-
-
MARKET PIXEL OFFERINGS
-
MARKET PIXEL CUSTOMIZATION
-
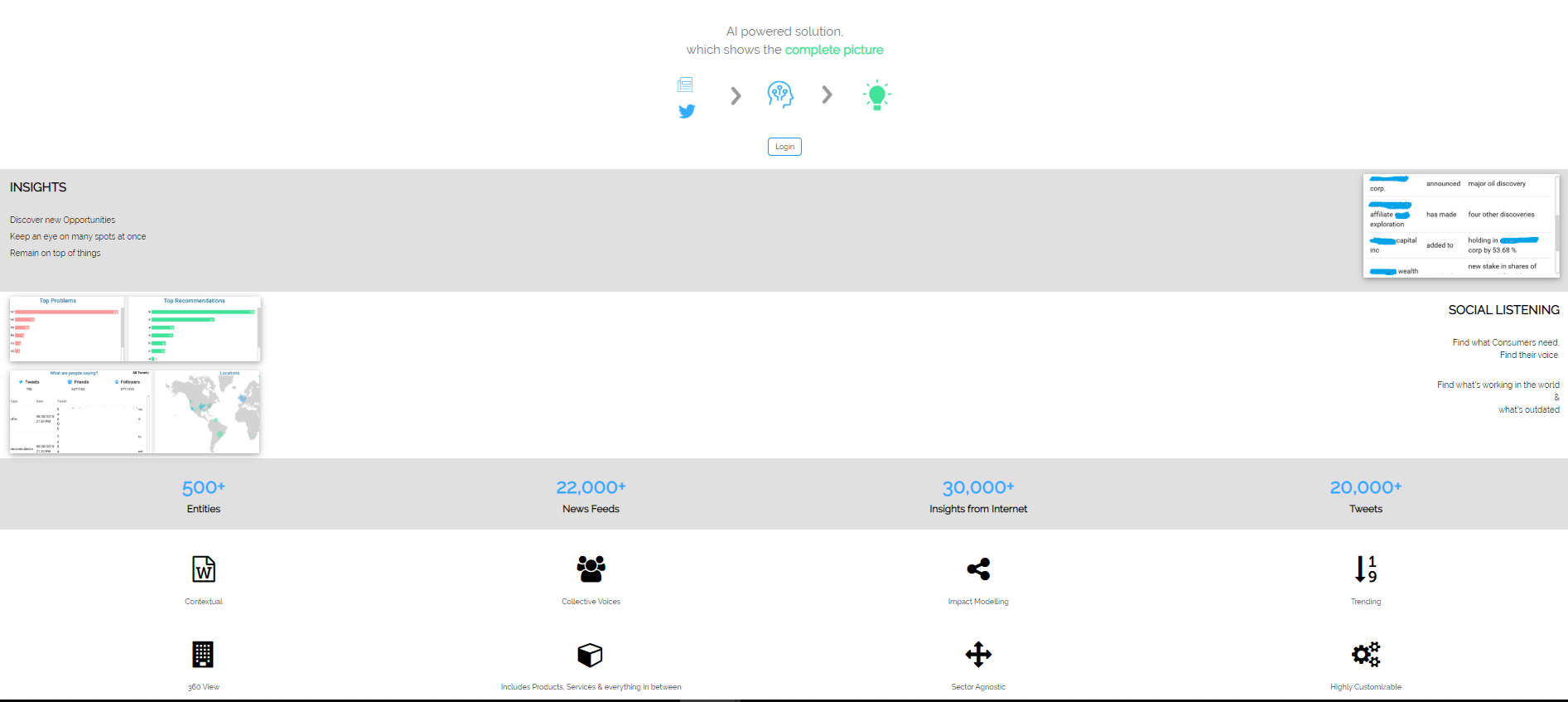
INSIGHTS
-
SOCIAL LISTENING
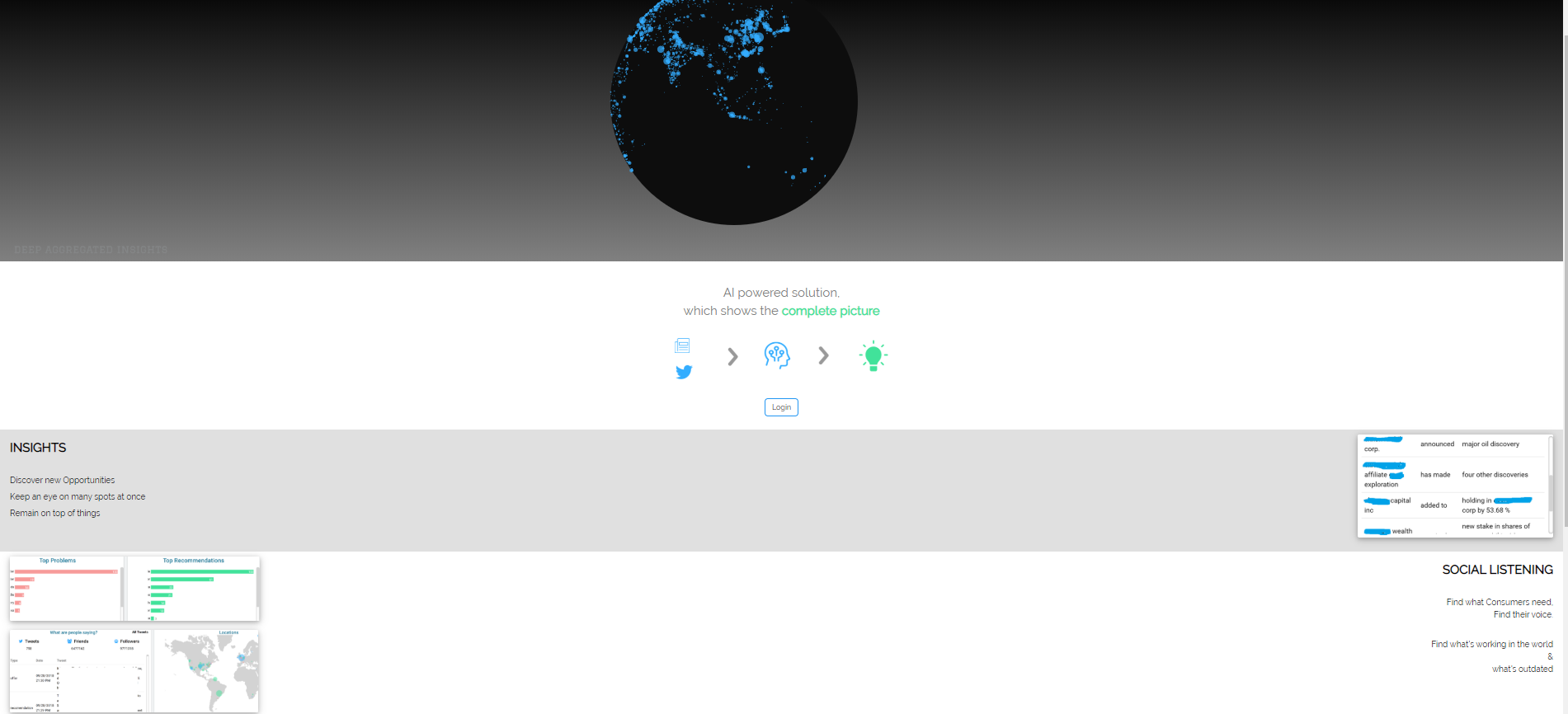

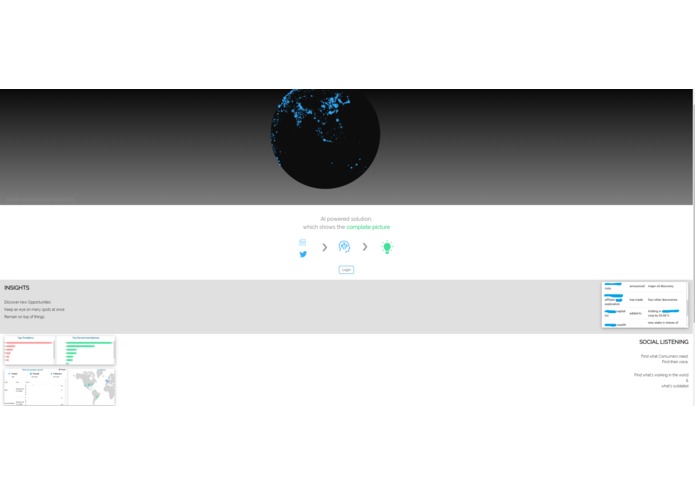
Of late we have been working on areas which can help the Markets team, and we realized that Asset Managers & Traders often rely on internal research teams & more inhouse data to base their decision. They do have subscriptions to Bloomberg & Reuters, but often don’t take insights from other social & public channels. Some more digging & we realized that this pertains to decisions on ~$Trillion Asset Under Management of which each of the Big 4 US banks holds about $1.5 Trillion. What we got KNOW to is that data which can help Assets managers is just not 1-dimensional (like in-house research) but is omni-channel (and it comes from multiple directions such as news articles, social media, global geo-political que’s, in house research and many more). And this was the basis on which we started working on our idea MARKET PIXEL for OTC Trading Desk– A solution meant to be the Eyes & Ears of an Asset Manager for tomorrow. Using the Static Data for Trade Capture API </> The soln. scans Data across sources as varied as news, articles, reports, blogs, search results, social networks, forums like Twitter, Facebook, Reddit, Instagram, reviews, ad engagement, and website click stream. Very simply put, It then applies (artificial) intelligence to it and generates actionable and verifiable insights which can drive the big business decisions of Asset Managers of Future.
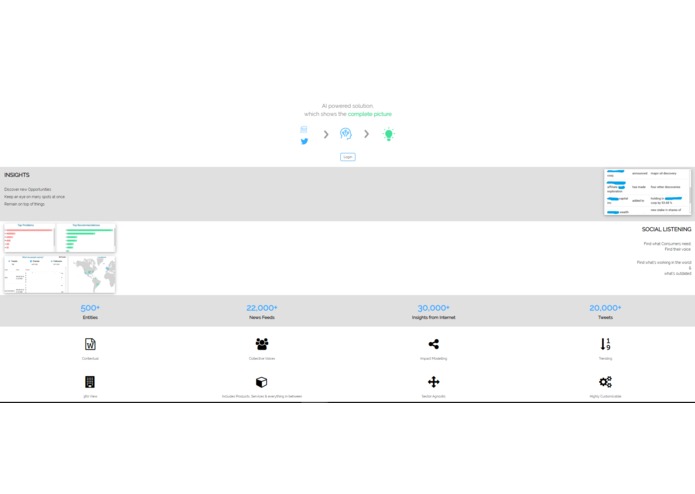
Let me show you a DEMO of what we have achieved thus far – We have sourced a data based of 500+ entities (the likes which Assets Managers are often trading or exchanging collateral of), 22,000+ News Articles from various sources and 30,000+ Intel from those Articles and 2000+ tweets to base our model here.
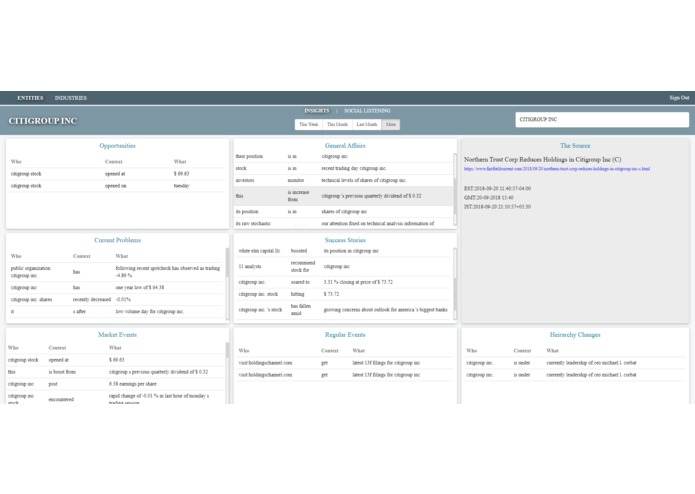
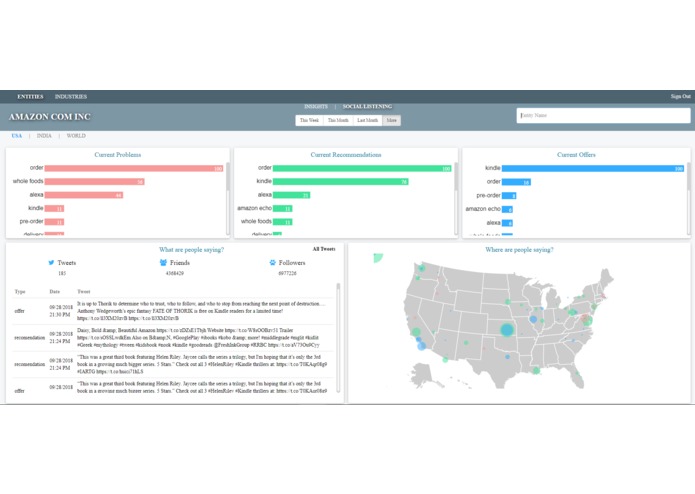
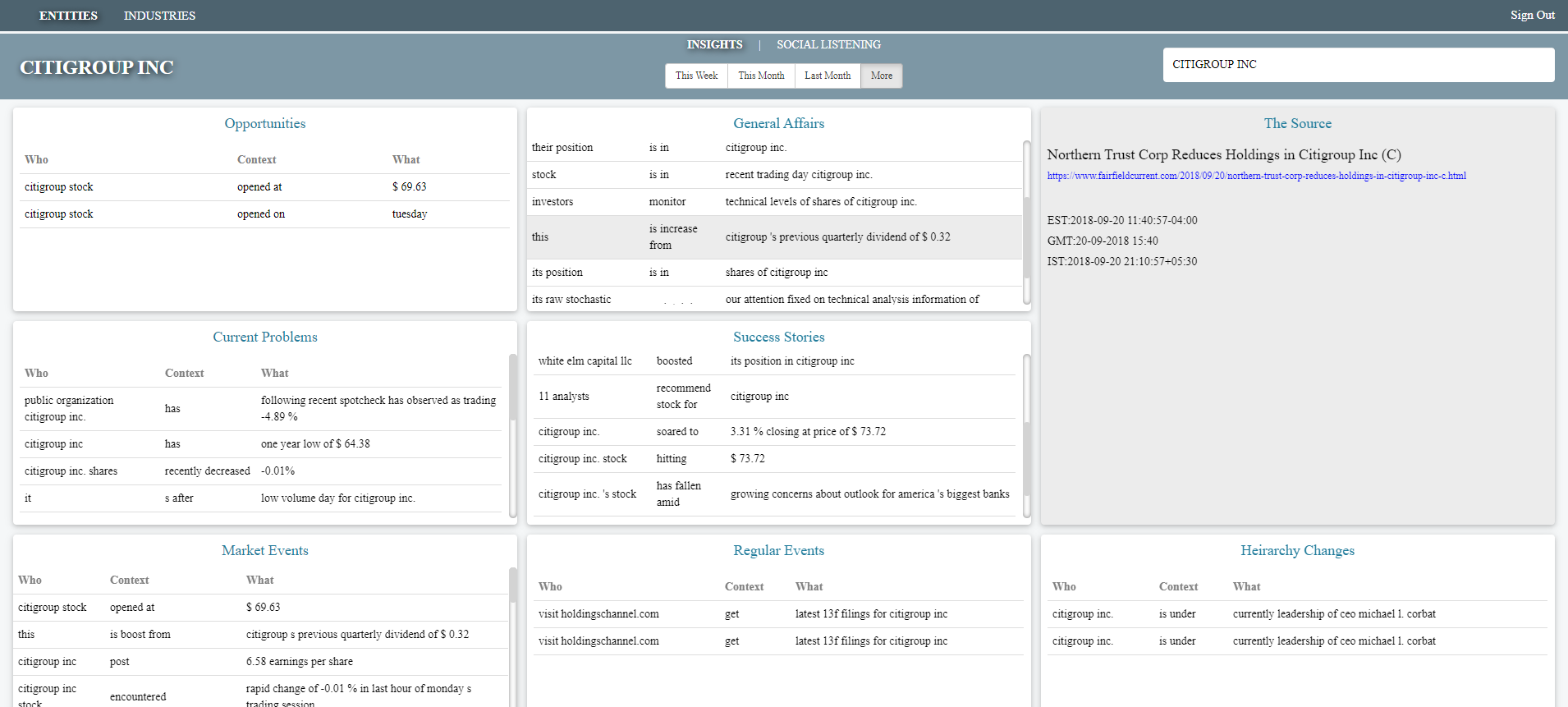
If I were a Asset Manager/Trader how would this work – I go into the Soln. and then search for JPMC, CITIGROUP, BEST BUY CO INC So the intel/insights you are seeing came from the article from the web links, and that’s all an asset manager/trader needs to know without having to manually read through the whole article.
From a Technical view point we have used algorithms around Open Information Extraction using proprietary Decision Theory and have also developed a proprietary algorithm with a layer of dominating rules and finally layer which kicks off the aggregation and impact modeling At this point our accuracy/confidence is 75% and we are working on improving this. Our soln. is modular and can take in information from many many sources via API plug-ins (which ever the bank has already paid for like Bloomberg etc. etc. etc.)
"We are looking onto revamping the architecture with some cutting edge state-of-the-art classifier and fine tuning some lemma based dictionary control model using mnemonic generation to resolve further propositions and participles with certain learning at its core. Looking onto a sampling based algo for knowledge graphs on existing database structure consisting of semantic triples (subject, predicate, object) so that the inference grow exponentially"
Built With
- ai
- d3.js
- finastra
- heroku
- java
- machine-learning
- multithreading
- natural-language-processing
- openie
- python


Log in or sign up for Devpost to join the conversation.