Inspiration
The inspiration for Marathon Research Agent came from a fundamental limitation in current LLM interfaces: Chat is not Research. When we ask complex questions—like "Compare the TCO of NVIDIA H200 vs AMD MI300X"—standard chatbots often rush to generate an answer immediately. This leads to superficial summaries, hallucinations, and a lack of nuance.
Human researchers don't work this way; they collect data, analyze patterns, verify facts against multiple sources, and then write. We wanted to build an autonomous agent that mimics this rigorous, multi-step cognitive workflow. By leveraging the new reasoning capabilities of Gemini 3, we moved beyond "generating text" to "generating thought."
What it does
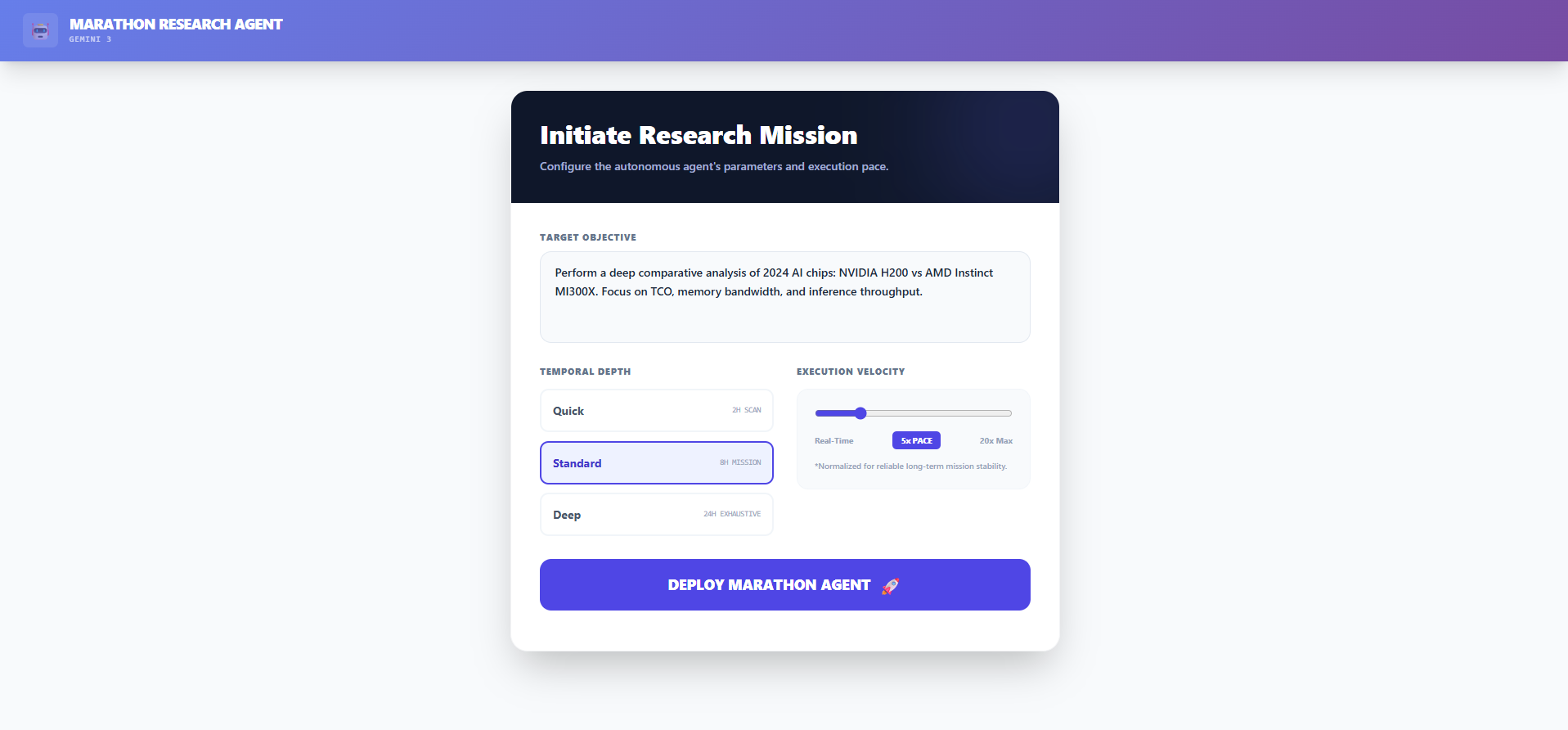
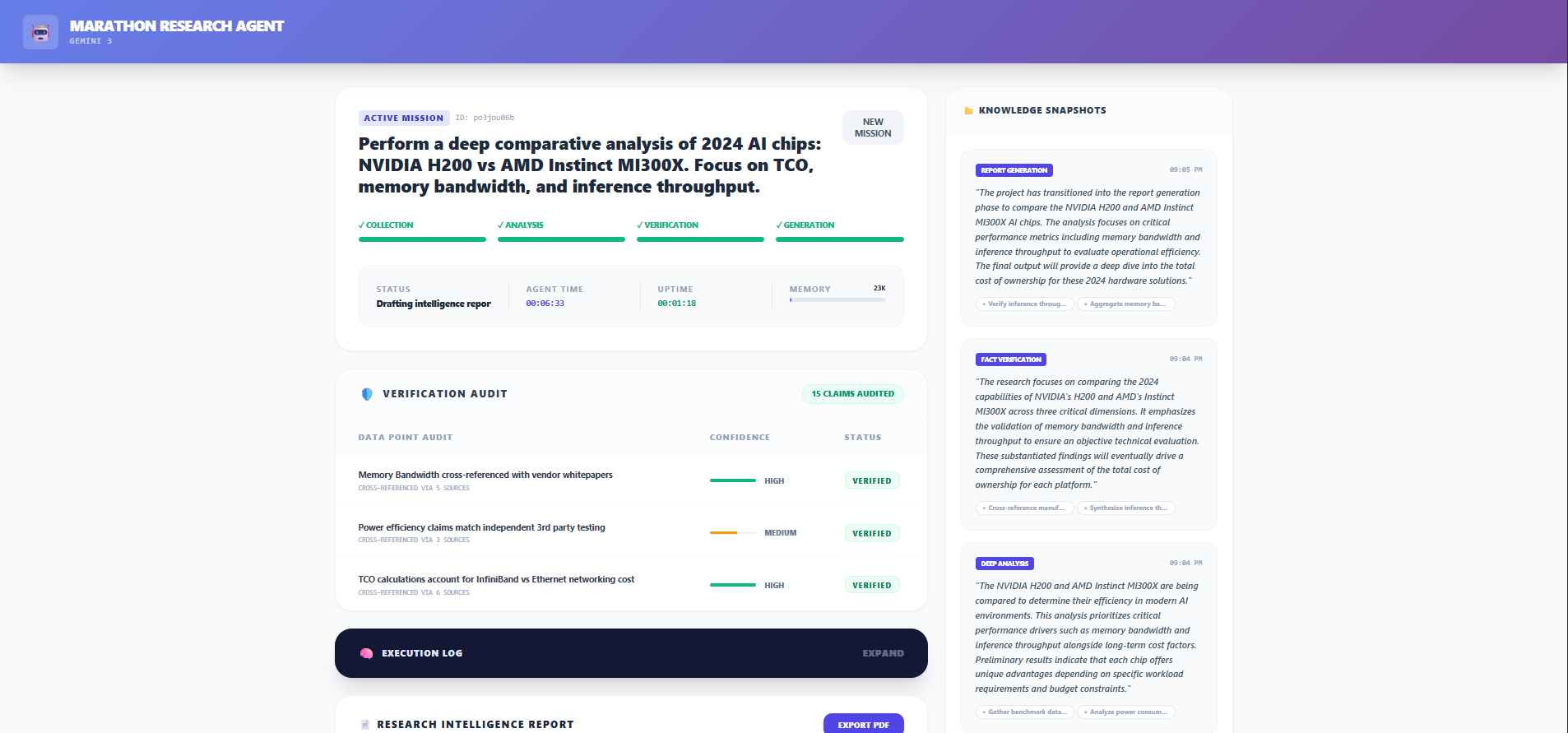
Marathon is an autonomous agent that executes a long-form research "mission" based on a user's prompt. Instead of a single API call, it orchestrates a state machine through four distinct phases:
Data Collection: The agent scans for raw data, utilizing search grounding to aggregate technical specs and vendor whitepapers.
Deep Analysis: Utilizing Gemini 3 Pro's thinkingBudget, the agent performs hierarchical reasoning to find non-obvious correlations and architectural bottlenecks.
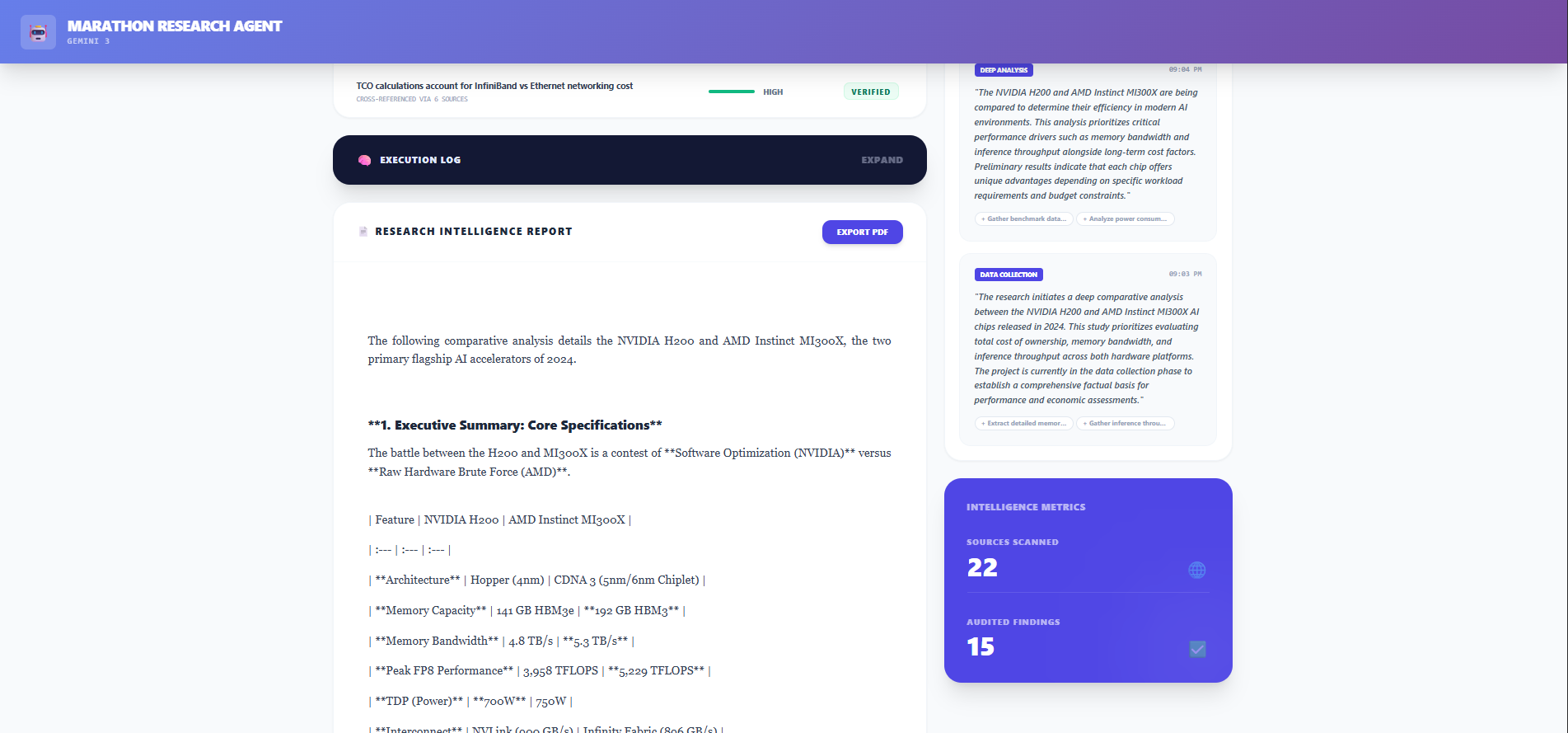
Audit: The agent acts as an adversarial auditor, cross-referencing claims to assign a confidence score.
Reporting: It synthesizes the context into a structured, professional report.
The user watches this happen in real-time via a "Mission Control" dashboard that streams the agent's internal monologue, displays verified claims, and allows for a clean PDF export of the final intelligence report.
How we built it
The project is built on a modern stack focusing on state management and AI integration:
Core Framework: React 19 + TypeScript for a type-safe, robust UI.
AI Engine: We utilized the @google/genai SDK to orchestrate two specific models:
- gemini-3-pro-preview: Used for the Analysis Phase. We allocated a high thinkingBudget (8k-24k tokens) to allow the model to traverse complex logical paths before outputting a result.
- gemini-3-flash-preview: Used for Context Compression and rapid summarization tasks to maintain speed.
State Management: A custom React hook system acts as the central nervous system, managing the transition between phases and handling the asynchronous nature of long-running AI tasks.
PDF Engine: We implemented html2pdf.js with dynamic DOM manipulation to render the React component tree into a paginated, print-ready document.
Challenges we ran into
The Context Window Constraint
Conducting deep research generates massive amounts of text. Simply appending every log and finding to the context window would quickly hit token limits or degrade model performance.
Solution: We implemented a Context Compression Algorithm. After every phase, the agent generates a "Thought Signature"—a compressed vector of the current state—ensuring the model retains the narrative arc without the noise.
Managing Latency vs. UX
Gemini 3 Pro's "Thinking" process yields better results but takes longer. A blank screen destroys user trust.
Solution: We built a real-time "Execution Log" that streams the agent's simulated sub-tasks (e.g., "Correlating FLOPS utilization...", "Modeling memory-wall constraints..."). This provides immediate visual feedback while the API processes the request in the background.
Client-Side PDF Generation
Generating a PDF from a scrollable, dynamic React view was tricky. The output was often cut off or badly formatted.
Solution: We wrote a custom effect hook that temporarily expands the report container's dimensions, injects break-inside-avoid CSS classes to handle pagination gracefully, and then triggers the capture engine.
Accomplishments that we're proud of
The "Agentic" Feel: The application truly feels like you are commanding a digital employee rather than typing into a search box.
Self-Correction: The Verification Phase actually works. Seeing the agent mark a claim as "Uncertain" or "Contradiction" adds a layer of trust that standard LLMs lack.
Resilience: We implemented an exponential backoff strategy for API rate limits, allowing the agent to "cool down" and auto-recover without crashing the mission.
What we learned
Thinking Budgets are Powerful: We learned that simply enabling "Thinking" on Gemini 3 Pro drastically improved the structure of the final report. The model was able to plan the document layout internally before writing a single word.
UI is Part of the AI: The way you present the AI's "thought process" is just as important as the result. Visualizing the "Knowledge Snapshots" and "Verification Audit" helps users understand why the AI reached its conclusion.
What's next for Marathon Research Agent
Multi-Agent Collaboration: We plan to split the monolithic agent into three distinct personas: a Researcher, a Critic (who aggressively challenges findings), and a Writer, all conversing in a loop.
Persistent Memory: Integrating a vector database to allow the agent to recall findings from previous missions (e.g., "Compare this result to the analysis we did last week").
Live Web Browsing: Replacing the simulated search grounding with live, real-time web scraping for up-to-the-minute news analysis.
Built With
- context-compression-algorithm
- custom-react-hooks
- exponentialbackoffstrategy
- gemini-3-flash
- gemini-3-pro
- google/genai-sdk
- html2pdf.js
- react-19
- typescript


Log in or sign up for Devpost to join the conversation.