
MARA: Context-Aware AI Retail Agent
About the Project
Inspiration
Modern e-commerce platforms rely heavily on recommendation algorithms designed to maximize engagement and sales. While these systems excel at identifying products similar to a user’s recent interactions, they often fail to respect persistent user constraints such as budget, materials, or long-term aesthetic preferences.
This leads to a phenomenon we call constraint drift. For example, a user may initially search for a desk lamp under $120, but after briefly exploring premium items, recommendation systems gradually start surfacing products far above the original budget. This happens because most recommendation pipelines prioritize semantic similarity or recent user interactions over invariant constraints.
From a user experience perspective, this creates frustration and erodes trust in AI-driven shopping assistants.
We were inspired to address this gap by asking a fundamental question:
What if an AI shopping assistant could remember your preferences like a human, while never forgetting your hard constraints?
This idea led to the creation of MARA (Memory-Aware Retail Agent) - an AI system designed to balance long-term preferences, recent interactions, and strict constraints within a unified memory architecture.
What It Does
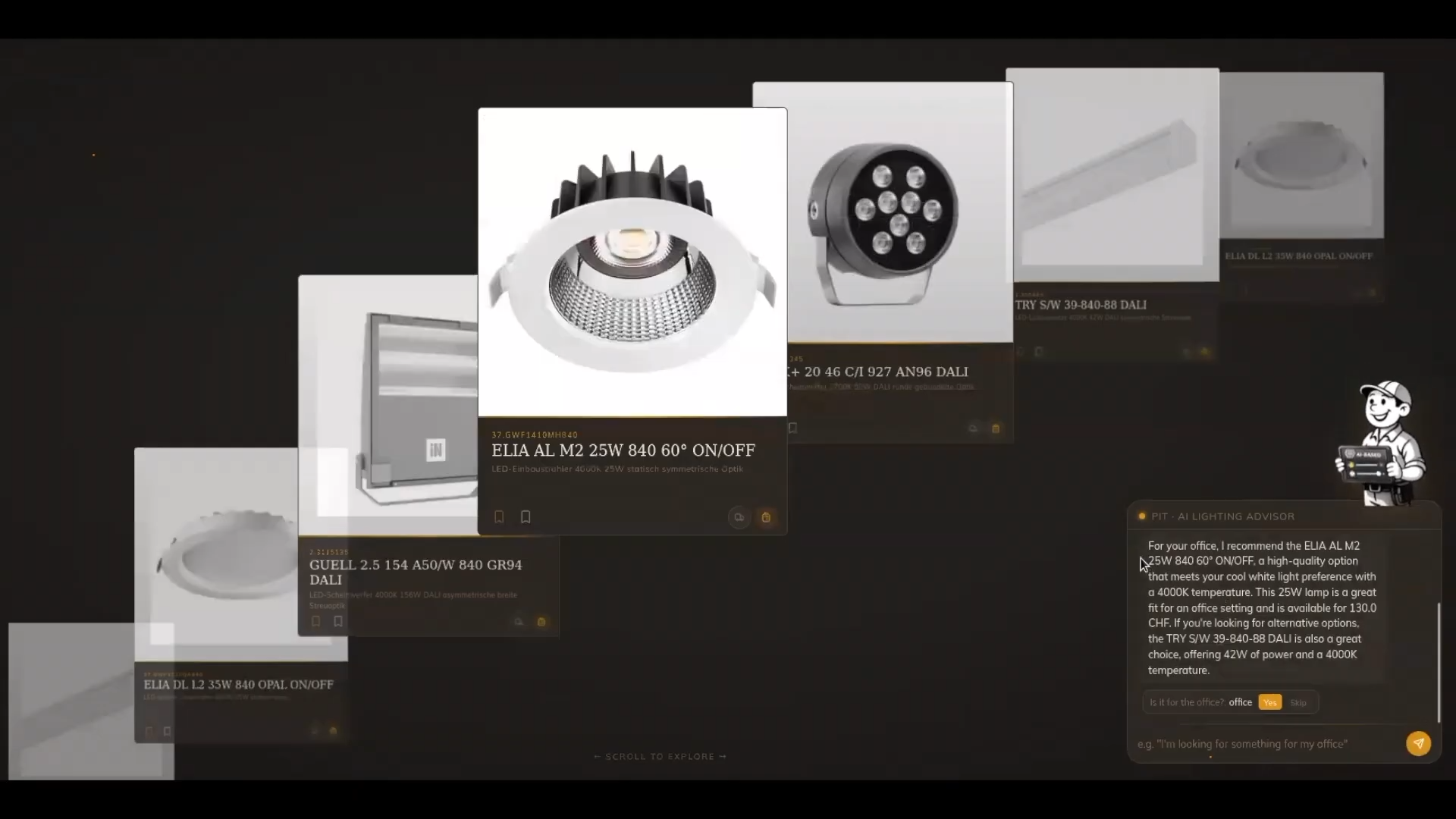
MARA is an end-to-end conversational retail AI agent designed to provide highly personalized product recommendations while respecting strict user constraints.
The current implementation focuses on personalized lamp recommendations, leveraging a real catalog of over 5,000 products. Users interact with MARA through a natural language chat interface where they can specify preferences such as:
- budget limits
- design styles
- materials
- lighting characteristics
- recent interests
The key innovation behind MARA is its three-layer cognitive memory architecture, inspired by human memory systems.
MARA 3-Layer Memory Architecture
Instead of treating all user interactions equally, MARA organizes user context into three distinct memory layers, each with its own decay dynamics.
1. Structural Memory (Hard Constraints)
Structural memory stores non-negotiable constraints such as:
- maximum budget
- material restrictions
- size limitations
- safety or environmental requirements
These constraints are modeled with an extremely slow decay rate:
$$ \lambda_{structural} = 0.01 $$
This ensures that hard constraints persist throughout the entire interaction session and are strictly enforced during retrieval.
2. Semantic Memory (Long-Term Preferences)
Semantic memory captures general user tastes and stylistic preferences, such as:
- minimalist design
- warm lighting
- Scandinavian aesthetics
- wooden finishes
These preferences evolve slowly and are assigned a moderate decay factor:
$$ \lambda_{semantic} = 0.1 $$
This allows the system to maintain continuity in recommendations while still adapting to evolving user interests.
3. Episodic Memory (Recent Interactions)
Episodic memory represents short-term browsing context, such as:
- recently viewed products
- temporary exploration of premium items
- short conversational threads
To prevent users from becoming trapped in narrow recommendation loops, episodic memories decay quickly:
$$ \lambda_{episodic} = 0.3 $$
This ensures that temporary browsing behavior does not permanently distort the recommendation space.
Memory-Aware Retrieval Mechanism
When a user submits a query, MARA performs the following pipeline:
- The user query is embedded into a 1024-dimensional vector space.
- User memories from all layers are retrieved and decayed using exponential weighting.
- Candidate products are retrieved from the vector database.
- Structural constraints are strictly enforced.
- A weighted similarity score ranks the results.
The ranking function is defined as:
$$ Score_{final} = Similarity(q, p) \times W_{structural} \times e^{-\lambda t} $$
Where:
- $Similarity(q,p)$ is the cosine similarity between query and product vectors
- $W_{structural}$ is a constraint enforcement weight
- $\lambda$ is the decay rate of the corresponding memory layer
- $t$ represents the time since the memory was created
This architecture ensures that preferences evolve naturally while constraints remain immutable.
How We Built It
We designed MARA as a modular, full-stack AI system composed of multiple specialized services.
Frontend Lovable
The user interface is built using:
- Next.js
- React
- Tailwind CSS
The frontend provides:
- a conversational chat interface
- constraint chips for persistent filters
- dynamic product recommendation cards
- real-time responses from the AI agent
The interface is optimized to make constraint awareness visually transparent to the user.
Backend
The backend is implemented using:
- Python
- FastAPI
FastAPI was chosen due to its:
- high performance
- asynchronous request handling
- strong compatibility with AI pipelines
The backend orchestrates the entire agent workflow, including:
- query embedding
- vector retrieval
- memory decay calculations
- LLM reasoning
- product metadata retrieval
The service is deployed on Render for scalable hosting.
Vector Search & Memory Layer
To support large-scale semantic search, we used Qdrant Cloud as the vector database.
The system stores two primary collections:
- Product embeddings (5,171 items)
- User memory embeddings
Embeddings were generated using HuggingFace BGE models, producing:
$$ \mathbb{R}^{1024} $$
dimensional vectors for both products and user queries.
This shared vector space allows MARA to align user intent, product descriptions, and memory context in a unified retrieval process.
LLM Reasoning Layer
To generate natural conversational responses, we integrated Groq's ultra-fast inference platform.
The LLM layer uses:
- Mistral-7B
- Llama models
These models are responsible for:
- contextualizing retrieved products
- explaining recommendations
- generating natural dialogue responses
Groq’s inference speed significantly reduces response latency, making the system feel interactive and responsive.
Data Layer
Structured product information such as:
- prices
- categories
- product specifications
- images
- metadata
is stored in Supabase, which provides a reliable relational database backend.
This separation between vector search and structured relational data allows the system to combine semantic search with precise filtering.
Challenges We Faced
One of the most technically challenging aspects of MARA was building the Memory Decay Engine.
Traditional Retrieval-Augmented Generation (RAG) pipelines typically rely only on:
- cosine similarity
- keyword filters
- static embeddings
However, our system required dynamic memory weighting, which meant we had to design a custom retrieval function that could incorporate:
- similarity scores
- constraint weights
- temporal decay
Another challenge was ensuring that hard constraints were never violated. Integrating strict filtering with probabilistic vector search required extensive testing to prevent edge cases where invalid products could leak into the recommendation pool.
Finally, we had to optimize the latency of a complex multi-service pipeline:
$$ Frontend \rightarrow FastAPI \rightarrow Embedding Model \rightarrow Qdrant \rightarrow Groq LLM \rightarrow Supabase \rightarrow Frontend $$
Ensuring that this pipeline remained fast and responsive was critical for maintaining a seamless conversational experience.
Accomplishments We Are Proud Of
Our biggest accomplishment is demonstrating that AI retail agents can be both intelligent and constraint-safe.
Unlike typical recommendation systems, MARA guarantees that once a user defines a budget or restriction, the system will never violate it, regardless of later browsing behavior.
We also successfully deployed a fully functioning end-to-end application where:
- a real frontend interface
- a custom AI memory architecture
- vector databases
- open-source LLMs
all operate together in a cohesive production pipeline.
What We Learned
Through building MARA, we gained valuable experience in:
- vector mathematics and embedding systems
- designing dynamic ranking functions
- building memory-aware AI architectures
- integrating multiple AI infrastructure services
- constructing scalable microservice pipelines
We also learned how crucial constraint-aware prompting is when working with open-source LLMs, especially in production environments.
What’s Next for MARA
While MARA currently focuses on lamp recommendations, the architecture is designed to be domain-agnostic.
Our next goals include:
Multi-Domain Expansion
Extending the MARA architecture to additional retail categories such as:
- fashion
- consumer electronics
- furniture
- real estate
Multimodal Search
We plan to integrate vision models that allow users to upload images of their environment.
For example, a user could upload a photo of their living room, and the system would automatically extract stylistic features to update the semantic memory layer.
Retail Integrations
Finally, we aim to develop a Shopify plugin that enables any online store to integrate MARA directly into their storefront.
This would allow retailers to deploy memory-safe AI shopping assistants without needing to build complex AI infrastructure themselves.
Implementation
To see this implemented in an online lighting store, visit braight.ch.






Log in or sign up for Devpost to join the conversation.