devices.
Gamification 2.0: Implementing XP, streaks, and a global leaderboard to increase user retention.
Native Mobile App: Porting the React logic to React Native to allow users to practice their pronunciation on the go with background audio support.
Add even more languages to study and improve the keyboard layout for Eastern languages.
Greatly improve the Gratamamr section for studying spelling, verb tenses, and sentence construction depending on the language. I will try to improve this greatly.

Log in or sign up for Devpost to join the conversation.