-
-
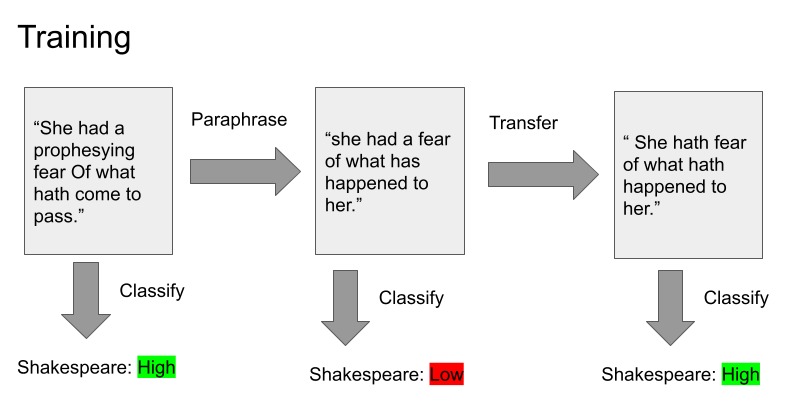
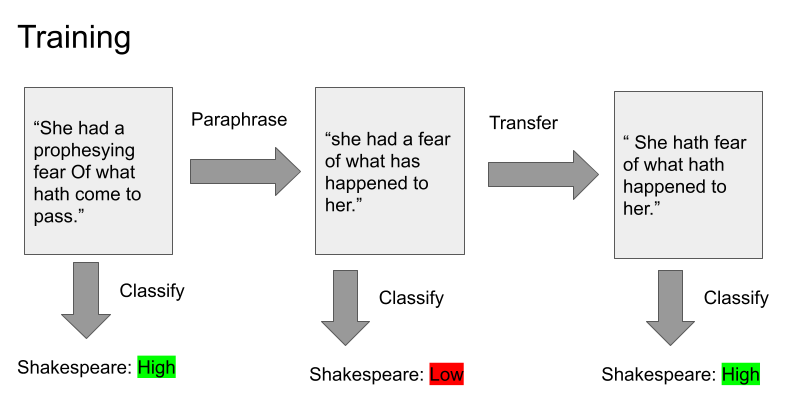
Deep Learning Training
-
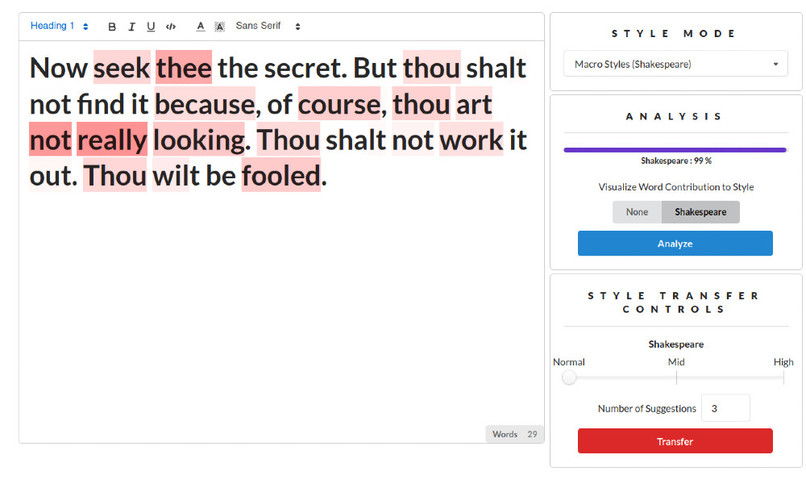
Marvin in action!
-
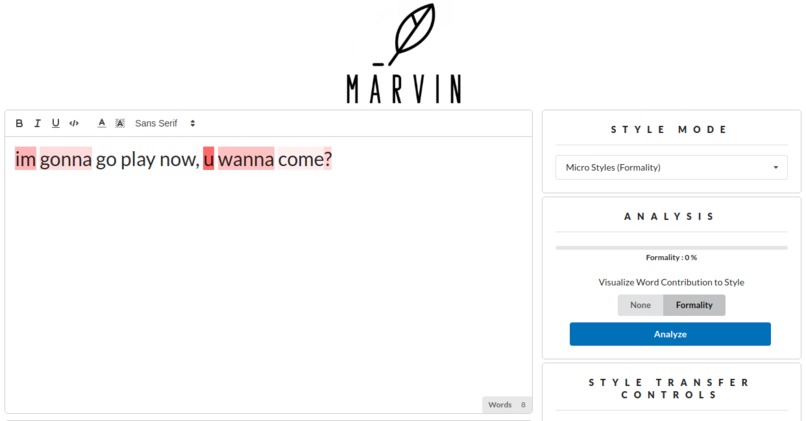
Marvin in action!
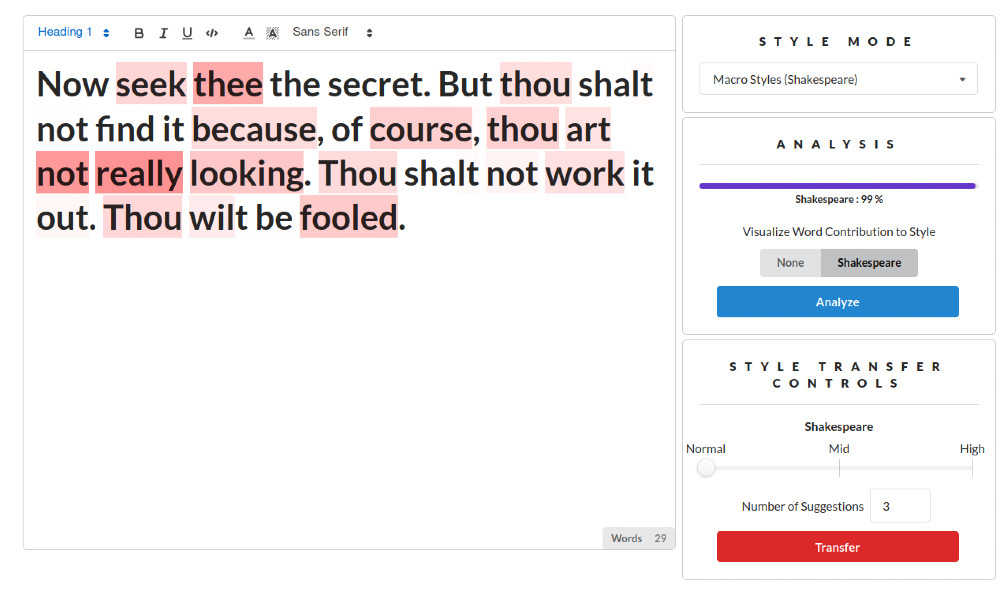
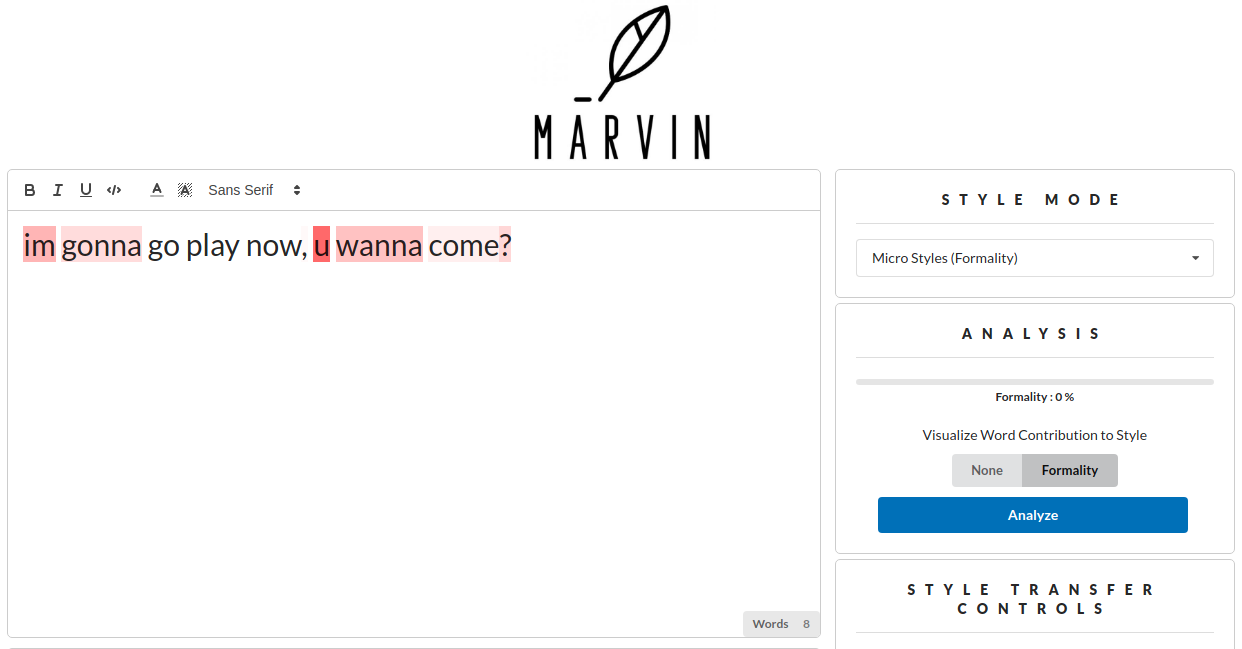
Introduction
Marvin is an AI powered tool for stylistic language editing. It leverages a combination of recent Natural Language Processing (NLP) and deep learning innovations in text classification and generation as well as visualization and interpretation techniques. Marvin provides the ability to classify the style of texts, transfer to other styles as well as understand how certain features contribute to style. It strives to adhere to a machine-in-the-loop framework, where writing is performed normally by human users, but is aided by algorithmic suggestions.
Throughout history, the written word has played a vital role in expanding the horizons of human consciousness. And effective use of stylistic language is ubiquitous in this pursuit, from scientific text and Wikipedia to the writings of Shakespeare and Mahatma Gandhi. Unfortunately, language famously suffers from issues of bias, accessibility and quality control. Anyone who has ever made a Wikipedia edit or has written a technical blog post immediately recollects the dozens of examples one has to pore over, to emulate the style, objectivity and tenor of the writing style. Adherence to a particular style can often be used as a proxy measure of value. At best, this leads to a high variance in quality, and at worst, it makes the process of writing entirely prohibitive to newcomers. We believe that a system, such as Marvin, will help users generate style-conformant content and can democratize access to domains for fledgling writers from various backgrounds.
We believe that such technologies are possible only with faster network speeds and connectivity. Since most computation needs to be done on the cloud, low latency is crucial to ensure that the applications involving deep learning inference are useable, by the general population. So, we believe that TMobil's 5g connectivity is a right match to deploy our application, to help people everywhere.
Features
The primary goal of Marvin is to help people write style-conformant content. We do this in two ways. Firstly, we give users analysis on their sentences so that users themselves can write better content. Secondly, we provide suggestions for transfer into a target style while retaining the semantic meaning of the sentence.
- Classification of text along different style axes : Including macro-styles like Shakespeare, Wikipedia, Scientific Abstracts and micro-styles like formality, emotions
- Transfer of text from one style to another : Eg: Modern English → Shakespearean
- Transfer of text from one point of a style spectrum to another (Intensity Transfer) : Eg: Mid Formality → High Formality
- Visualization of feature importance for styles to understand how each word contributes to scores
- Record user actions and generate new datasets forming a closed machine-in-the-loop system
Built With
- docker
- flask
- huggingface
- javascript
- pytorch


Log in or sign up for Devpost to join the conversation.