-
-
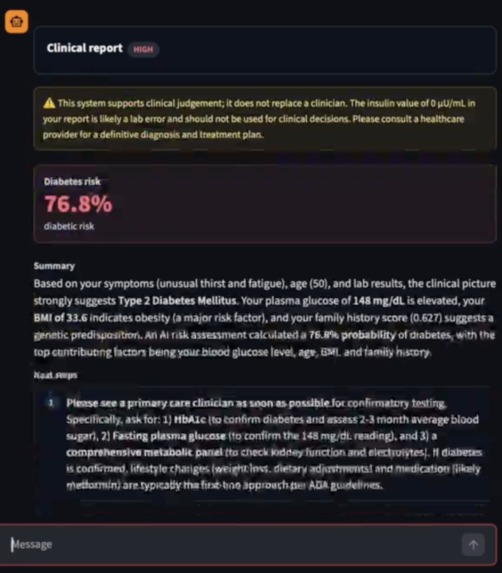
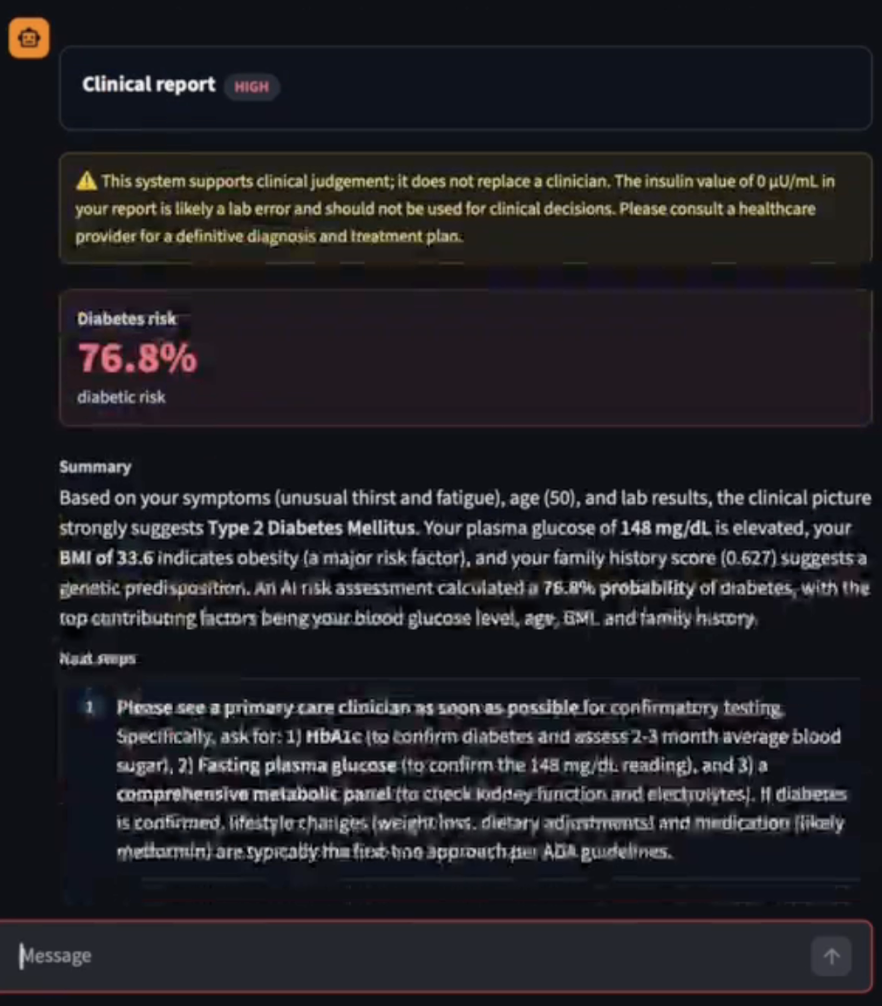
Screenshot of Report
About MARGE (Multi-agent, ML-Reasoning Guidance Engine)
Team: Sehyun Nam, Sunghun Jung, Yoonhyeok Choi, Ryul Hwangbo (College of Computing, Yonsei University)
What Inspired Us
The rapid advancement of Large Language Models (LLMs) has brought incredible convenience, but in the healthcare sector, it has also introduced a dangerous "overreliance trap." We noticed that while LLMs excel at accessibility and processing complex queries, their tendency to hallucinate—fabricating facts, references, and misinterpreting medical guidelines—creates direct pathways to misdiagnosis.
At the same time, traditional Software as a Medical Device (SaMD) solutions, which rely on highly accurate Machine Learning (ML) models, are growing rapidly but remain inaccessible to non-specialists because they lack intuitive interfaces and interpretability.
Our core inspiration came from a pressing global health crisis: with international health funding facing severe cuts and a projected shortage of 6.1 million health workers in Africa by 2030, vulnerable regions (like rural health posts in Niger) are at immense risk. We wanted to build a solution that aligns with UN Sustainable Development Goal 3 (Good Health and Well-being) by creating a tool that safely democratizes clinical-grade SaMDs, allowing non-specialist health workers to provide accurate, life-saving care without falling victim to AI hallucinations.
How We Built Our Project
To bridge the gap between reliable-but-complex ML models and accessible-but-unreliable LLMs, we developed MARGE, a "Best-of-Both-Worlds" framework.
Agentic LLM/ML Loop: Instead of relying on an LLM to make medical predictions, we built an LLM Orchestrator that delegates actual clinical predictions to an array of specialized, clinical-grade ML Agents (e.g., specific tree-based models).
Explicit Grounding & Explainable AI (XAI): When an ML model makes a prediction, it outputs SHAP values. We feed these XAI metrics back to the Medical Expert LLM, which then translates the raw data into reliable, plain-language clinical reasoning for the user.
Agentic Loops: We implemented autonomous loops that allow the system to self-correct, prompt the user for missing data (like vitals or lab results), and navigate complex clinical workflows.
Web-based RAG: To ensure our LLM's outputs are deeply rooted in peer-reviewed science, we integrated Web-based Retrieval-Augmented Generation using authoritative sources like MedlinePlus.
Challenges We Faced
Building a hybrid system that integrates natural language processing with rigid statistical models introduced several practical hurdles:
LLMs Malfunctioning on Tabular Data: We quickly discovered that pure LLMs struggle immensely when tasked with processing raw, tabular clinical data. They frequently misinterpret numerical relationships or hallucinate patterns where none exist. We had to design an architecture that strictly offloads tabular data processing to traditional ML models, preventing the LLM from attempting clinical mathematics.
Translating XAI to Natural Language: Bridging the gap between ML models and the LLM was tricky. Feeding raw SHAP values to an LLM sometimes confused the model, leading to hallucinated explanations of feature importance. We had to carefully structure how the LLM receives these values so it accurately reflects the ML's reasoning without fabricating clinical correlations.
Agentic Loop Stability: Designing the autonomous feedback loop required delicate balancing. We needed the LLM to intelligently prompt health workers for missing critical data (e.g., "Please input the patient's temperature"), but we had to implement strict constraints to prevent the agent from getting trapped in infinite query loops or overwhelming the user with unnecessary questions.
What We Learned
Separation of Concerns is Critical: You cannot trust an LLM to be a diagnostic calculator, but it is an incredible communicator. By strictly separating the prediction (handled by ML) from the reasoning and communication (handled by the LLM), we effectively mitigated the hallucination risk while maintaining ease of use.
XAI is the Perfect Bridge: Explainable AI methods like SHAP aren't just for data scientists—they provide the exact semantic grounding an LLM needs. We learned that using XAI outputs acts as a powerful anchor, preventing the LLM from guessing why a diagnosis was made.
Digital Infrastructure Pragmatism: Designing for the real world means designing for limitations. We learned that the architecture must allow for a local-first approach. For our framework to actually be viable in low- and middle-income countries (LMICs), the system must be able to function securely and reliably on-device.
Built With
- beeai
- featherlessapi
- python
- streamlit
- xgboost





Log in or sign up for Devpost to join the conversation.