-
Landing page of website.
-
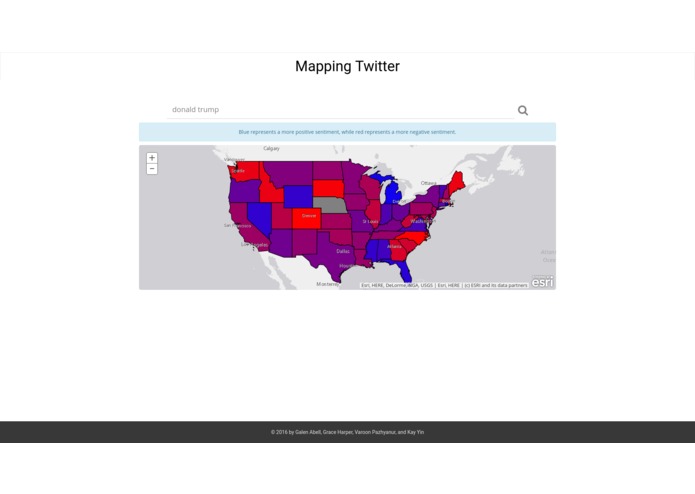
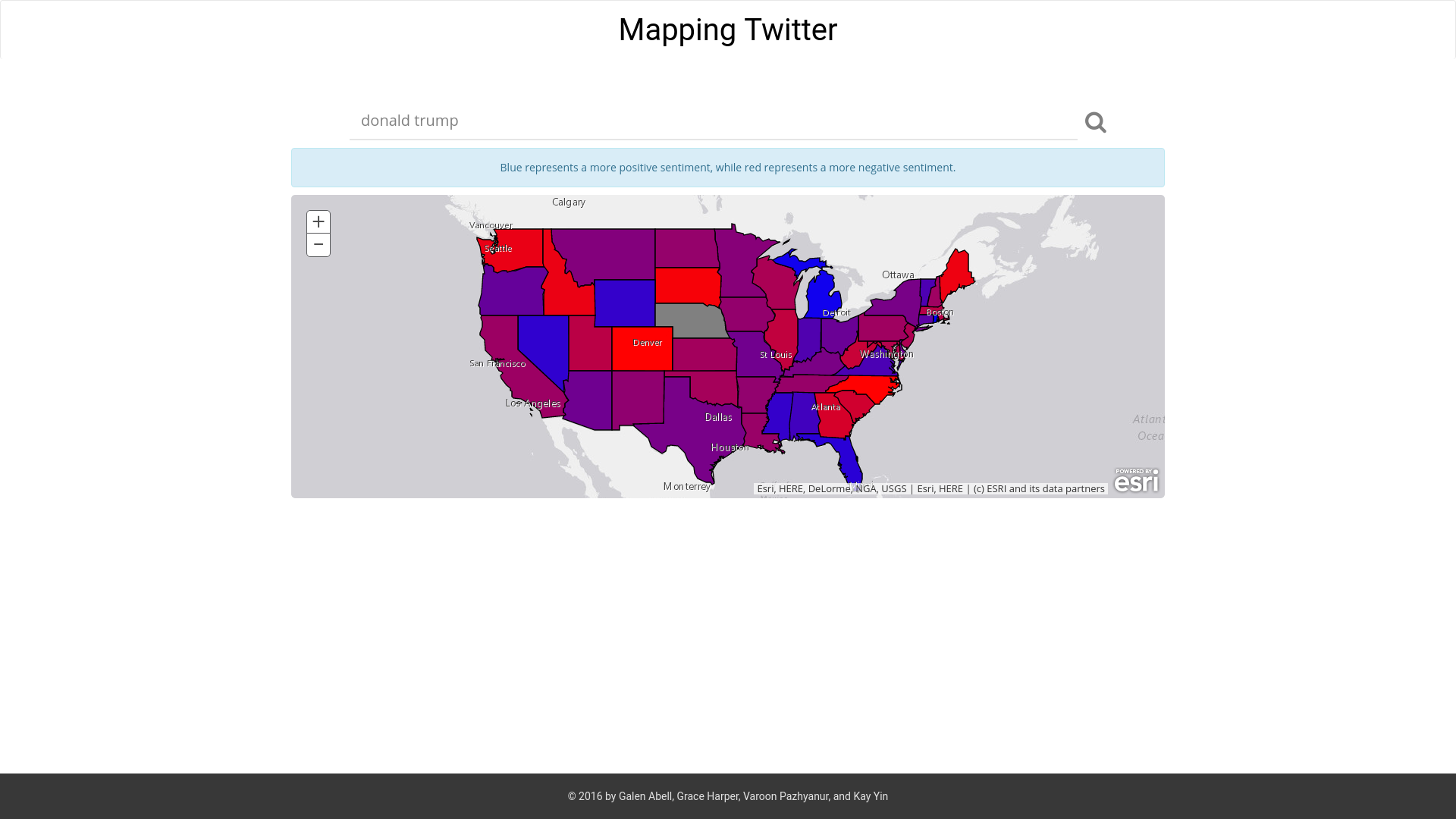
Example of ESRI API for coloring map based on sentiment from tweets.
-
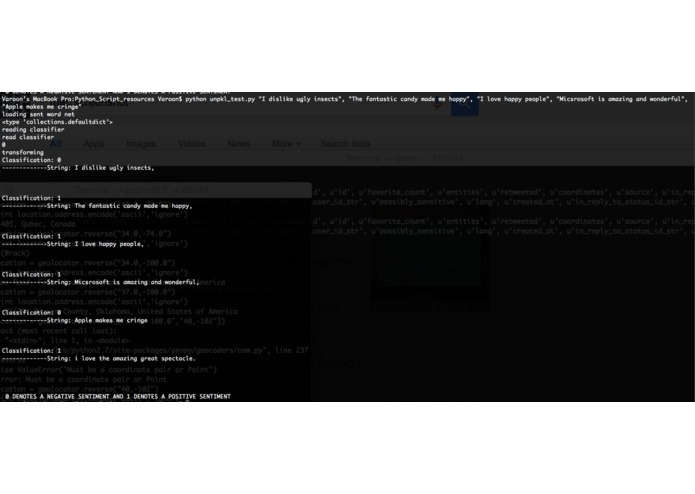
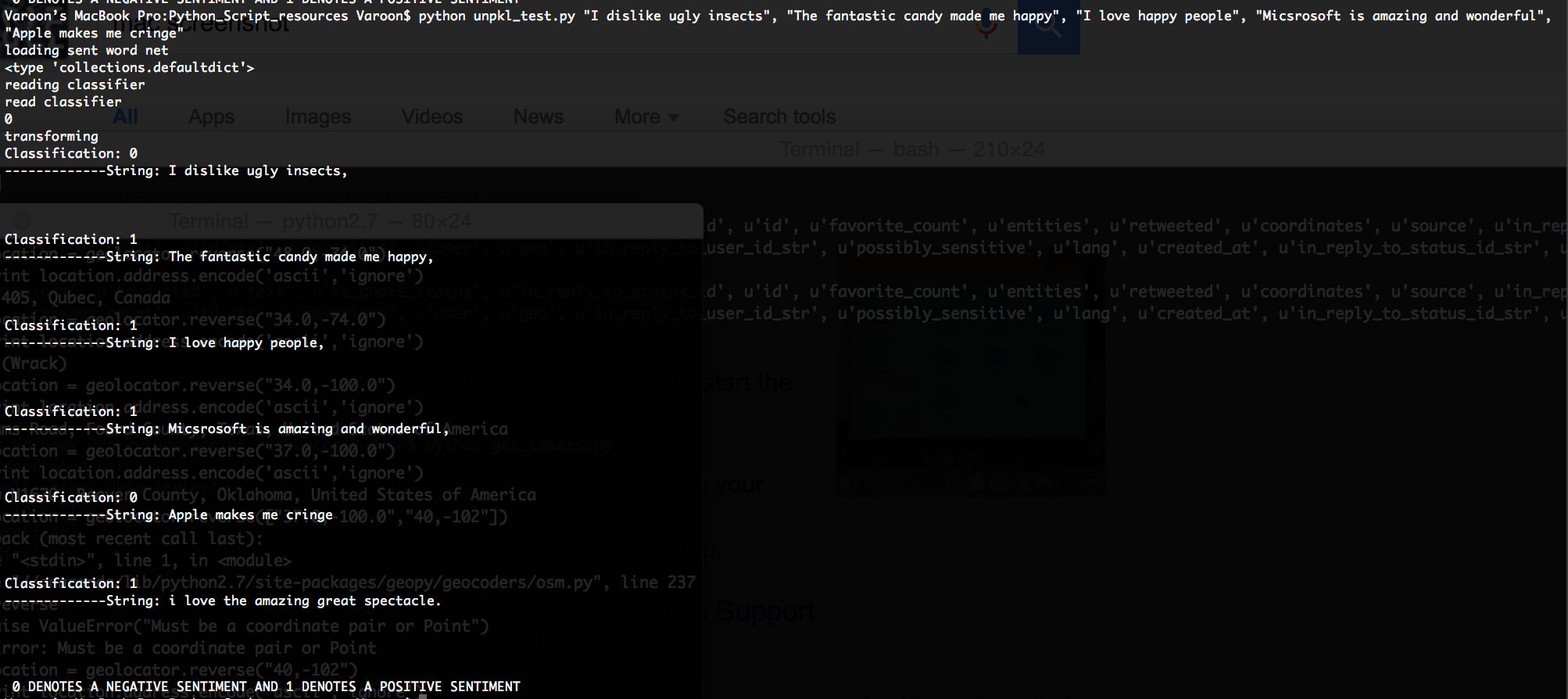
Examples of tweet classification.
Inspiration
We wanted to learn more about machine learning in the context of noisy Twitter datasets and to draw insights that are very sought after by companies and politicians, many of whom invest great amounts of money into learning how they are viewed by the public.
What it does
The program trains a Multinomial Naive Bayes classifier with Laplace smoothing to classify tweets as "positive," "negative," or "neutral." It uses two different feature vectors: one for linguistic data (such as number of verbs, question marks, adjectives, etc.) and another "bag of words" vectorizer. After training on a dataset of 1.5M tweets, it can correctly classify tweets with 86.7% accuracy! The user can enter any topic and a Python script will mine the tweets, classify them, and plot the data with the ESRI API.
How we built it
This uses Python machine learning and natural language processing libraries, along with the Twitter and ESRI API's.
Challenges we ran into
This was a difficult project partly because of the technical machine leraning elements, such as joining vectorizers, pickling the trained model to avoid retraining, and experimenting with different parameters. It was also difficult to integrate the components of the ESRI API the classified tweets.
What's next for Mapping Twitter Sentiment
We can improve the speed by investing more into preprocessing tweets and methods for dimensionality reduction of the trained model. We can also mine bigger datasets from Twitter, as the API limits us to 180 tweets every 15 minutes.

Log in or sign up for Devpost to join the conversation.