-
-
Discord chat
-
Flow
-
Chrome Extension
Inspiration
Let's be real, searching for info in chatrooms like Discord, Slack or Teams is an absolute nightmare. We've all been there - scrolling endlessly through a thousand messages, desperately trying to find that one crucial piece of info. It's like trying to find a needle in a haystack, but the haystack is made of useless memes and outdated jokes.
The search function in these apps is about as useful as a chocolate teapot. It just performs keyword matching without any thought for context or what you actually mean. Casual users and workers alike waste countless hours trawling through Search Hell, losing productivity and their sanity in the process.
Companies bleed cash by providing chat support to customers, while developers waste time digging through knowledge bases. There's so much valuable info locked away, practically unusable because of the current inefficient search.
But we saw an opportunity - by combining the insane power of gigantic language models like Google's Gemini with focused contextual understanding, we're building MaruBot - an intelligent, personalized and smart chatbot that will blow people's minds.
MaruBot will automate admin tasks, augment support capabilities, and make searching effortless. No more scrolling for hours - just ask MaruBot and it'll bring you exactly what you need, while also performing privacy-preserving, user-aware, contextual responses.
With MaruBot, we're aiming to simplify personal search. No more wasted time, no more headaches - just pure, searchable efficiency. Get ready to have your socks blown off by the future of chat!
What it does
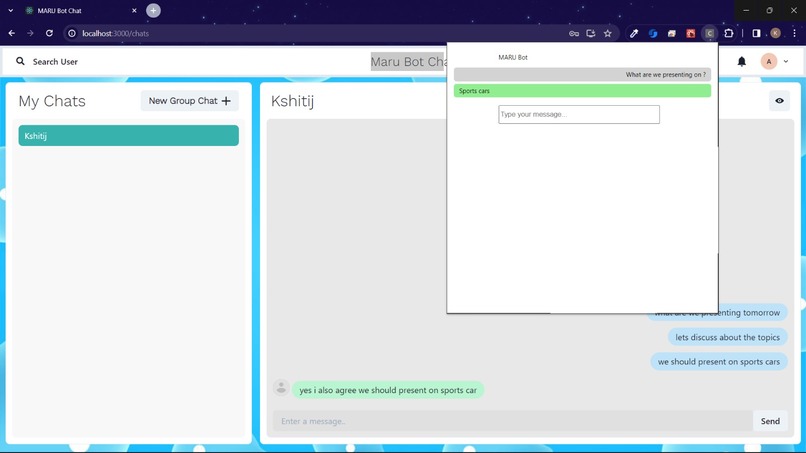
While we have created MaruBot as a chatbot on Discord; we've also developed a web extension that brings its capabilities to life virtually anywhere. This extension allows MaruBot to retrieve information from platforms that don't have native bot support, as well as from webpages, enabling it to comprehensively answer your queries.
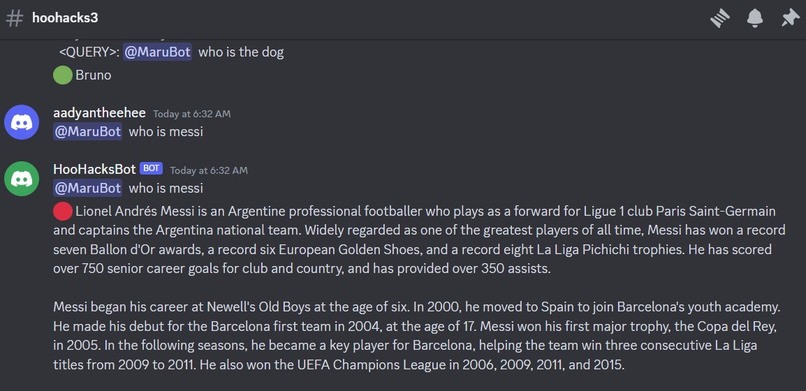
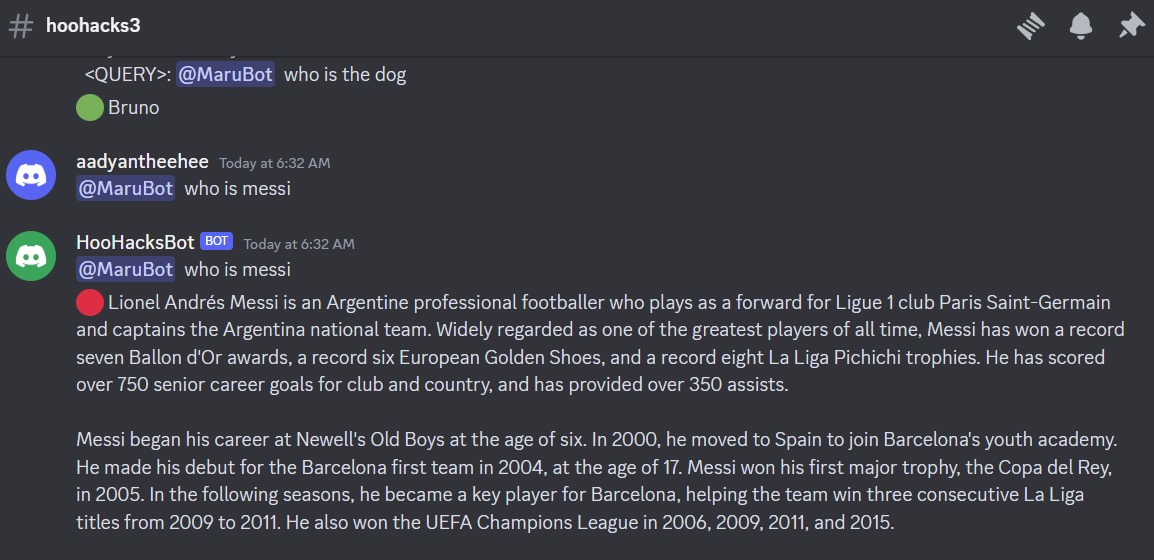
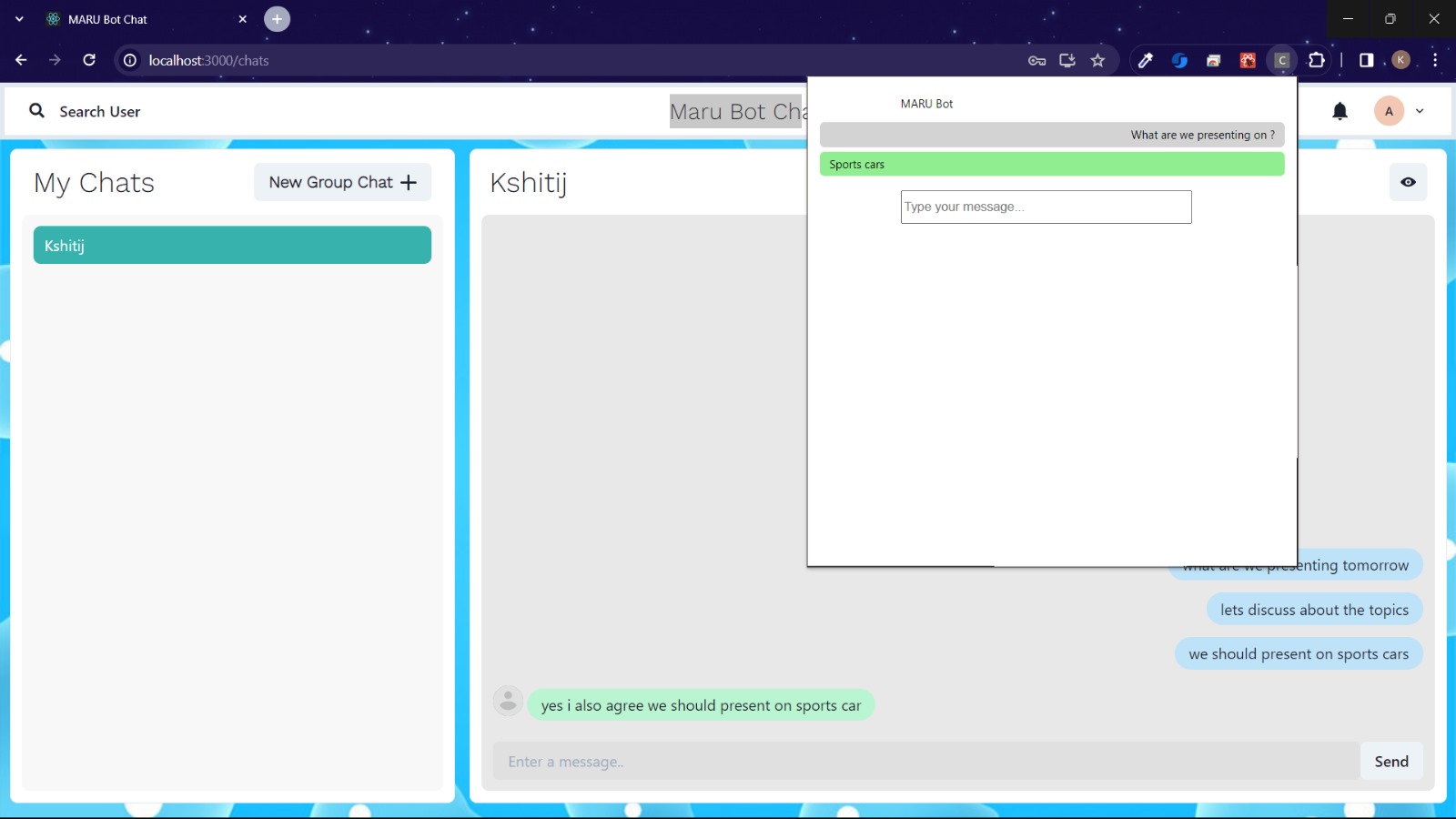
Using MaruBot is super simple on Discord. First, we install MaruBot on the Discord server. Then, any user can send a message tagging @MaruBot on any channel, and MaruBot will quickly respond with a context-aware, personalized message. This message will have a green bubble preceding it, indicating that the bot is using chat history and is confident of the answer, avoiding any hallucination. If the bot does not use the chat context, it will respond with a red bubble preceding the message, which indicates that MaruBot is using the general data it was trained on and is not providing a context-aware answer.
MaruBot accessed using the Chrome extension behaves the same way as on Discord. Here, we provide a web popup to interact with MaruBot.
At its core, MaruBot leverages the power of previous chat history as context, coupled with a Retrieval-Augmented Generation (RAG) model, to accurately and intelligently respond to user questions. The RAG model helps MaruBot identify and prioritize the most relevant previous chat conversations to the user query. It also captures information from any attached documents in the chat history allowing it to provide highly accurate answers.
MaruBot places a strong emphasis on preserving user privacy. It employs robust security measures to ensure that no confidential information, such as phone numbers, email addresses, credit card numbers, or private keys, is exposed. Your private data remains secure and protected at all times.
How we built it
We utilized Google's language model, Gemini, a pre-trained language model, to enable MaruBot's prediction capabilities.
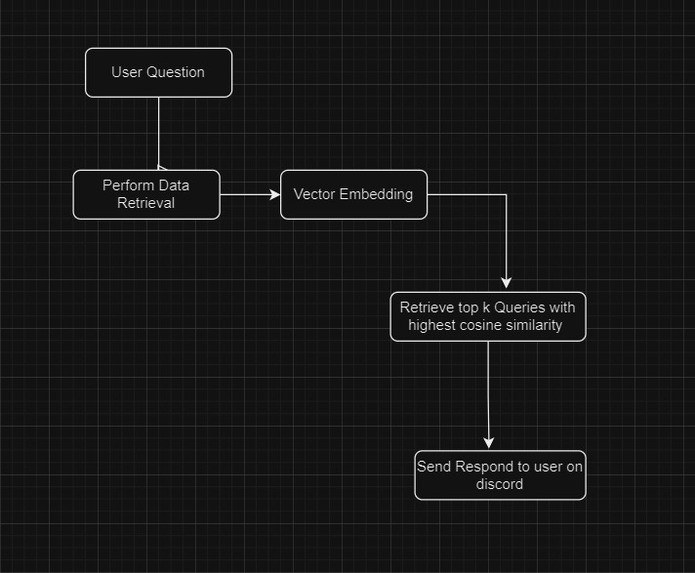
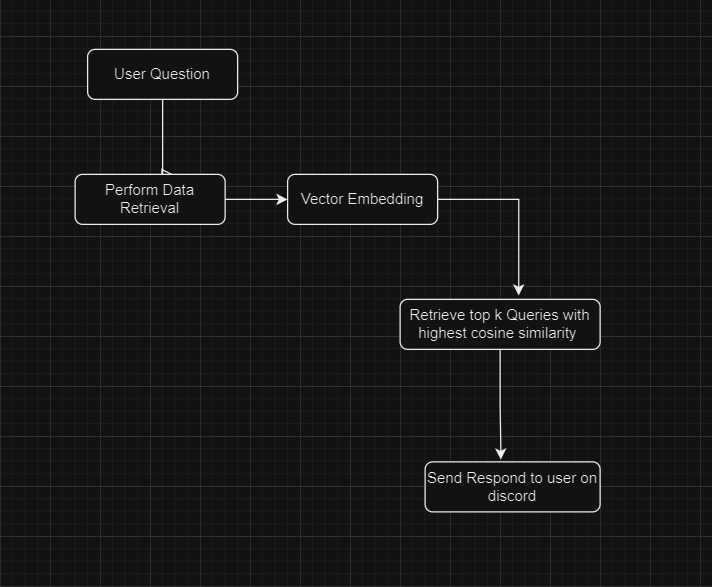
To ensure access to the latest context-aware data, we periodically scrape data from Discord server chats and web portals. This data is then parsed, chunked, indexed, and converted into vector embeddings, which are subsequently pushed to our vector database, Annoy DB.
Whenever MaruBot receives a question, we perform context-aware data retrieval from the Annoy DB, retrieving the top k queries with the highest cosine similarity to the user's question. We leverage this data to perform Retrieval-Augmented Generation, providing personalized and intelligent answers to the queries.
Based on the helpfulness of the context in retrieving the data, we mark the response as 'red' or 'green' depending on their confidence level. A green bubble indicates that MaruBot is using the chat history and is confident in its answer, avoiding hallucinations. Conversely, a red bubble signifies that MaruBot is relying on its training data and will not provide a context-aware answer.
Additionally, we implemented a regular expression (regex) to exclude personal user information, such as email addresses, credit card numbers, and private keys, from the retrieval process, ensuring the protection of sensitive data.
Challenges we ran into
Scheduling and Webhooks
One of the significant challenges we encountered was the lack of readily available scheduler APIs for Discord and Slack. This made it difficult to implement functionality that required calling or fetching data at specific intervals. To overcome this, we had to explore alternative approaches, such as leveraging webhooks or implementing our own scheduling mechanisms using external services or libraries.
Information Retrieval and Vector Decoding
The information retrieval part of the logic presented several challenges. One of the main hurdles was decoding the vectors to retrieve the original messages, which were required to provide context to the Large Language Model (LLM). This process involved intricate vector operations and efficient data structures to ensure fast retrieval and accurate context generation.
Session Management and User Awareness
Implementing session management in chatbots is a non-trivial task, especially when dealing with externalized deployments. To maintain user awareness and personalization, we needed to store server-specific tokens or session identifiers in a separate database for each server.
Handling Document Objects
Working with document objects posed a unique challenge as they often contain large amounts of data, unlike the more concise format of text messages. Preprocessing and efficiently storing these document objects required us to parse, chunk, and index the document for rapid retrieval and context generation.
Accomplishments that we're proud of
Successfully developing a functional Discord chatbot and Chrome extension that leverages advanced AI models.
Successfully managing to find a workaround for the limitations of the Discord scheduling API.
Being able to learn about Retrieval-Augmented Generation (RAG) and semantic analysis on the go and successfully implementing them in our project.
While facing chances of failure multiple times and hitting paywalls, being able to see the chatbot through to completion was a very proud feeling.
What we learned
Advanced techniques for natural language processing (NLP) and conversational AI-like retrieval.
Augmented Generation and Information retrieval.
Learnt about making chat bots and web extensions.
Learnt about different types of workflows like event listening, triggers, and schedules.
What's next for MaruBot
Making it available universally across both Discord and collaborative chat platforms like Slack and Teams.
Improving the quality of MaruBot's responses by fine-tuning, few-shot learning, and advanced embedding models.
Expanding MaruBot's capabilities to be able to parse through a website's sitemap and provide rich semantic search functionality for the website.



Log in or sign up for Devpost to join the conversation.