-
-
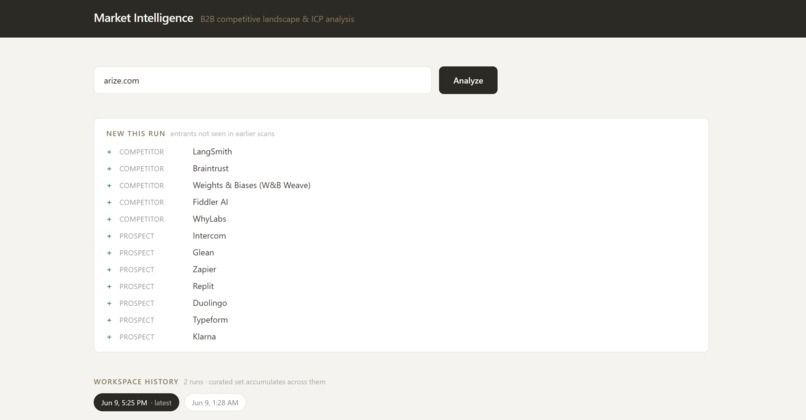
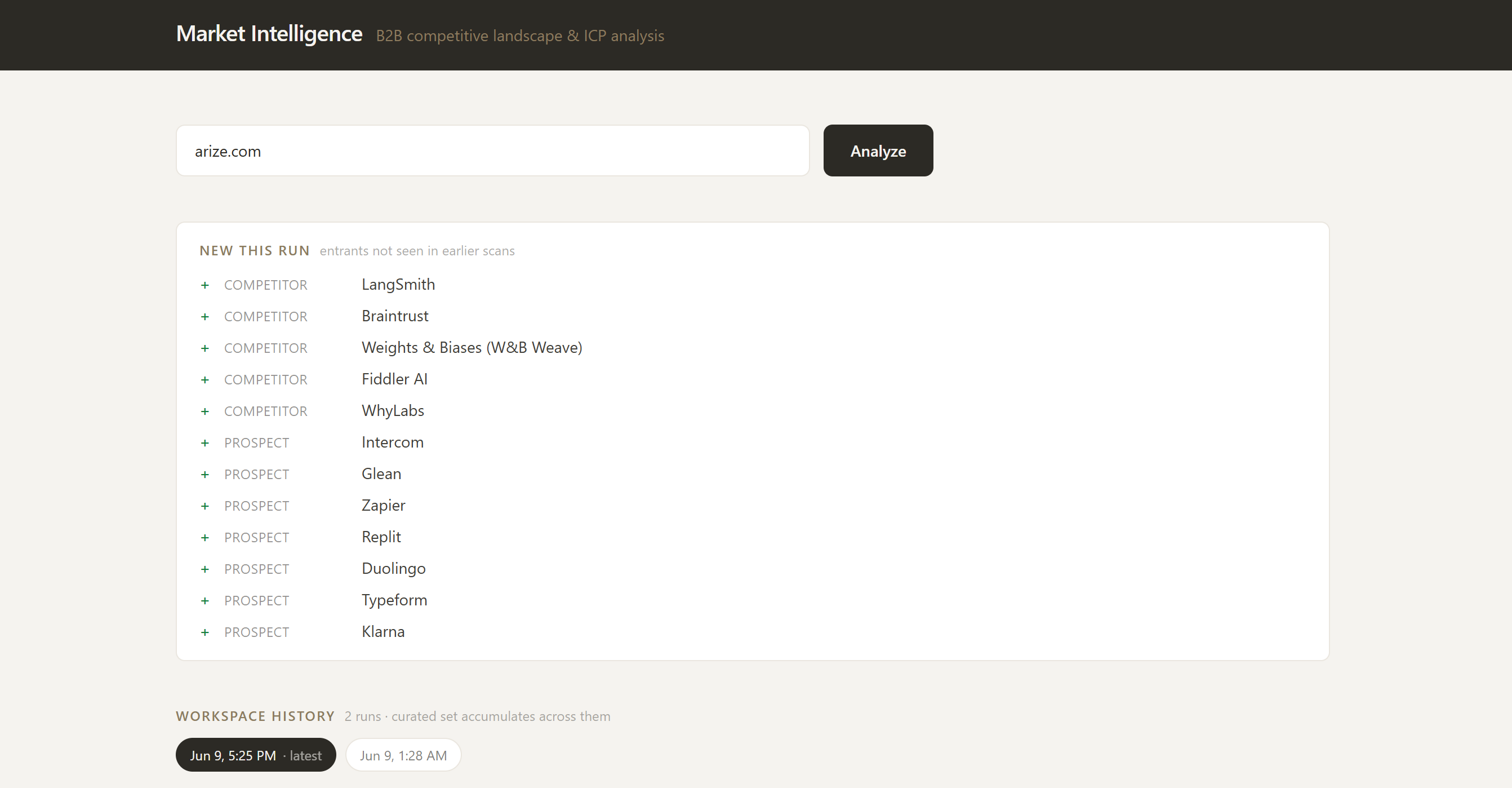
Arize Example: New this Run
-
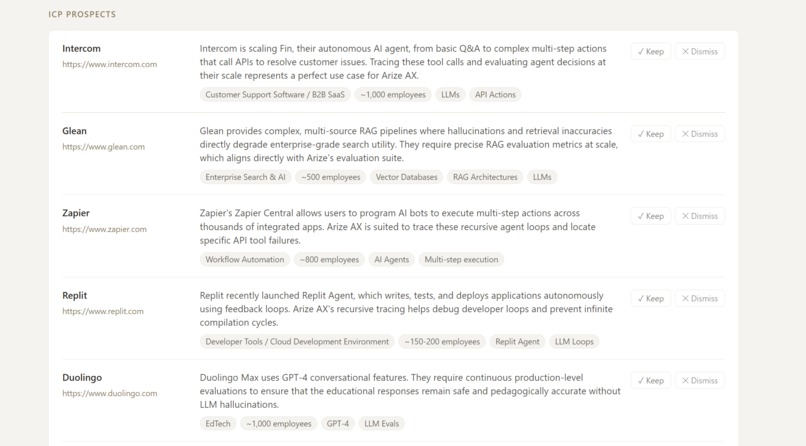
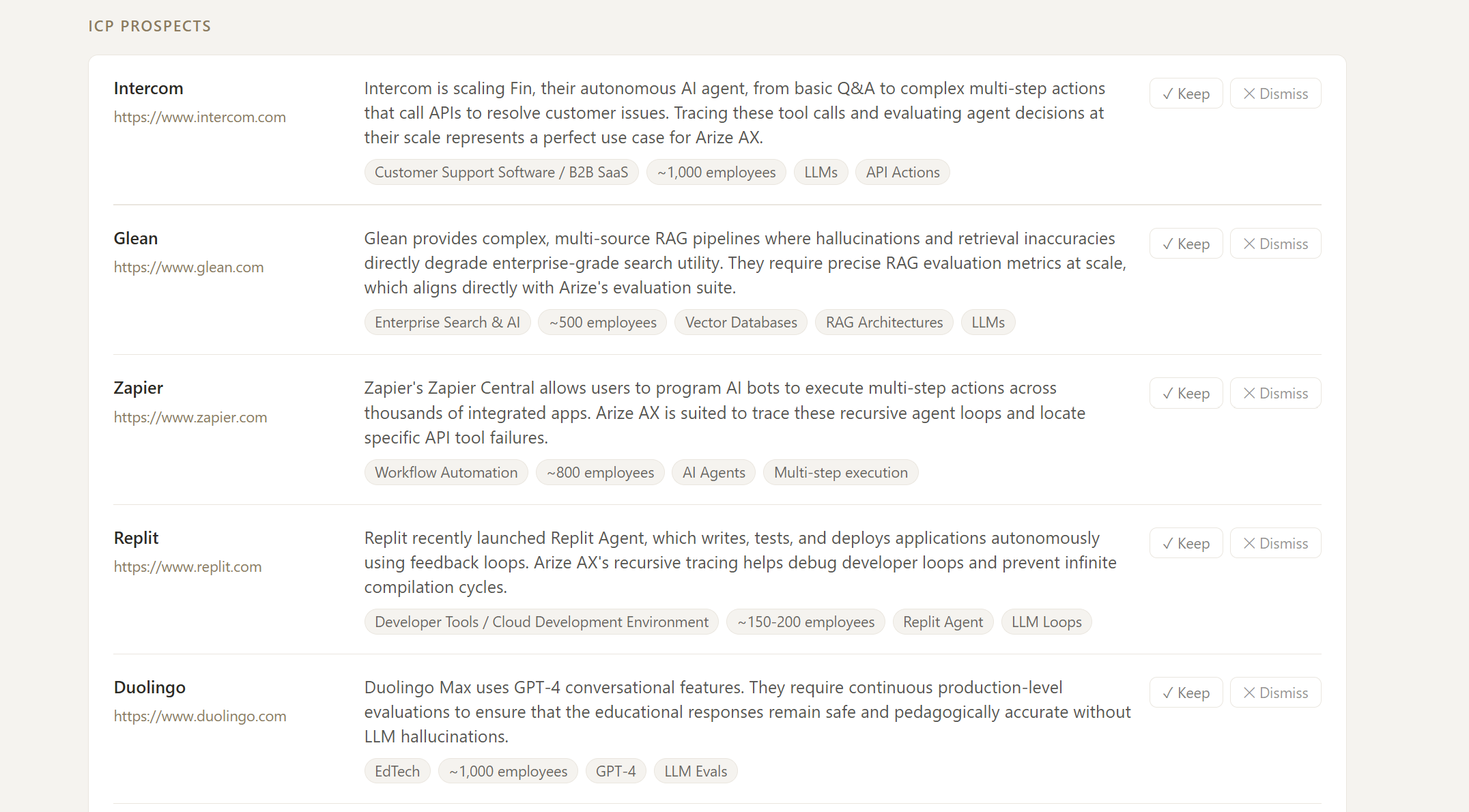
Arize Example: ICP Prospects
-
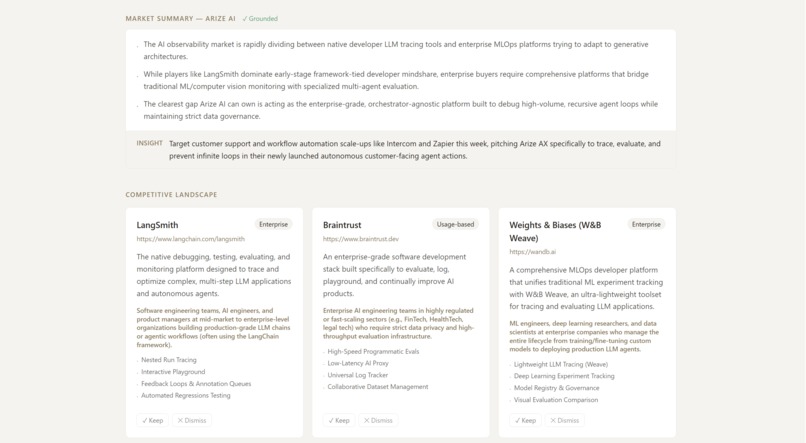
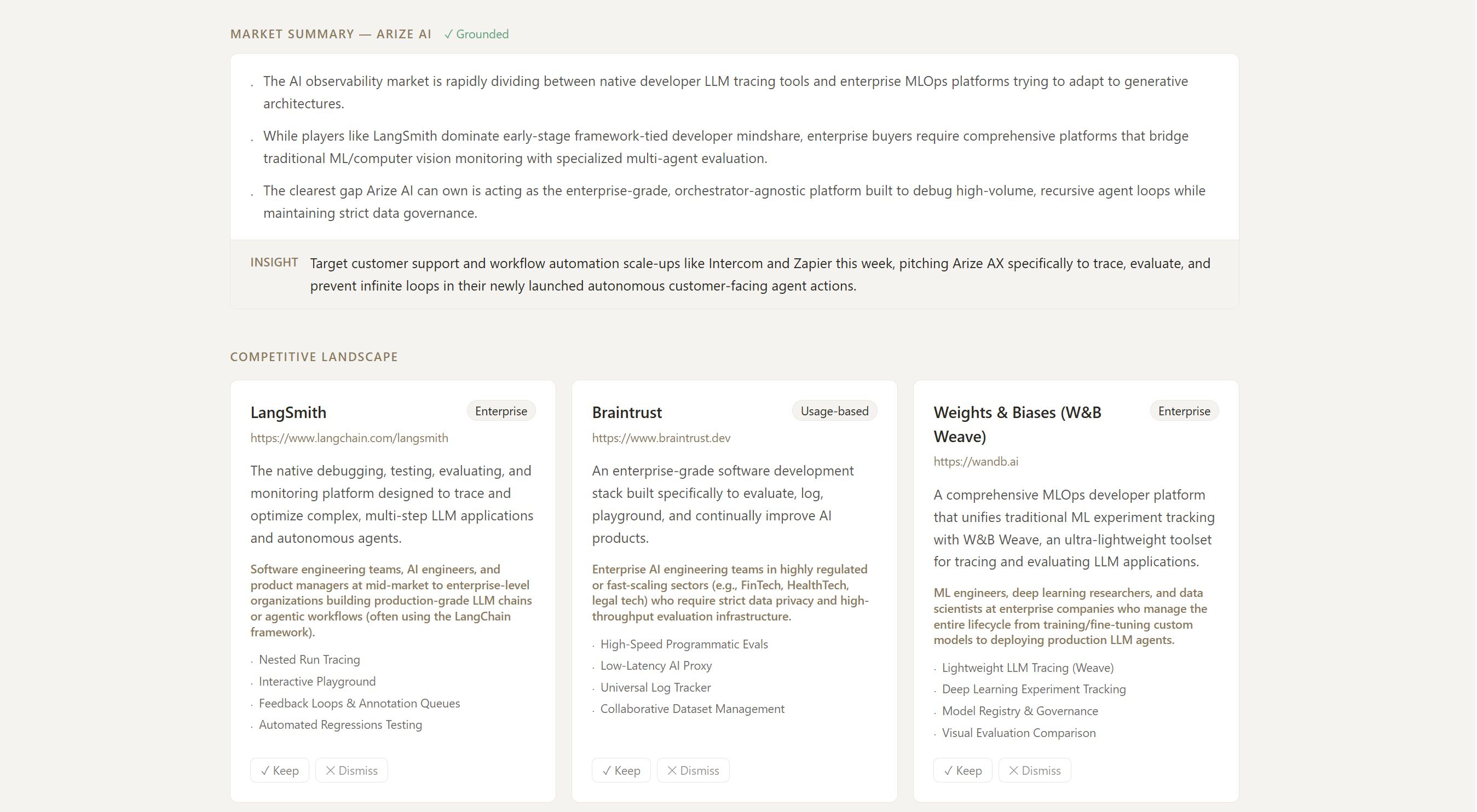
Arize Example: Market Summary and Competitors
-
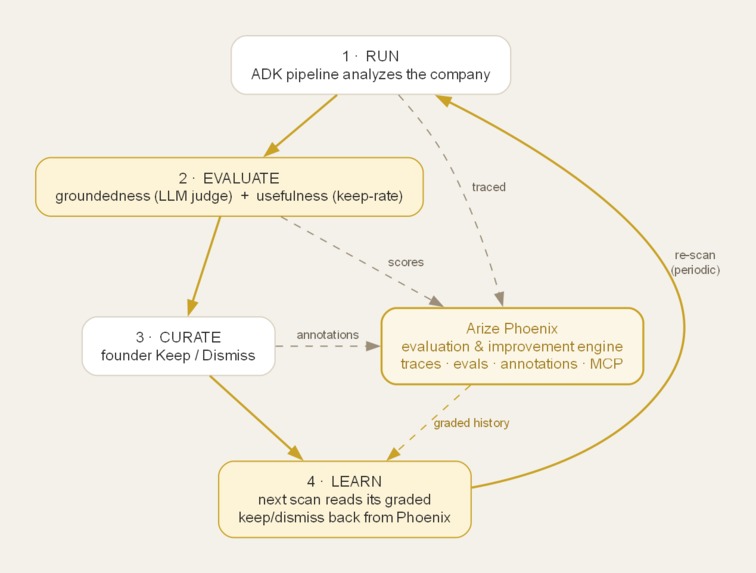
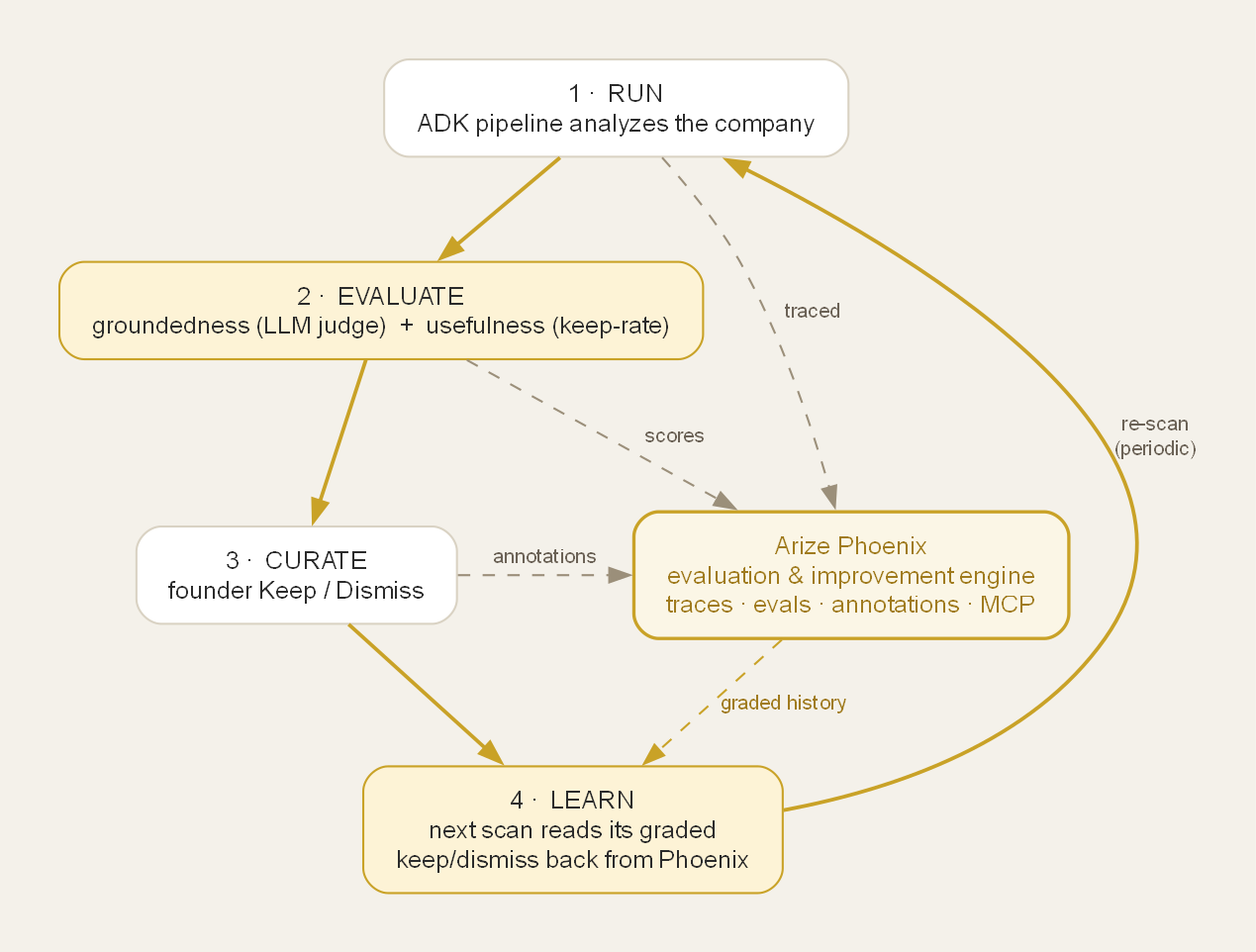
Self-Improvement Loop
-
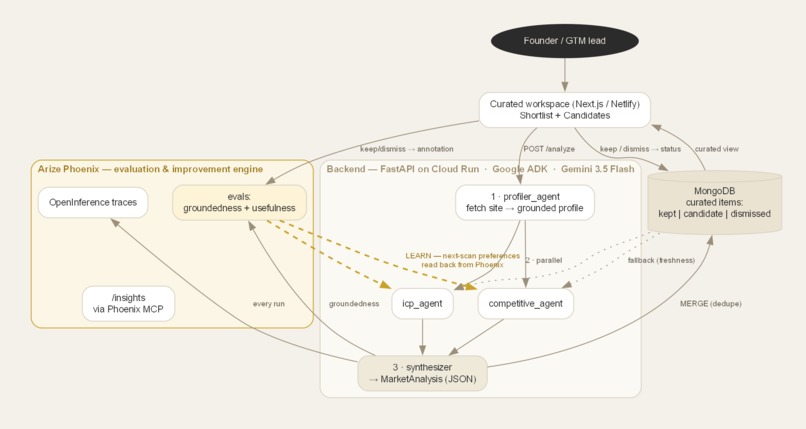
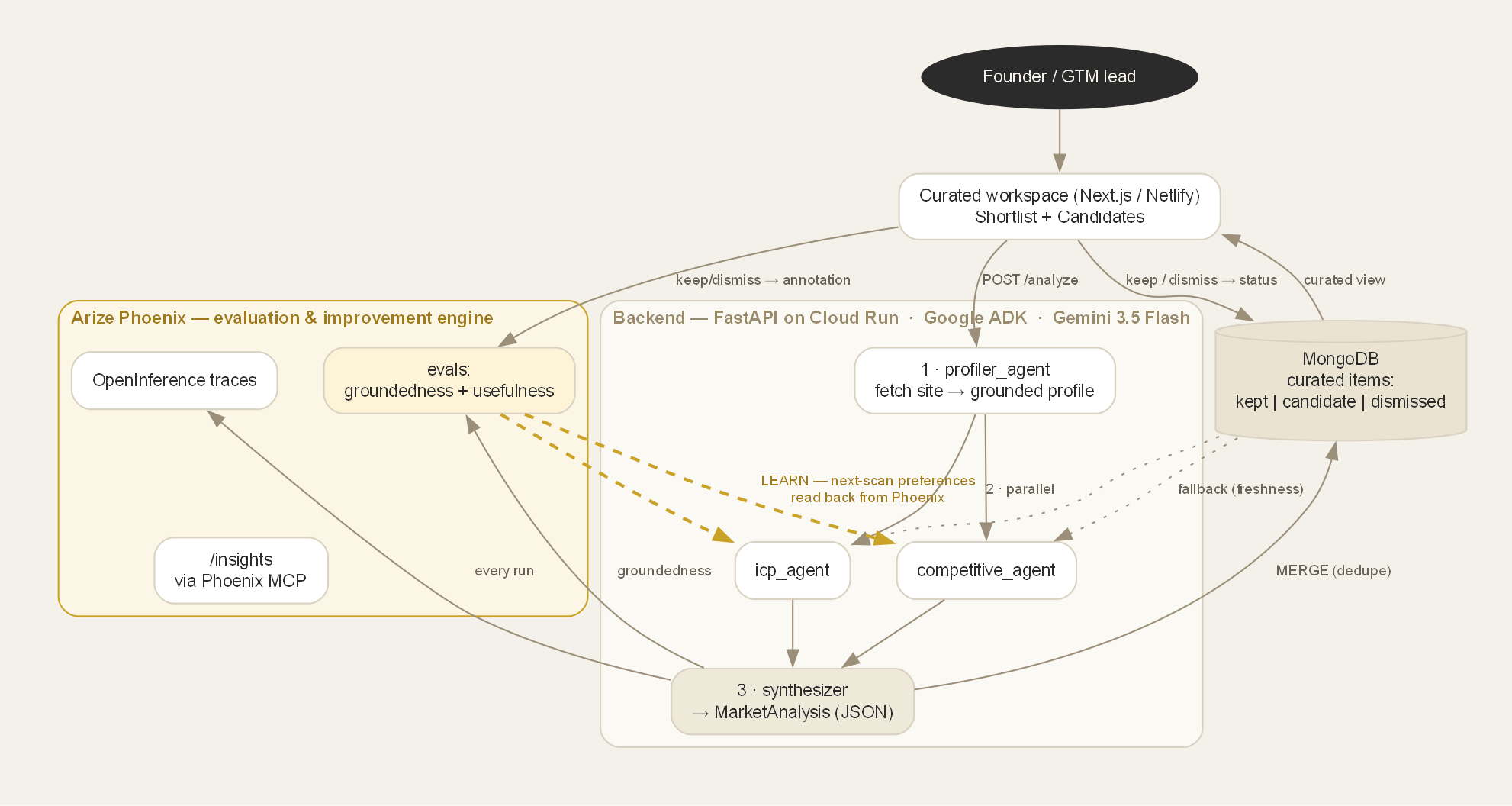
Architecture
-
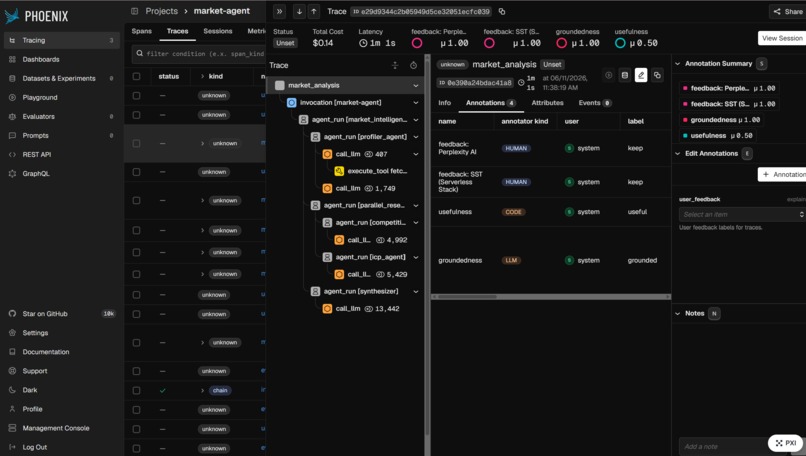
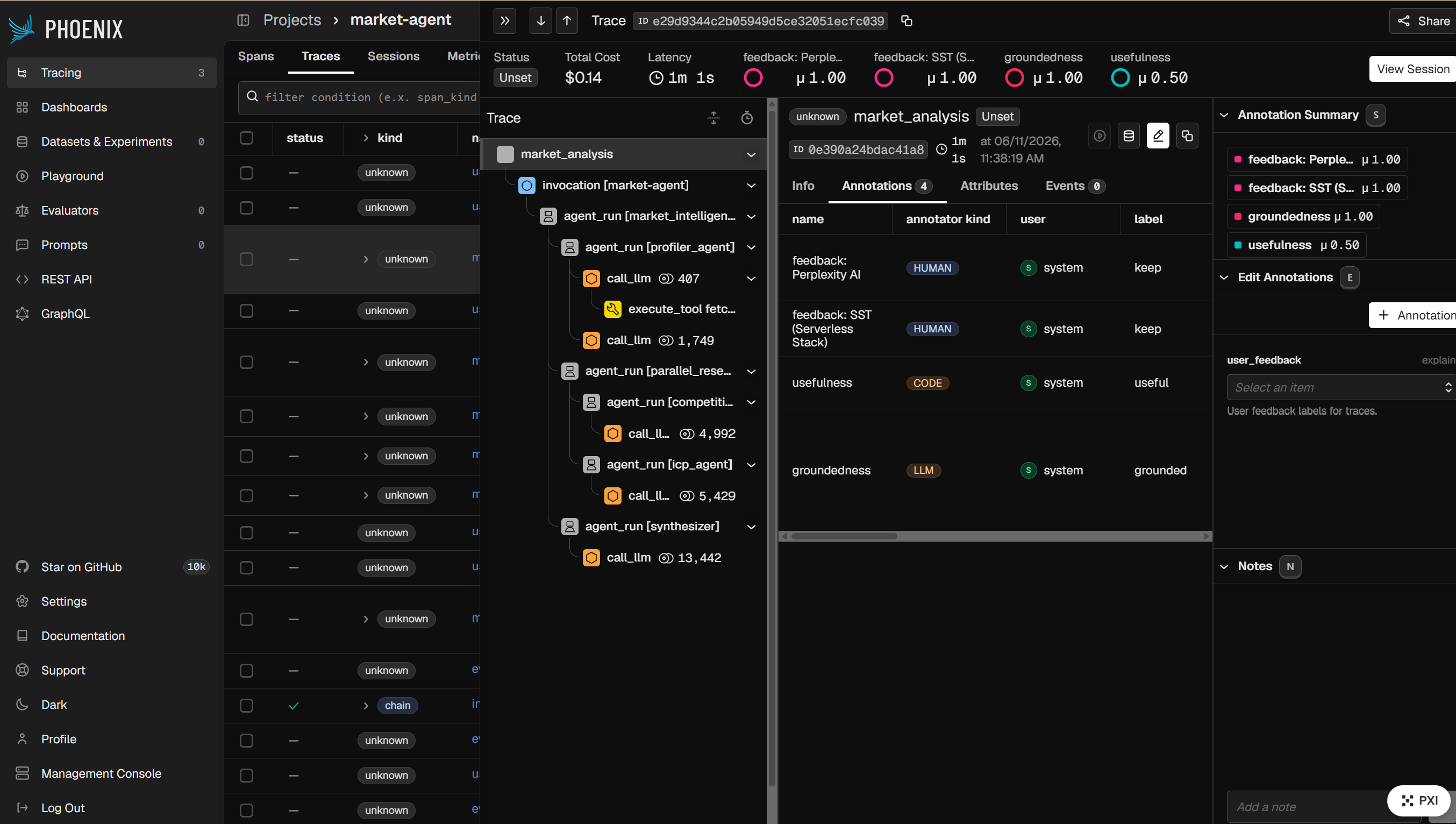
Phoenix-Arize-Traces-with-Annotations
Inspiration
The problem I identified was that founders, GTM leaders and product managers burn hours every week manually researching competitors and prospects, it's repetitive, but requires judgement.
I wanted an agent team that does the research and gets better the more you use it, so the judgement you apply compounds over time. I leveraged Google ADK to create our agent team, and created "self-improving" agents by applying Arize Phoenix.
What it does
Give it a B2B company URL and it maps the competitive landscape and surfaces ICP-matched prospects in one pass. Then it becomes a living workspace:
- Grounded: a profiler agent reads the actual site first, so no hallucination occurs.
- Accumulate-and-curate: re-scans merge into a persistent, deduped set. Keep pins an item to your shortlist; Dismiss hides it; untouched items stay candidates. (Nothing silently vanishes.)
- Learns your judgment: your Keep/Dismiss shapes future scans, and that signal is read back from Phoenix.
- Trustworthy: every analysis gets an LLM-as-judge groundedness score; the badge only warns when something's off.
How we built it
- Agent: Google ADK pipeline on Gemini 3.5 Flash — profiler → (competitive ∥ icp) → synthesizer with structured JSON output.
- Backend: FastAPI on Cloud Run (Python + Node for the MCP server). MongoDB holds the curated workspace.
- Frontend: Next.js on Netlify, calling the backend directly.
- Arize Phoenix — the evaluation & improvement engine:
- Tracing: OpenInference auto-instrumentation streams every agent/LLM/tool span to Phoenix Cloud.
- Evals: a groundedness LLM-judge on every run + a usefulness (keep-rate) eval from human feedback, both tenant-tagged.
- MCP: the agent introspects its own traces/evals at runtime via the Phoenix MCP server.
- Closed loop: the next scan reads the tenant's graded keep/dismiss history back from Phoenix to improve and the agent learns from its own evaluation record.
Challenges we ran into
- Domain-name hallucination: the original agent guessed companies from the URL; I fixed it with a grounding profiler step (and an eval that proves it's fixed).
- "Self-improving": I separated the fast loop (Mongo, fresh) from the learning/measurement engine (Phoenix), and leaned into time-separated re-scans so reading the signal from Phoenix is both correct and meaningful.
Accomplishments that we're proud of
The highlight is a measured self-improvement loop: the agent is scored on truth (groundedness) and usefulness (keep-rate), learns from its own Phoenix record, and I can watch the metrics in the dashboard.
What we learned
Evaluation becomes the "moat" and "magic" for agentic systems. Arize/Phoenix turned "trust me, it learns" into an observable, grade-able loop, and forced an honest architecture (product memory vs. evaluation engine).
What's next for Market Intelligence Agent
Multi-tenant auth (the tenant dimension is already wired throughout), monitoring additional market signals (like G2/Reddit), scheduled re-scans and Phoenix experiments + fine-tuning on the accumulated graded dataset.
Built With
- arize-phoenix
- claude-code
- fastapi
- gemini
- github
- google-adk
- google-cloud
- mongodb
- netlify
- nextjs


Log in or sign up for Devpost to join the conversation.