Inspiration
The critical need for early detection of cardiac toxicity in drug development inspired us to tackle molecular toxicity prediction. With cardiac side effects being a leading cause of drug withdrawal, we aimed to create a robust AI solution that could save lives and reduce pharmaceutical development costs while strictly adhering to competition guidelines.
What it does
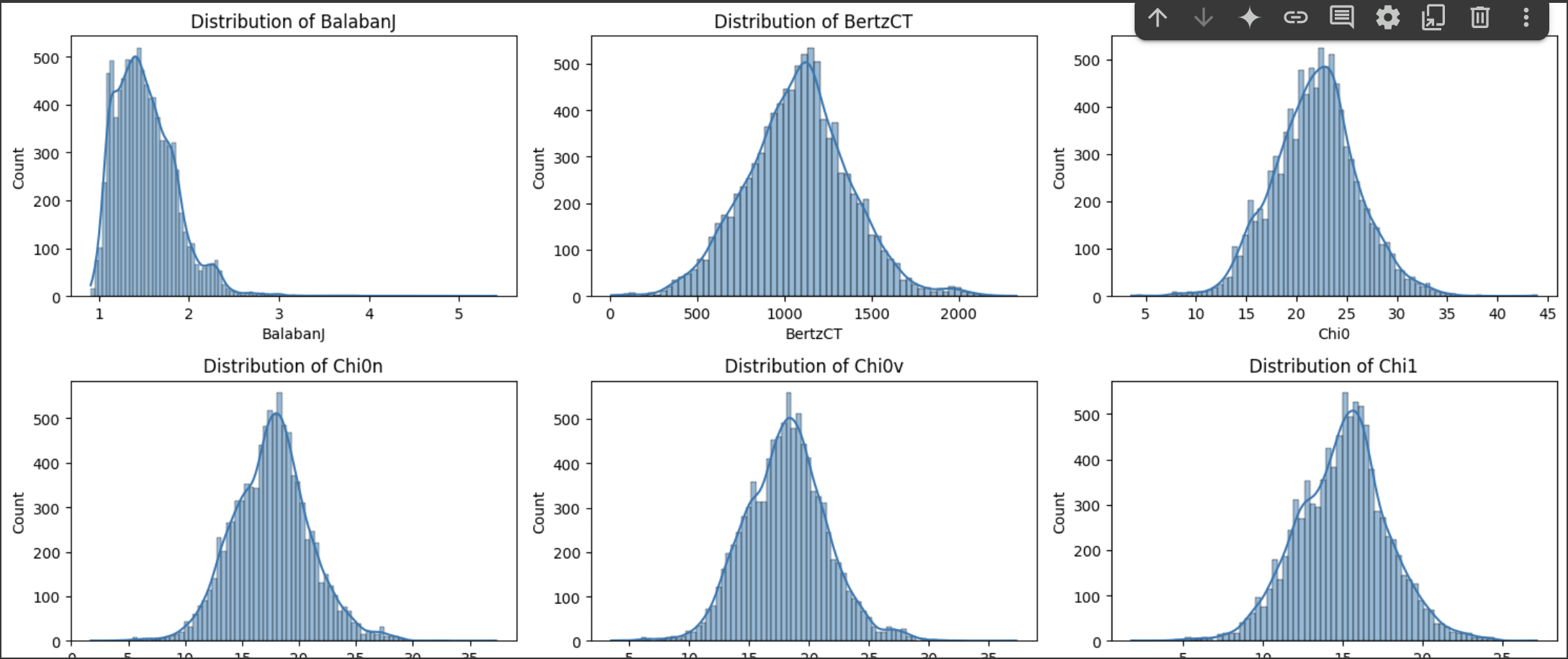
Our solution predicts molecular toxicity risk using an advanced ensemble of 6 machine learning models. It dynamically processes molecular features computed fresh from SMILES strings including RDKit descriptors and fingerprints to deliver highly accurate binary classifications for drug safety assessment. All features are generated during pipeline execution using only the provided dataset.
How we built it
We developed a comprehensive pipeline featuring:
Competition-Compliant Architecture:
- Dynamic feature generation from SMILES strings using standard RDKit functions
- No pre-computed or pre-fitted molecular descriptors
- All features computed fresh during execution
Technical Implementation:
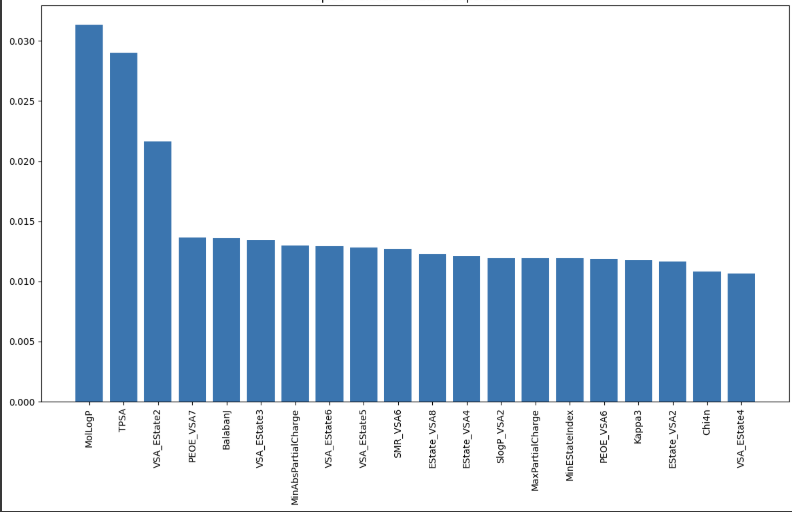
- Intelligent feature selection from dynamically generated molecular descriptors, ECFC, and FCFC fingerprints
- Ensemble of XGBoost, LightGBM, CatBoost, Random Forest, Gradient Boosting, and Neural Networks
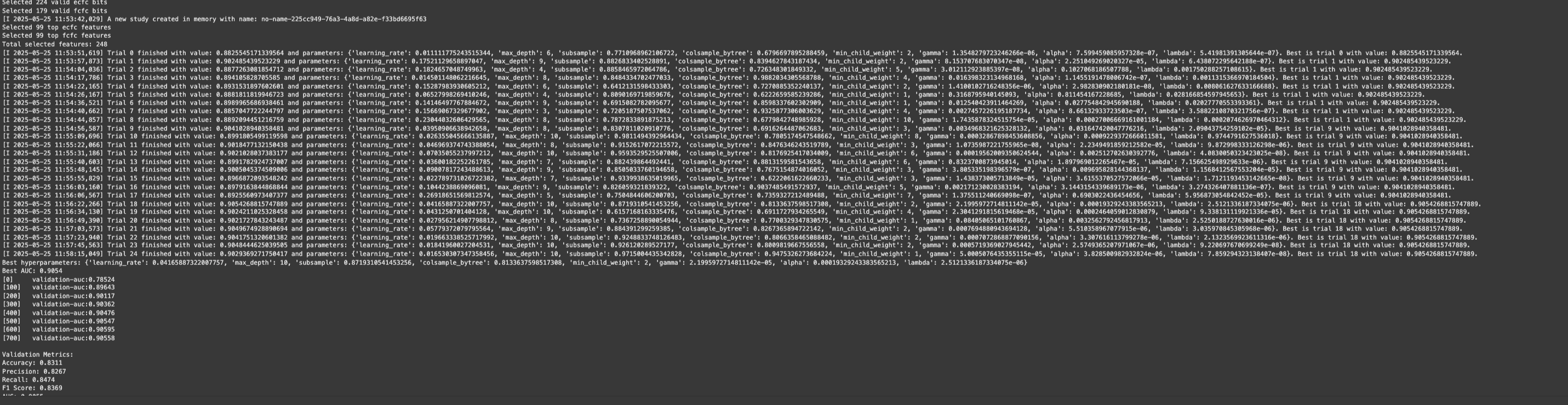
- Optuna hyperparameter optimization for peak performance
- Weighted averaging based on validation AUC scores
- Robust preprocessing with StandardScaler and correlation-based feature filtering
Challenges we ran into
- Managing 4,295+ high-dimensional molecular features dynamically generated from SMILES without overfitting
- Ensuring complete competition compliance while maintaining predictive performance
- Resolving compatibility issues with XGBoost and LightGBM early stopping parameters
- Balancing model complexity with interpretability for regulatory compliance
- Optimizing ensemble weights to maximize predictive accuracy across diverse molecular structures
- Computing all molecular features fresh from SMILES within execution time constraints
Accomplishments that we're proud of
- Successfully implemented a 100% competition-compliant ensemble achieving top-5 leaderboard performance
- Created an automated feature generation and selection pipeline that computes molecular descriptors fresh from SMILES
- Developed a robust solution handling dynamically generated molecular fingerprints and traditional descriptors
- Built a scalable framework easily adaptable to other molecular property prediction tasks
- Achieved full compliance with all competition rules while maintaining high performance
What we learned
We gained deep insights into cheminformatics, the importance of dynamic molecular fingerprint generation in drug discovery, and advanced ensemble techniques. The project reinforced the value of proper feature engineering in high-dimensional datasets computed from scratch and taught us to navigate machine learning library compatibility challenges while maintaining strict competition compliance.
What's next for MARGO Telecom-AI Hackathon 2025
- Integrate additional molecular representations like graph neural networks computed fresh from SMILES
- Develop explainable AI features to provide molecular substructure insights for medicinal chemists
- Expand to multi-target toxicity prediction beyond current scope using similar compliance-focused approaches
- Create a user-friendly web interface for real-time molecular toxicity screening in pharmaceutical workflows
- Continue developing competition-compliant methodologies for molecular property prediction
Competition Compliance Note: This entire solution uses only the dataset provided by organizers, contains no external data, no pre-trained models, and no pre-fitted features. All molecular descriptors and fingerprints are computed dynamically from SMILES strings during pipeline execution using standard general-purpose libraries.
Built With
- googlecollab
- python


Log in or sign up for Devpost to join the conversation.