-
Object Detection & Localization
-
Image Storage In Google Buckets
-
Image Storage In Google Buckets
-

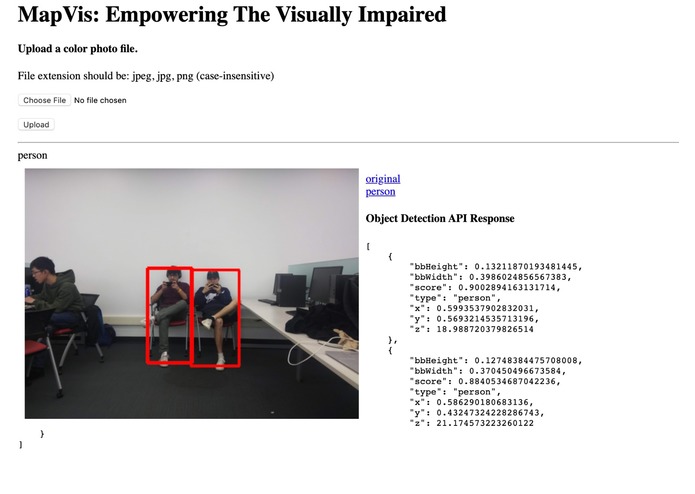
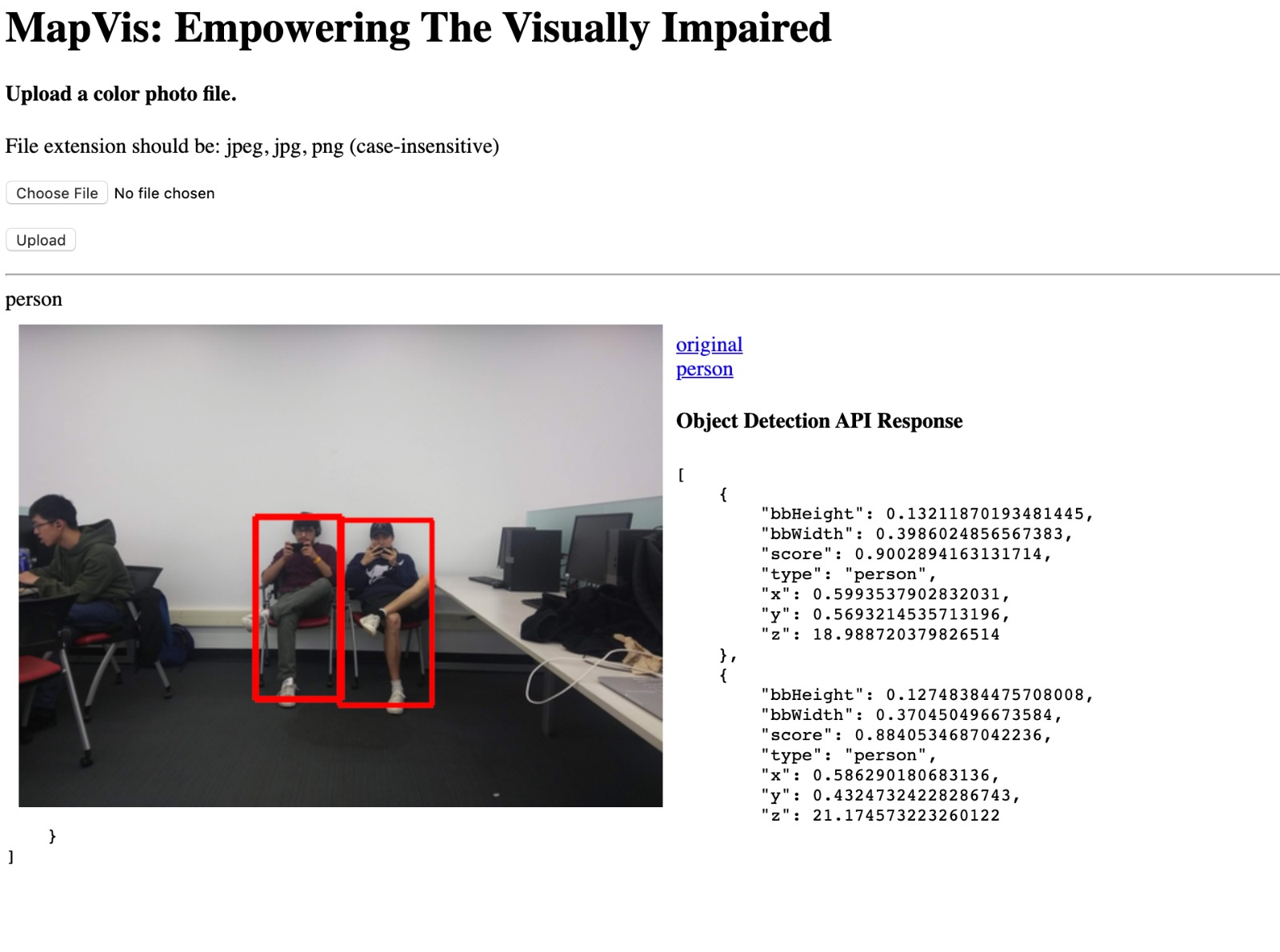
Object detection
-

Generation of bounding box on the targets
-

Audio source generation according to an object's distance



Inspiration
Any technology is good only if it solves problems. A common problem which we see around is loss of vision. Approximately 250 million people in the world suffer from severe vision impairment. Thus, we wanted to build an app to help the visually impaired.
Given the advancements in Computer Vision and Augmented Reality/Mixed Reality, we are in a unique position of leveraging the interface in these technologies for helping people with disabilities, in this case, of a visual nature, in order to improve their daily life.
Visually impaired people often struggle to do day to day tasks like crossing a road, entering a house, moving between places, etc. This also makes them vulnerable to numerous obstacles around. What if we could tell them that they are moving towards an obstacle? What if we could tell them that a person is running towards them? What if we could provide them an agent like J.A.R.V.I.S?
Enter MapVis.
What it does
MapVis (Mapping Vision) is an AI-powered app that makes blind people more aware of their surroundings. It warns visually impaired of potential obstacles by mapping the motion of objects in the surrounding to 3D audio signals. Users
- Connect their headphone to the smartphone
- Open the MapVis app installed on the smartphone
- Point the camera in the direction they are moving
- Listens to audio sounds provided by MapVis and move accordingly
The audio sounds warn users if they are too close to an obstacle. Users can accordingly adjust their position. An important thing to note is that speaking something like "A car at the distance of 5m in the left" will take a lot of time. As the user or the obstacle is continuously moving, they may collide by the time MapVis finishes speaking such long sentences. Thus we map these long descriptions to specific audio sounds.
How we built it
We divided the work into 2 teams: AI Vision - Udbhav and Mitesh Audio Mapping - Jake and Prabuddha
We created a python flask web app to expose Google Cloud's Object Detection model as an API for detecting and localizing images. We downloaded and set up Monodepth2 pre-trained model to a calculative relative depth between objects in an image. We stored the images as blobs on Google Buckets. This provides us the ability to run insights on the images.
We developed a mobile app in Unity to capture a video of it's surrounding, parse it into frames and send it to the service. The service returns bounding boxes and object types. The mobile app then maps the bounding box and object types(say human, car, etc) to a specific audio sound in 3D space. We used Unity for the task of generating the aural soundscape.
Secret Sauce: Any moving object in the surrounding has 3 attributes - Object Type, Distance, Direction. We map each combination of these triplets to a specific sound. The person hears a different sound if another person is coming towards him and a different sound if a tennis ball is moving towards it.
Challenges we ran into
We had an ambitious idea of improving the lives of visually impaired. Thus we had to play with a lot of different technologies, many of them(Object Distance and depth detection, Audio Mapping, etc) still in their nascent stage. Thus we had to read a lot of research papers to understand and use ML models.
Calculating the distance of an object over time is challenging. To model this, we came up with a heuristic that object size in the image will increase over continuous frames and used the area of the bounded box as a distance measure.
For cases in which multiple objects are moving, we also needed to differentiate between the relative depth of the objects in an image. This turned out to be challenging as well as there's no directly available API. We downloaded and set up multiple different ML models before finding the correct one.
Unity's libraries have some issues with memory management, especially with the limited resources on Android devices. This resulted in performance issues beyond our control, which we mitigated to the extent that was possible.
Due to latency issues, we are only handling 1 frame per second. For faster processing, we had to reduce the image size before sending it to the server.
Our biggest challenge was modeling audio signals in Unity. The sound produced by MapVis should be coherent and not confuse users. As the object detection algorithm sometimes does not detect objects, the sound signals are skipped.
Accomplishments that we're proud of
MapVis can successfully warn users if a single obstacle is moving towards the user or vice versa. User can also feel the direction of object motion through the sound. This is a first step towards a great tool for enabling people with visual disabilities to 'view' the environment around.
What we learned
- How to run and deploy pre-trained ML models on Google Cloud
- Using Google Cloud Buckets to store image data
- Using Unity to create an app
- How to generate audio signals through Unity, and map the audio to specific points in 3D space
- Experience with Virtual Reality
We also learned C# which was fairly new to us.
What's next for Mapping Vision
One thing we didn't build was how to train users to understand the audio signals. We need to develop an audio assistant to help users in learning the sound mappings before using the app.
Given the limits of time that we had, we were able to successfully able to prototype aurally mapping moving human beings in the user's vicinity. We aim to extend this a suite of use cases, wherein, a visually impaired person would be able to map multiple stationary or moving obstacles in his/her vicinity, all encoded in different frequencies/tones. This can be leveraged for object evasion, or searching for objects/other human beings. In a unique sense, it would allow visually impaired people to visualize the environment around.
We envision MapVis to evolve into a suite of applications like Google Lens. Visually Impaired people should be able to point the app at different objects and gets its name. They should be able to rotate the smartphone and perform an audio search. The app alarms once it sees an object, thus helping the user to go and grab that object.
We are yet to conduct a comprehensive survey into the specifics of how to most optimally map sounds in the environment, but we are optimistic about the potential results.
It will also be helpful to mix audio tones and full sentences wherever possible so that users can listen instructions in full sentences whenever they are confused.
Built With
- c#
- flask
- google-cloud
- google-cloud-object-detection
- javascript
- mono-framework
- python
- unity






Log in or sign up for Devpost to join the conversation.