-
Ignorance of GBIF data on European Amphibians summarized per ecoregion
-
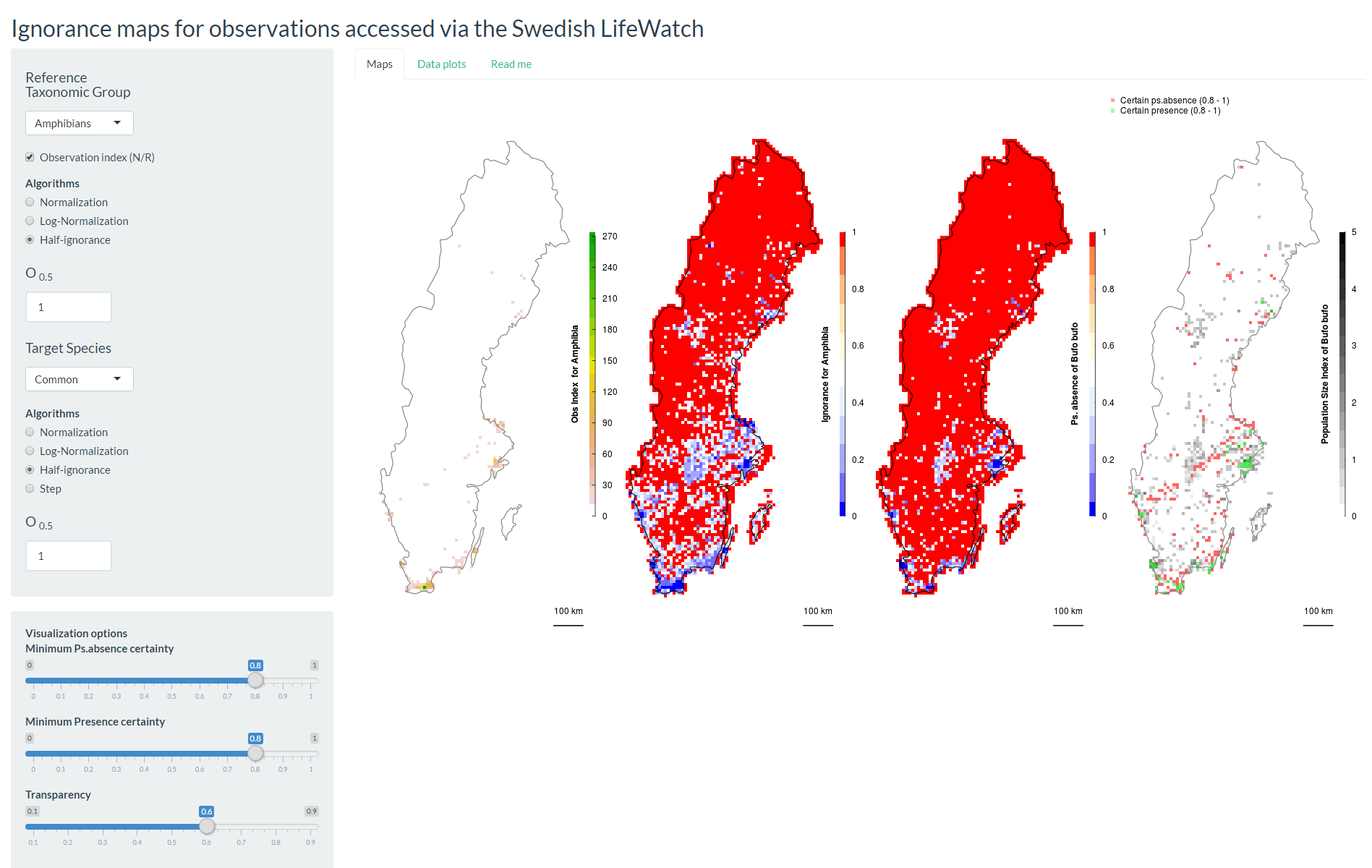
Screenshot of SLWapp
-
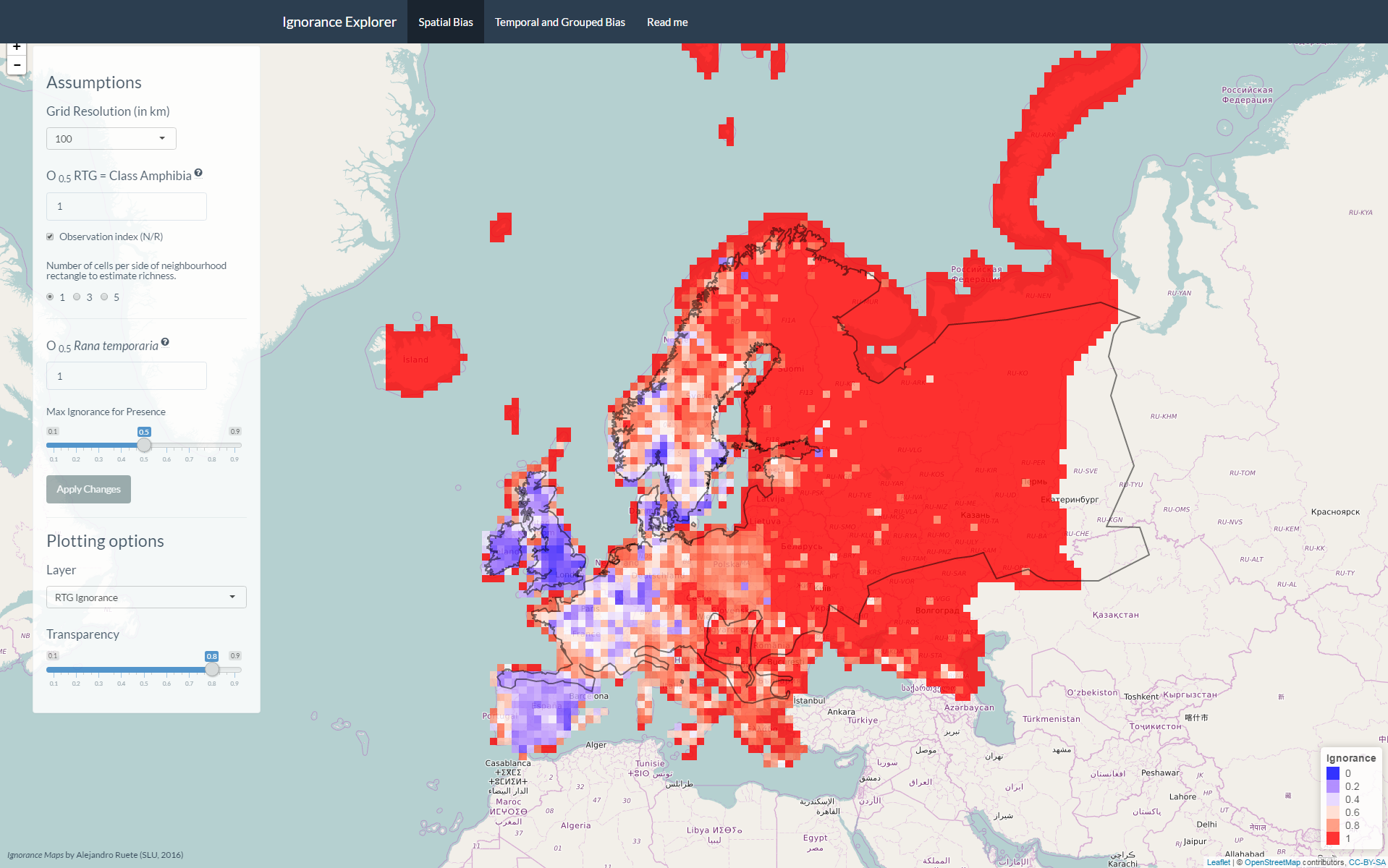
Screenshot of GBIFapp 1st tab
-
Screenshot of GBIFapp 2nd tab


Entry Details
Team members:
Alejandro Ruete PhD (Swedish University of Agricultural Sciences, Uppsala, Sweden) email: aleruete@gmail.com
Technical specification
Platform: ANY
Programming language: ANY. Examples provided as HTML applications programmed in R via the package shiny.
Operational system: ANY
Content
This entry consists of:
- a description of the algorithm to generate Ignorance Scores based on Ruete (2015), and potential applications.
- two HTML applications hosted in Shinyapps.io with explanations and examples on the capabilities and limitations of the Ignorance Scores:
- a tutorial on how to process primary biodiversity data in R to produce your own ignorance maps (mainly based on other excellent tutorials).
All files are available in this project's GitHub repository.
Audience
The approach here presented is meant for managers and users of primary biodiversity data to identify gaps, to assess the spatial and temporal bias inherent to the data, as well as to evaluate the relative gain in knowledge added from new observations. The potential of this tool lies in the simplicity of its algorithm and the few assumptions required, giving the user the freedom to tailor analyses to their specific needs. Any infrastructure for biodiversity information can implement this approach to offer a quick visual quality report. Quantifying the sampling effort of the observation also allows users to incorporate uncertainty into analyses of species' richness and distributions, and to identify areas were unreliable results are expected.
The simple visualization and comparison of the Ignorance Scores across dimensions can aid:
- GBIF and other data providers to set priorities on data mobilization for areas of particular interest.
- (Voluntary) observers to identify undersampled areas to be targeted on their next campaign or excursion (e.g. implementation in smartphone apps).
- Data users to evaluate the fitness-for-use of the data to the intended use. Clearer information about the data availability (and gaps) will increase the trust of the users on the database.
Ignorance scores can also help to handle and correct the bias in the data (see Potential uses), ultimately increasing the usability of the data allowing:
- Public environmental agencies to cost-efficiently monitor ecosystems or conduct land-use prioritization.
- Consultancy companies to speed up and reduce the cost of their analyses by confidently using already available data.
- Researchers to explore a wide spectrum of new questions only possible given the large extent and resolution that is provided by this database.
Objective
I present an approach to quantify, explore and compare the lack of data (Ignorance) in biodiversity databases, like GBIF. The aim is to provide ignorance scores and maps that are easily comparable and scalable across dimensions, to report the spatial and temporal distribution of sampling effort (or lack of it). Ignorance maps will serve to properly inform users of the bias inherent to the data and to provide them with tools to properly analyse the data. Simplicity is crucial for web-based implementations on e-infrastructures for biodiversity information. Therefore, this approach expresses ignorance solely based on raw presence-only data (absences are optional but not required) summarized per grid cells or pixels. For the same reason, this approach relies on as few assumptions as possible. The aim is not to include any covariates or correlations and to avoid prediction, estimation and interpolation methods. The core algorithm is then thought to be fast enough to be implemented in web-based tools and Application Programming Interfaces (APIs). However, it can also be used off-line in the researcher's prefered analysis environment. This project is in line with the need identified by Rocchini et al. (2011) and will provide quality control tools for protocols for biodiversity analysis such as the one proposed by Hortal et al. (2007).
Dimensions of the gaps considered
The algorithm behind the Ignorance Score is designed for comparison of bias and gaps in primary biodiversity data across taxonomy, time and space:
1.Taxonomy: applies to any species groups a, but has also applications at the species level.
2.Time: can be used to aggregate or dissect bias over time.
3.Space: compares per pixel or between summaries of irregular polygons, and can be suited to different resolutions.
a: as reference taxonomic groups, defined below.
Description
"The greatest enemy of knowledge is not ignorance; it is the illusion of knowledge."
Daniel J. Boorstin
Biodiversity databases make temporally and spatially extensive primary biodiversity data (i.e. species observations) available to a wide range of users. However, because of the intrinsic nature of most of the observations (e.g. opportunistic or non-systematic and presence-only), biodiversity datasets have considerable limitations including: sampling bias in favour of recorder distribution, lack of assessment of sampling effort, and lack of coverage of the distribution of all organisms Suarez and Tsutsui (2004). The aim of this approach is to provide a measure of the bias and gaps in sampling effort that is easily comparable across dimensions and easily scalable (Ruete 2015). This approach represents the data into a scale 0 to 1 (0 being a theoretical absolute credibility in the data and 1 being absolute ignorance).
The rationale is based on the assumption that species groups share similar bias. Observations are reported by people with varied field skills and accuracy. However, observers are assumed to be fond of or specialist on one or more taxonomic groups (e.g. families, orders or even classes), rather than on individual species. Since it is likely that an entire group of species observed by similar methods (henceforth, a reference taxonomic group or RTG) will share similar bias (Phillips et al. 2009), it is appropriate to use species' groups as a surrogate for sampling effort (Phillips et al. 2009, Ponder et al. 2001). Therefore, it is straightforward to assume that the lack of reports of any species from the RTG e.g. birds at a particular location is likely due to a lack of ornithologists on that specific location, rather than to the total absence of birds. The inverse logic also holds true. That is, the larger the number of observations of species from the RTG in a grid cell, the more likely it is that the lack of reports of a particular species reflects a true absence of a focal species from the grid cell.
There are some considerations to take into account before describing the algorithms. First, the RTG should only include species that are assumed to be sampled with the same methodology, to keep the sampling bias consistent (Ponder et al. 2001). For example, a RTG should not include all species in the Order Lepidoptera because butterflies sensu stricto (superfamily Papilionoidea) are sampled in very different ways than all other species of Lepidoptera (mainly moths). Also, extreme biases in sampling effort among species within the RTG can occur and has to be taken into account (see next section Algorithm overview). Second, it has been pointed out that in case that ignorance maps are to be used to correct the sampling bias of background information (for software packages like MaxEnt), the target species should be removed from the RTG if it is known that the species has been heavily sampled at a particular location but has few records in the vicinity (Ponder et al. 2001). In the case of allopatric species, however, removing the target species will leave "holes" in the ignorance maps (Ponder et al. 2001). Finally, in the case of ignorance maps, it is preferred to calculate ignorance scores including observations over long time periods to reduce temporal variability in sampling effort. Of course, this is only valid as long as there is no significant change to the underlying habitat that holds the species, and time itself is not a covariate to be included in the analysis of the data.
Algorithm overview
The number of observations Ni per grid cell i is the most direct measure of sampling effort when species richness is even across the study area and all species are sampled evenly depending on their probability of detection. However, most often that is not the case. Richness varies across space (and time for that matter) and species may not be evenly detected (or reported). The sampling behaviour that characterises observers differs among reference taxonomic groups. For some taxa like vascular plants or bryophytes observers typically inventory confined areas (sites) reporting every species they observe, aiming to cover as many sites as possible. For other taxa like birds, observers may aim to complete a personal species list and often have preferred observation sites. Common species within these groups are not reported as often by voluntary citizen scientists as other more attractive species (Snäll et al. 2011). In these cases, a species observation index
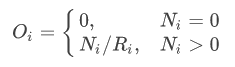
is preferred, where Ri is the number of species observed in grid cell i. The species observation index Oi offsets the sampling effort relative to the number of species reported per grid cell. Then, O is an index for the number of observations per species discovered Ri, which approximates to the true local richness as sampling effort increases. Although, this approach will not help to identify sites with syndromes like most observations belonging to a single species, these sites typically have also low number of observations and can be spotted using alternative estimates of local richness (but significantly increasing the computation time). In the GBIFapp I even include the possibility to estimate local richness from the maximum number of species observed in neighbouring cells (read the ReadMe file associated with this application, and use with CAUTION, more research is needed in this field). Note that this approach is not intended to estimate true richness or the proportion of missing species, for which the completeness measure (Sousa-Baena et al. 2014) does the job. This approach is meant to separate poorly-sampled areas from well-enough-sampled ones. The use of N or O is optional to the researcher, and its consequences can be further explored using any of the HTML applications here provided (or downloaded from the project's GitHub repository. For simplicity, hereafter we use "number of observations" interchangeably to refer to N or O.
In the original publication (Ruete 2015) I study three algorithms. Here I present only the most flexible and scalable of them: the half-ignorance algorithm. This approach is independent of the maximum number of observations and makes sampling effort relative to a reference number of observations O0.5 that is considered enough to reduce the ignorance score by half (hence the Half-ignorance approach). Ignorance scores are defined as Ii = O0.5 / (Ni + O0.5). In other words, setting the reference number O0.5 = 1 means that one observation for the RTG is enough to consider that the absence of reports of a target species from any grid cell is 50% due to true absence from the site and 50% due to failure to detect any species given a low sampling effort. Setting O0.5 < 1 denotes more confidence on every single observation, not gaining much information from a higher number of observations. Conversely, setting O0.5 > 1 denotes the need for more than one observation per grid cell to rely on such information (i.e. to significantly reduce the ignorance score). This algorithm allows the researcher to customise its credibility on each observation in a way that ignorance scores approach 0 asymptotically as the number of observation increases. In this way, the information content assumed for each new observation beyond O0.5 is less and less, and completely surveyed sites become no different from well-enough sampled sites. However, the bigger O0.5 the slower ignorance scores will approach 0.
Why would this approach be preferred upon others?
This approach is specially recommended when the aim is to compare datasets with very different number of observations, even between areas of different extent and shape. It helps to quickly and efficiently visualise where further sampling is needed, and where the data is already fit-for-use, at the intended scale. There are several approaches that incorporate sampling effort to different analysis of richness, species distributions and trends in population abundance (Hill 2012, Jeppsson et al. 2010, Ponder et al. 2001, Prendergast et al. 1993, Schulman et al. 2007, Snäll et al. 2011, Sousa-Baena et al. 2014, Stropp et al. 2016). However, these solutions are certainly too computationally intensive to provide custom web-based products with quick user experiences, as the ignorance score offer. As said before, approaches like completeness (Sousa-Baena et al. 2014, Stropp et al. 2016) are best at identifying how much is left to be observed, and may better identify the bias in sampling effort among individual species. However, it requires the computer intensive task of identifying inventories by creating unique combinations of taxon, place and time (e.g. days). Even so, the completeness analysis may still classify as "not-well-sampled" 25 x 25 km grid-cells with up to 200 records (Stropp et al. 2016).
Interestingly, this approach is independent of any expectation on the number of species to find, which are often estimated at large scales or over large regions, limiting the scalability of such an approach. In this way, ignorance scores can be summarized within polygons of any geographical or biological relevance, not only the larger regions (typically countries) for which species richness are often estimated. Anyhow, as said before, the observation index can make the number of observations relative to either the observed local richness or to any other estimate of local richness.
The ignorance score approach is fully scalable. Sensitivity to spatial resolution is a common problem on studies summarizing biodiversity data on arbitrary grid cells, and the relevance of this problem has to be evaluated for each study in light of the question or hypothesis tested (Hurlbert and Jetz 2007). For example, consider the simple case where one large grid cell is made up of four smaller cells of which three cells are empty and only one cell scores all the reported observations. In this case the spatial distribution of recording effort will look different when mapped at a high or low resolution. However, the parameter O0.5 is scalable so that the same assumptions can be maintained through scales. Explore the application GBIFapp to see how results are affected by changes in resolution. Despite the change in resolution, if observation indices (Oi) are used, and the number of grid cells per region is high enough not to bias the average (as it happens in e.g. small countries), mean ignorance scores are similar across scales.
Furthermore, Ignorance Maps serve a single variable containing the many and correlated geographical and environmental variables that explain the observational bias, that would be too many to include in a statistical model when trying to correct for it (Mair and Ruete 2016).
Potential uses
Visualization tools
Tools to visually evaluate biases and gaps on the data guide strategic mobilization of resources (Anderson et al 2016). However, if the gap analysis is a time-demanding task on its own, it will certainly hinder the willingness to even explore the database. Alternatively, web-based tools, standardized workflows and APIs services that could instantly offer comparisons, identify well-sampled areas and highlight areas that need further effort to fill the gap, will ease the use of GBIF data.
Consider the following example: currently, the GBIF API offers summaries of counts of observations per grid cells. Provided that the GBIF API can also offer species counts (either observed, estimated, or both), Ignorance Scores could be quickly accessed via web map tile services (WMS) and be implement in e.g. smartphone applications for citizen-scientist observers (Fig. 1).

Figure 1: modified screenshot from the game Pokémon Go adapted to show the potential implementation of Ignorance maps (red = 1, blue = 0) in augmented-reality applications helping citizen-scientists to collect data with smartphones.
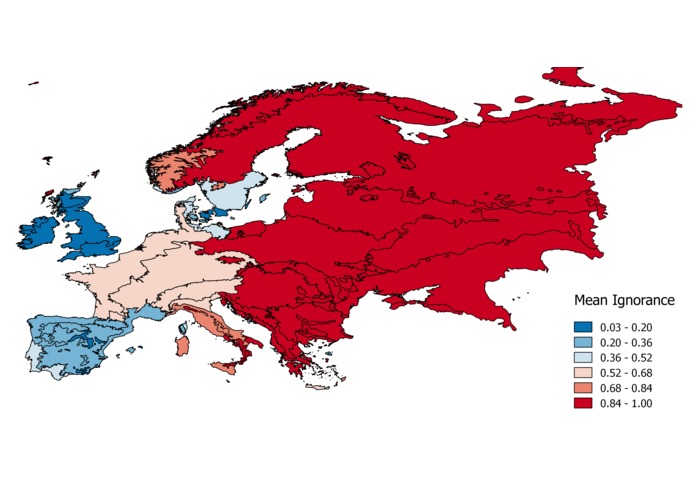
The same solution could be used to colour polygons representing e.g. ecoregions or countries based on the average ignorance of the area (Fig. 2), to produce systematic gaps analysis across RTGs.
a
![]() b
b
 c
c
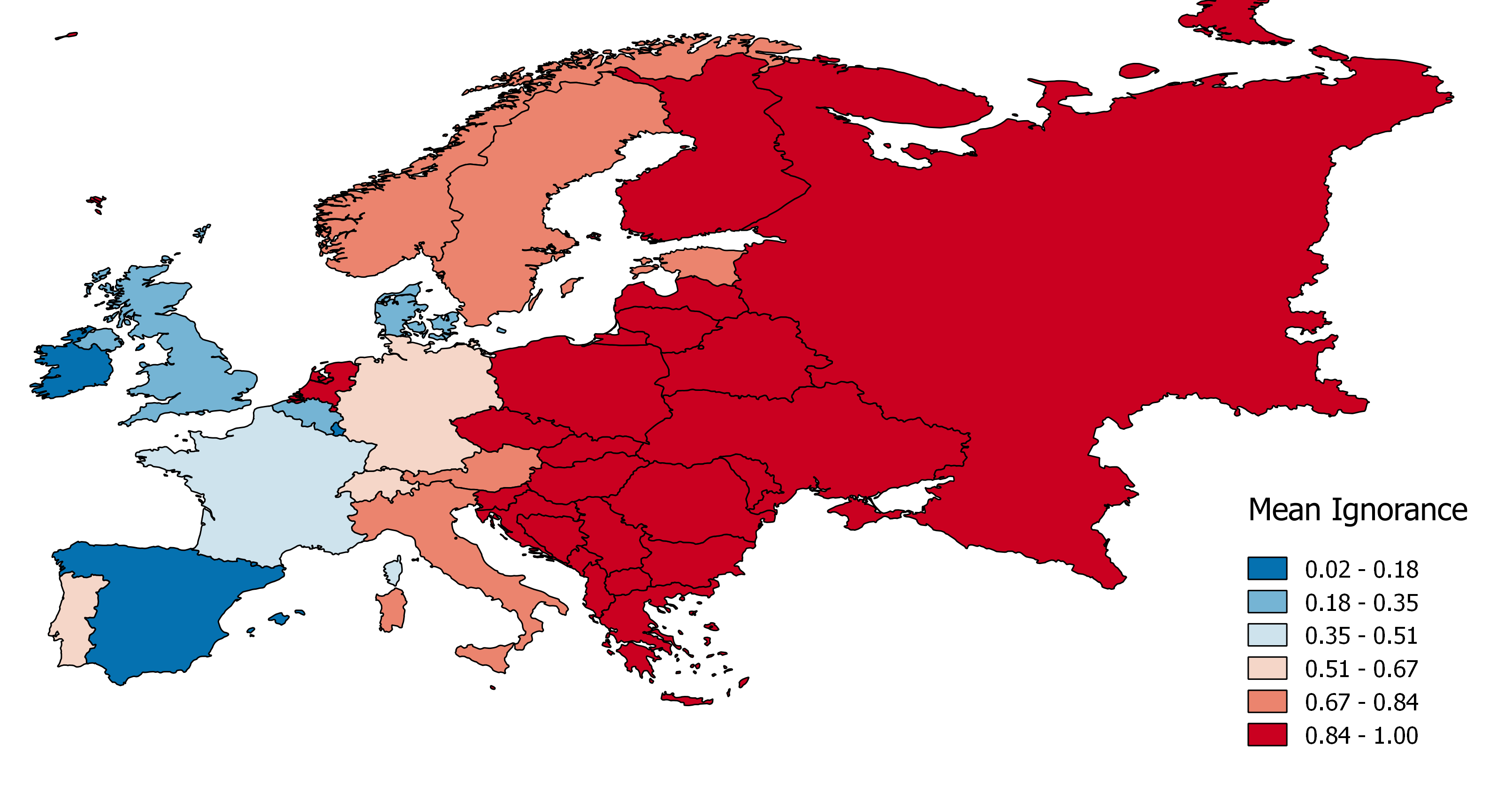 Figure 2: a) Ignorance maps for Amphibians in Europe (25x25 km grid cell), and mean ignorance per ecoregion (b; source WWF) and country (c).
Figure 2: a) Ignorance maps for Amphibians in Europe (25x25 km grid cell), and mean ignorance per ecoregion (b; source WWF) and country (c).
Small scale applied example: An imaginary environmental consultancy company was contracted to assess the environmental impact of a projected power-line. The consultancy wants to decide whether to spend time doing field surveys for birds over the affected area or to draw conclusions using the primary biodiversity data stored at a GBIF's national node. The affected area is 1 km wide. A quick look at the ignorance map for birds (Fig. 3) shows a typical good sampling effort over urban areas and water bodies, but rather poor over forests (the habitat mostly affected by the project). Any attempt to assess species presence on this area would certainly require either a thorough survey or rely on habitat associations based on observations collected on similar habitats but further away.
 Figure 3: Imaginary projected power-line (bright green) over a land-use map (left panel; red: urban, beige: open field, greens: different types of forests, blue: water), and a 1x1 km resolution ignorance map for all birds (right panel; red: IS = 1, white: IS = 0.5, blue: IS = 0; data source: Swedish LifeWatch).
Figure 3: Imaginary projected power-line (bright green) over a land-use map (left panel; red: urban, beige: open field, greens: different types of forests, blue: water), and a 1x1 km resolution ignorance map for all birds (right panel; red: IS = 1, white: IS = 0.5, blue: IS = 0; data source: Swedish LifeWatch).
Research tools
Disclaimer: work in progress with variable speed depending on funding availability. Supporters and collaborations are welcome.
The most obvious use for ignorance maps for more sophisticated analyses is to mask out areas of high uncertainty from layers derived from the raw data, excluding them from further analyses. A first presence and pseudo-absence map for individual species could be quickly derived from the primary data as shown in the GBIFapp (fifth layer under Layers, on the Spatial Bias tab). In this example, multiplying the opposite of the ignorance map (certainty = 1 - ignorance) by the ignorance scores applied to observations of a focal species will weight these to the knowledge available.
Ignorance maps could be of particular interest for species distribution models (SDM), as estimates can be improved by incorporating information on how recording effort varies spatially (Hertzog et al 2014, Stolar and Nielsen 2015). Major improvements in the goodness of fit of machine learning species distribution models (e.g. MaxEnt) can be achieved by directly incorporating "bias surfaces" for background sampling (Phillips et al. 2009, Syfert et al. 2013). Presence only data from non-systematic sampling effort may be biased by many geographical variables, such as altitude, road density and distance to major cities, that are most likely correlated to each other (Mair and Ruete, 2016). Therefore, it may be more informative to use a spatial bias layer such as an ignorance map, and incorporate this layer into the model as an explanatory variable than trying to identify which geographical variables are explaining the bias.
Which model to use and how to use the ignorance scores goes hand by hand. First, ignorance maps could be used to generate "pseudo-absences" as described before. If both presence and pseudo-absences cover well enough the study area, the researcher can opt for any regression-type model. Else, zeros (absences) could be generated far enough from the species detections, and be used to fit a zero-inflated model. Then the ignorance map could inform the model where zeros are likely caused because of lack of sampling, to help the model discern where true absences are to be expected.
Within the Bayesian framework SDMs could also benefit by using ignorance scores to inform a priori probability distributions (Argáez et al. 2005, McCarthy and Masters 2005). For example, a priori probabilities of occurrence of a species for unobserved sites could be generated assuming that occurrences follow a Bernoulli distribution with. Then, for each estimation iteration, an unobserved site with high ignorance, i.e. IS = 1, could take the value 0 or 1 with the same probability; while an unobserved site with low ignorance score will most likely take the value 0. Then, maps produced from such SDMs can indicate which areas of the study region are most affected by under-sampling and therefore have the greatest predictive uncertainty.
These applications are planned to be fully explored in the future.
References
- Anderson RP, Araújo M, Guisan A, Lobo J, Martínez-Meyer E, Peterson AT, Soberón J (2016) Report of the task group on GBIF data fitness for use in distribution modelling. 27pp. GBIF Secretariat, Copenhagen.
- Argáez J, Andrés Christen J, Nakamura M, Soberón J (2005) Prediction of potential areas of species distributions based on presence-only data. Environmental and Ecological Statistics 12 (1):27-44. doi:10.1007/s10651-005-6816-2
- Hertzog L, Besnard A, Jay-Robert P (2014) Field validation shows bias-corrected pseudo-absence selection is the best method for predictive species-distribution modelling. Diversity and Distributions 20 (12):1403-1413. doi:10.1111/ddi.12249
- Hill M (2012) Local frequency as a key to interpreting species occurrence data when recording effort is not known. Methods in Ecology and Evolution 3 (1):195-205. doi:10.1111/j.2041-210X.2011.00146.x
- Hortal J, Lobo J, Jiménez-Valverde A (2007) Limitations of biodiversity databases: case study on seed-plant diversity in tenerife, canary islands. Conservation Biology 21 (3):853-863. doi:10.1111/j.1523-1739.2007.00686.x
- Hurlbert A, Jetz W (2007) Species richness, hotspots, and the scale dependence of range maps in ecology and conservation. Proceedings of the National Academy of Sciences 104 (33):13384-13389. doi:10.1073/pnas.0704469104
- Jeppsson T, Lindhe A, Gärdenfors U, Forslund P (2010) The use of historical collections to estimate population trends: A case study using Swedish longhorn beetles (Coleoptera: Cerambycidae). Biological Conservation 143 (9):1940-1950. doi:10.1016/j.biocon.2010.04.015
- Mair L, Ruete A (2016) Explaining spatial variation in the recording effort of citizen science data across multiple taxa. PLoS ONE 11(1): e0147796. doi:10.1371/journal.pone.0147796
- McCarthy M, Masters P (2005) Profiting from prior information in Bayesian analyses of ecological data. Journal of Applied Ecology 42 (6):1012-1019. doi:10.1111/j.1365-2664.2005.01101.x
- Phillips S, Dudík M, Elith J, Graham C, Lehmann A, Leathwick J, Ferrier S (2009) Sample selection bias and presence-only distribution models: implications for background and pseudo-absence data. Ecological Applications 19 (1):181-197. doi:10.1890/07-2153.1
- Ponder WF, Carter GA, Flemons P, Chapman RR (2001) Evaluation of museum collection data for use in biodiversity assessment. Conservation Biology 15 (3):648-657. doi:10.1046/j.1523-1739.2001.015003648.x
- Prendergast JR, Wood SN, Lawton JH, Eversham BC (1993) Correcting for variation in recording effort in analyses of diversity hotspots. Biodiversity Letters 1 (2):39. doi:10.2307/2999649
- Rocchini D, Hortal J, Lengyel S, Lobo J, Jiménez-Valverde A, Ricotta C, Bacaro G, Chiarucci A (2011) Accounting for uncertainty when mapping species distributions: The need for maps of ignorance. Progress in Physical Geography 35 (2):211-226. doi:10.1177/0309133311399491
- Ruete A (2015) Displaying bias in sampling effort of data accessed from biodiversity databases using ignorance maps. Biodiversity Data Journal 3:e5361. doi:10.3897/BDJ.3.e5361
- Schulman L, Toivonen T, Ruokolainen K (2007) Analysing botanical collecting effort in Amazonia and correcting for it in species range estimation. Journal of Biogeography 34(8):1388-1399. doi:10.1111/j.1365-2699.2007.01716.x
- Snäll T, Kindvall O, Nilsson J, Pärt T (2011) Evaluating citizen-based presence data for bird monitoring. Biological Conservation 144 (2):804-810. doi:10.1016/j.biocon.2010.11.010
- Sousa-Baena MS, Garcia LC, Peterson AT (2014) Completeness of digital accessible knowledge of the plants of Brazil and priorities for survey and inventory. Diversity and Distributions 20:369-381. doi:10.1111/ddi.12136
- Stropp J, Ladle RJ, Malhado ACM, Hortal J, Gaffuri J, Temperley WH, Olav Skøien J & Mayaux P (2016), Mapping ignorance: 300 years of collecting flowering plants in Africa. Global Ecology and Biogeography. doi:10.1111/geb.12468
- Stolar J, Nielsen S (2015) Accounting for spatially biased sampling effort in presence-only species distribution modelling. Diversity and Distributions 21 (5):595-608. doi:10.1111/ddi.12279
- Suarez A, Tsutsui N (2004) The value of museum collections for research and society. BioScience 54 (1):66. doi:10.1641/0006-3568(2004)054[0066:TVOMCF]2.0.CO;2
- Syfert M, Smith M, Coomes D (2013) The effects of sampling bias and model complexity on the predictive performance of Maxent species distribution models. PLoSONE 8 (2):e55158. doi:10.1371/journal.pone.0055158
Built With
- leaflet.js
- r
- shiny








Log in or sign up for Devpost to join the conversation.