-
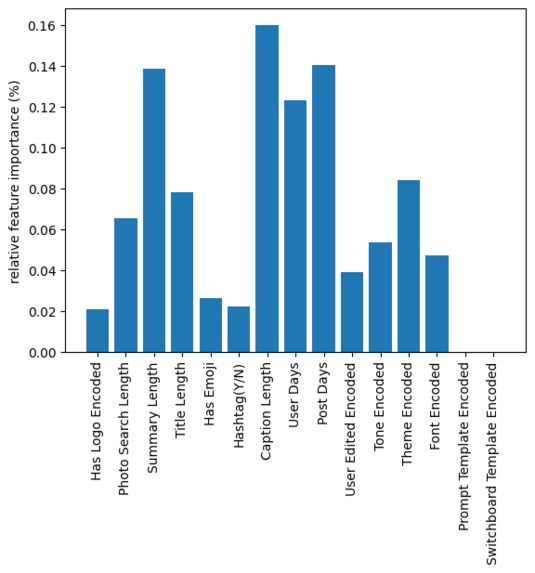
Feature Importance
-

Challenge, Data Preprocessing, Feature Selection
We were given a dataset of social media post features and took the easiest features to encode and use in our model. For our features, we used the Font, Theme, Tone, User Edit, Logo, Prompt, and Switchboard Template. When encoding the captions, we focused on the number of words, the emoji presence, and hashtag presence, leading to Caption Length, Emoji, and Hashtag. We also decided to look at how long the user had used the website and how old the post is, leaning to Post Days and User Days. We determined that some of the features weren't easily encoded into a few categories, so we ignored these complex features in favor of simple ones. Attached is an example picture of our training data.
Model Development, Hyperparameter Tuning
We tested a few different models using K-fold cross validation, but the difference in errors was very minimal. As a result, we decided to utilize Random Forest, as it's a usually strong performer and easy to interpret. We were able to hyperparameter tune our Random Forest model using a grid search on the number of trees, tree depth and loss function.
Results
Our results were a score of 0.7464 on Kaggle. We were alsoable to visualize our feature importance since we utilized the Random Forest model. We found that most important features were caption length, summary length, and the age of the user and the post. This creates value because you could run A/B testing on the most important features to tune your model to make the most approved content generally.
Challenges, and Mistakes
One of our biggest challenges was deciding which features to include or not. Many features were too complex for simple evaluation, and were probably a project on their own to extract some form of information or to convert into a more latent representation. We also made the mistake of not employing more statistical tests to find insights within our data, so while our model performed decent it may not be as robust. We also did not employ version control, as a result we had some roadblocks with inconsistent data that we decided to fix.
Moving Forward, and What We Learned
While we may not have gone through a more rigorous process compared to more established teams, our team was able to learn a lot about the scientific process and machine learning. With more time and resources we could have employed deep learning for classification, and a more rigorous training process for hyperparameter tuning. We could have also done a more exhaustive approach and throwing even more models during our model selection phase, but we decided to aim for interpretability to aid in business decision making. Our model is relatively lightweight, so model deployment within an API would be relatively easy, as well as being able to train the model for future use.

Log in or sign up for Devpost to join the conversation.