



Inspiration
AI tools have made rapid content creation more accessible for businesses. We were interested in using AI to solve a real market need and create something useful at the 2023 Datathon. We were also inspired by the ability to work with a real dataset.
What it does
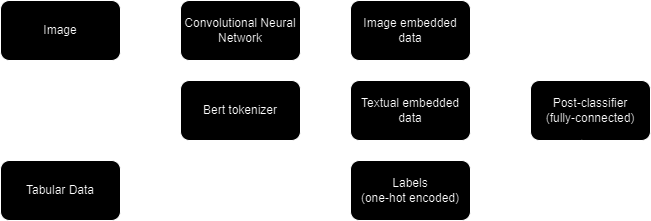
Our model trains on user approval data to learn what posts will be accepted or declined in the future. Both the image and tabular data were used as inputs to the model. Long form language data such as the caption, title, and text within the image was embedded. Categorical data, such as the tone and template, was one-hot-encoded. Finally, the image itself was analyzed. Combining these three streams of information together proved to be a complex task, but the understanding generated by our model provides insight into effective social media post creation.
How we built it
Our model was built using three different models that aggregate into one single prediction. Text/language data was embedded using a bert tokenizer, image data was embedded using a convolutional neural network. The text and image data were fed into an attention network, the result of which was combined with categorical data to a final fully-connected post-classification layer. The outline of this process is shown in the attached flowchart.
Technologies used included pytorch, pandas, pillow, Google Vision OCR, and a bert tokenizer. Many elements of our system were heavily customized.
Challenges we ran into
One of the challenges we faced was that choosing the right cloud services, API’s, and code libraries is not as simple as picking the most common or accessible. For example, when extracting text from the images in the dataset, we originally planned to use a common OCR (optical character recognition) library like Tesseract. However, the quality and consistency of our model was hindered by the inconsistency of Tesseract. By taking inspiration from previous Datathon winners and researching other models, we found that the Google Cloud Vision OCR served us the best.
Examples such as this popped up throughout the creation process. From a custom pytorch dataset to a custom post-classification network, many elements of the system were designed with the Marky challenge in mind.
Accomplishments and What we learned
All 4 of our team members had prior coding experience, but 3 of us were relatively new to using advanced neural networks making this a tremendous learning experience. In the process of building the model, there were a number of concepts and data processing techniques that we utilized as the model reached its final stages. For example, we needed a way to encode categorical parameters without misrepresenting them with integer values, as this gives the illusion that value 1 is closer to value 2 than it is value 3. Instead we used vectors with dimensions of the number of parameters. Each parameter is assigned a vector, where the components of the vector are binary values. This is known as “one-hot encoding” and came in handy for our non-text and non-image information.
What's next for Marky.future
As the name implies, there is plenty left for this product. The model can continuously be improved, and as we learn more about the specific details which have greater impact on user approval and obtain more data, we will consistently be able to improve our model’s ability to make predictions. There are a few user metrics in particular that we feel would be extremely beneficial to the accuracy of our model. The information provided to us does not tell us much about the user themselves. Additional information about the user could help us predict whether or not that user would approve that content. This personal information could be used in combination with general data, similar to how algorithms on social media use both the user's preferences and the “quality” of a video to predict how likely a user is to watch a video.
Furthermore, because our model is comprehensive it can be tuned according to the features that are the most important. Our model is a framework that provides tools to analyze every part of a post; future iterations can disable certain parts of the model to ensure faster training or a better fit.

Log in or sign up for Devpost to join the conversation.