-
-
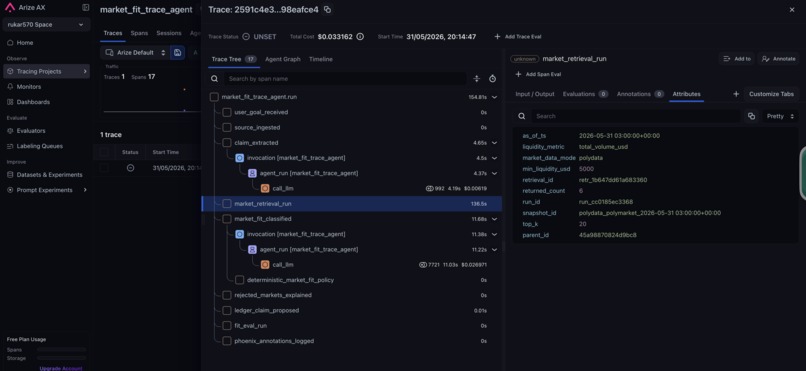
arize trace tree
-
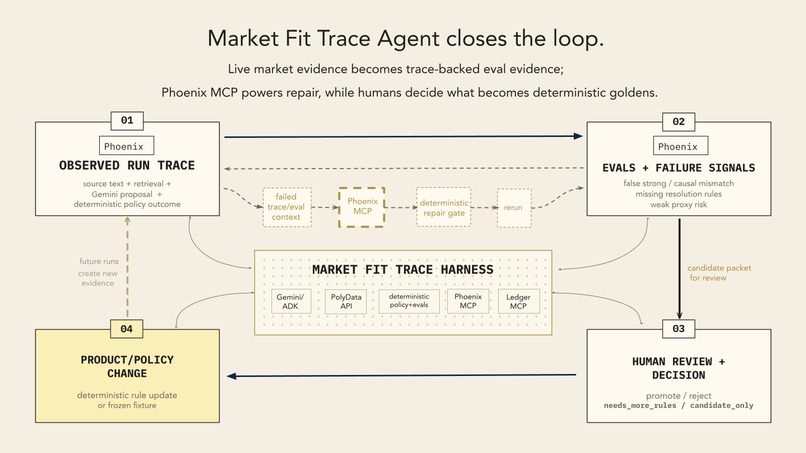
closing loop
-
agent graph arize ax
-

stress test

Inspiration
Most teams do not lack opinions; they lack tests for their opinions. Prediction markets are useful here because they force a messy belief into a resolvable contract: what happens, by when, according to what source. The dangerous failure is choosing the wrong test — a related market that looks relevant but is only a weak proxy. Market Fit Trace Agent makes that failure visible, auditable, and correctable.
What it does
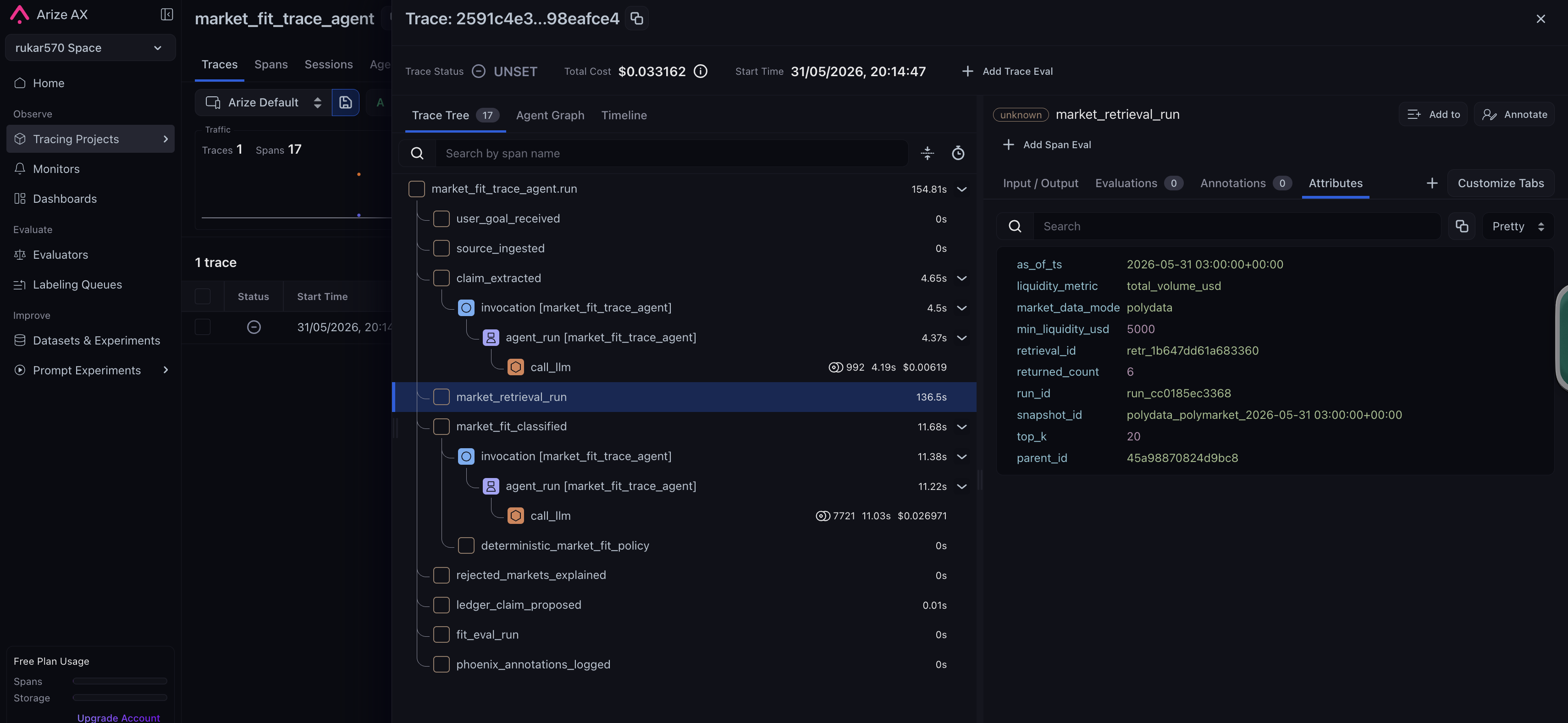
The app accepts a pasted thesis or source, extracts a normalized claim, identifies entities, horizon, and stance, retrieves a bounded set of relevant current Polymarket markets in product mode, and classifies fit as direct, indirect, weak_proxy, or no_clean_expression. The stable proof path and strict evals replay frozen market snapshots so regressions remain meaningful.
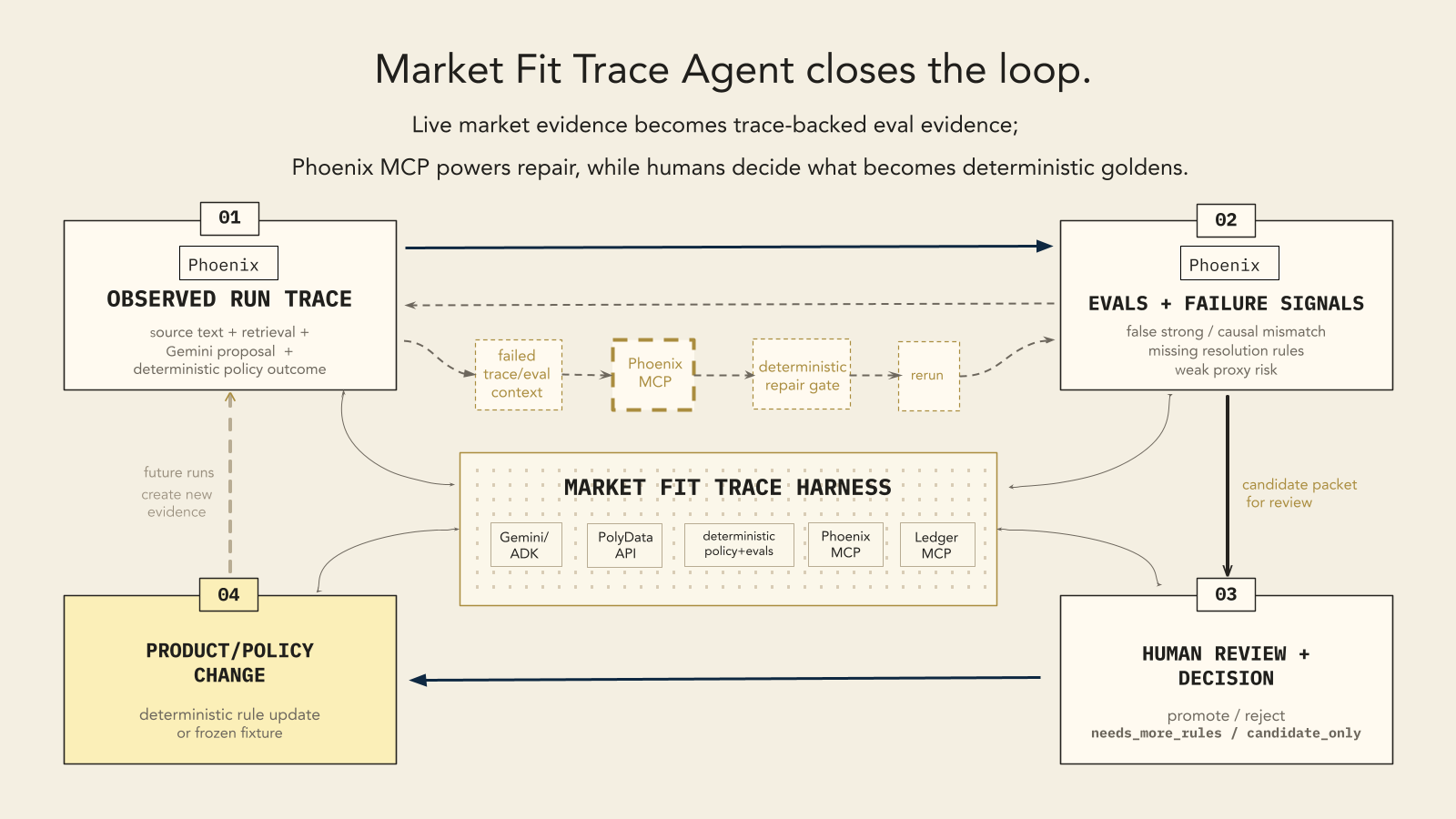
The trace-repair demo starts with a tempting market match that looks relevant but is too weak to trust. The first run overstates the fit by treating an adjacent market as stronger evidence than it deserves. A trace-linked eval flags the false strong recommendation. Phoenix/OpenInference traces make the failure inspectable, Phoenix MCP supplies trace context for the improve step, and the second run downgrades the market to weak_proxy.
The practical value is not finding "a related market"; it is preventing a user from mistaking a correlated or adjacent market for a clean expression of their thesis. The result is not open-ended chat. It is a supervised audit workflow with state, tools, evals, human review, and trace-backed correction.
How I built it
The backend is a FastAPI app wrapped around one deployable Google Cloud Agent Builder agent, built code-first with the Agent Development Kit (ADK). Gemini 3.5 **flash is accessed through the **ADK runtime for claim extraction and proposal steps. Deterministic Python code performs the final market-fit classification, weak-proxy checks, trace-linked evals, and human-verdict handling.
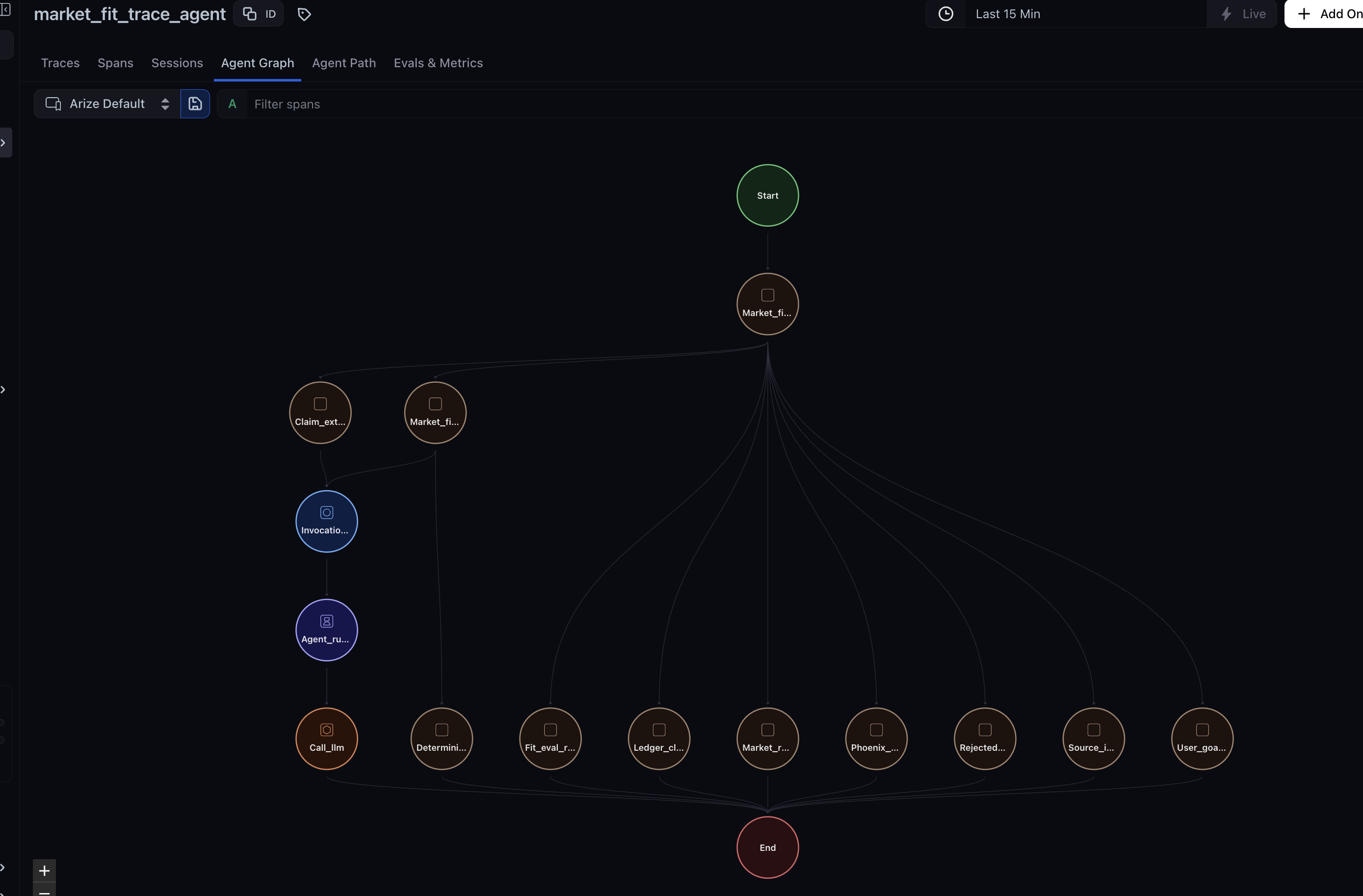
For the Arize track, the app emits OpenInference-compatible traces to Phoenix, including ADK/Gemini spans, market-retrieval spans, and product-level fit/eval spans. Phoenix MCP is used by the improve step to inspect failed trace/eval context at runtime. The project also uses Phoenix Datasets and Experiments for golden governance: trace-backed live retrievals become candidate review rows, reviewed fixture goldens are mirrored into a promoted-golden Dataset, and Phoenix Experiments compare current policy output against expected labels.
Built With Partner Track
Arize/Phoenix is used in seven ways:
- OpenInference instrumentation sends ADK/Gemini, market-retrieval, and product-level spans to Phoenix.
- Trace-linked evals annotate failures such as
false_strong_recommendationandweak_proxy_detected. - Phoenix MCP is used during the improve step to inspect failed trace/eval context at runtime.
- The second run uses that trace context to downgrade an over-strong market recommendation to weak_proxy.
- Phoenix Datasets organize trace-backed live retrievals as candidate review cases and reviewed fixture goldens as promoted eval assets.
- Phoenix Experiments compare current policy output against expected labels on promoted goldens.
- Governance artifacts preserve failed traces, candidate review rows, promoted goldens, and experiment results so observed failures become regression pressure instead of disappearing after the demo.
Phoenix MCP is valuable in this harness because it turns failed runs into repair context. It exposes policy blind spots we had not encoded yet, then lets the next run apply a deterministic repair gate instead of silently repeating the same false-strong recommendation.
This is why Phoenix is part of the agent's correction and eval-governance loop, not only backend logging.
Challenges I ran into
The main challenge was making the Arize/Phoenix integration meaningful rather than decorative. The trace had to become part of the product loop: first run, failed fit judgment, trace-linked eval, Phoenix MCP inspection, improved second run.
The second challenge was maintaining a strict trust boundary: Gemini may draft, extract, and explain, but deterministic code performs the final market-fit classification and eval scoring.
A third challenge was preventing live retrieval, candidate review, and strict eval truth from collapsing into one thing. Live PolyData rows are evidence; reviewed fixtures are eval truth; Phoenix Datasets are governance surfaces. Keeping those boundaries explicit was necessary so the demo could improve without contaminating regression tests.
Accomplishments that I am proud of
The main accomplishment is that Phoenix became part of the product loop, not an after-the-fact dashboard.
The project demonstrates a full thesis-to-audit lifecycle: pasted thesis, Gemini-assisted claim extraction, candidate market-fit classification, weak-proxy detection, rejected-market explanations, Phoenix trace/eval visibility, Phoenix MCP-backed improve path in live mode, deterministic local fallback only for offline reproduction, human verdict, and Ledger MCP lifecycle record.
Beyond the trace-improvement demo, the project now includes a golden-governance loop: live retrievals can be exported into a Phoenix candidate Dataset, reviewed fixture goldens are mirrored into a promoted-golden Dataset, and a Phoenix Experiment runs over market_fit_v1 to compare current policy behavior against expected labels.
The original 10 baseline goldens were replayed through live ADK/Gemini and Phoenix, passing 10/10 with trace URLs and eval annotations. The observed replay is documented in trace audit and linked from the README. The Phoenix value-proof document defines the live improve pass conditions, including inspection_source: phoenix_mcp and fallback_used: false.
What I learned
Harness engineering, not prompt tweaking. The most important shift was realizing that reliability would not come from a better one-shot prompt. It came from the harness around the agent: Phoenix traces, deterministic eval signals, governed datasets, human review, and Phoenix MCP retrieval of failed trace context. The harness is what prompts the next run to behave better.
For this workflow, observability is not backend plumbing. It is part of the product. A trace is useful because it shows exactly where the agent overstated market fit, lets evals attach to that failure, and gives the next run concrete context for correction instead of hiding the change behind vague "agent improvement."
What's next for Market Fit Trace Agent
Next, I would expand Governance 50 into a larger reviewed eval set, add more prediction-market venues, and build a richer Phoenix MCP/Dataset inspector so reviewers can promote failed traces into candidate goldens from the UI. Next, I would expand Governance 50 into a larger reviewed eval set, add more prediction-market venues, and build a richer Phoenix MCP/Dataset inspector so reviewers can promote failed traces into candidate packets from the UI. On the retrieval side, the next scaling step is lazy snapshot filtering so live candidate search remains bounded and replayable.
Built With
- agent-builder
- agents
- arize
- cloud-run
- evals
- fastapi
- gemini
- google-adk
- google-cloud
- mcp
- openinference
- phoenix
- python


Log in or sign up for Devpost to join the conversation.