-
-

Manas Orb, always ready to listen
-
authentication screen
-
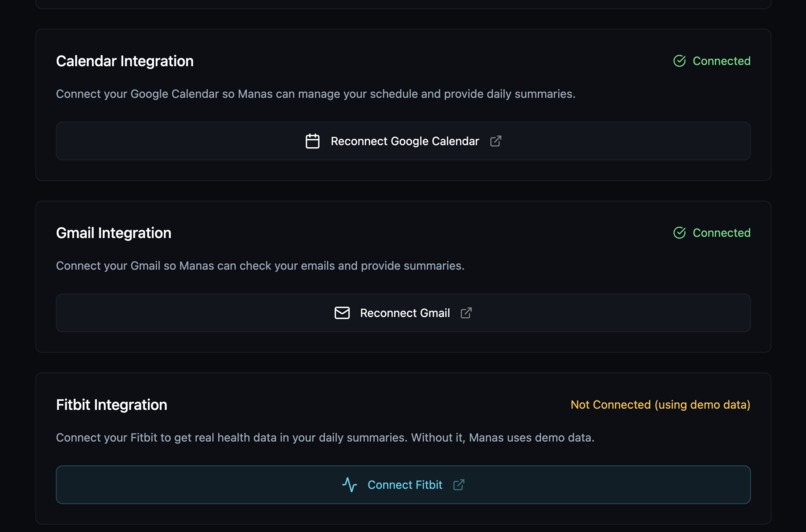
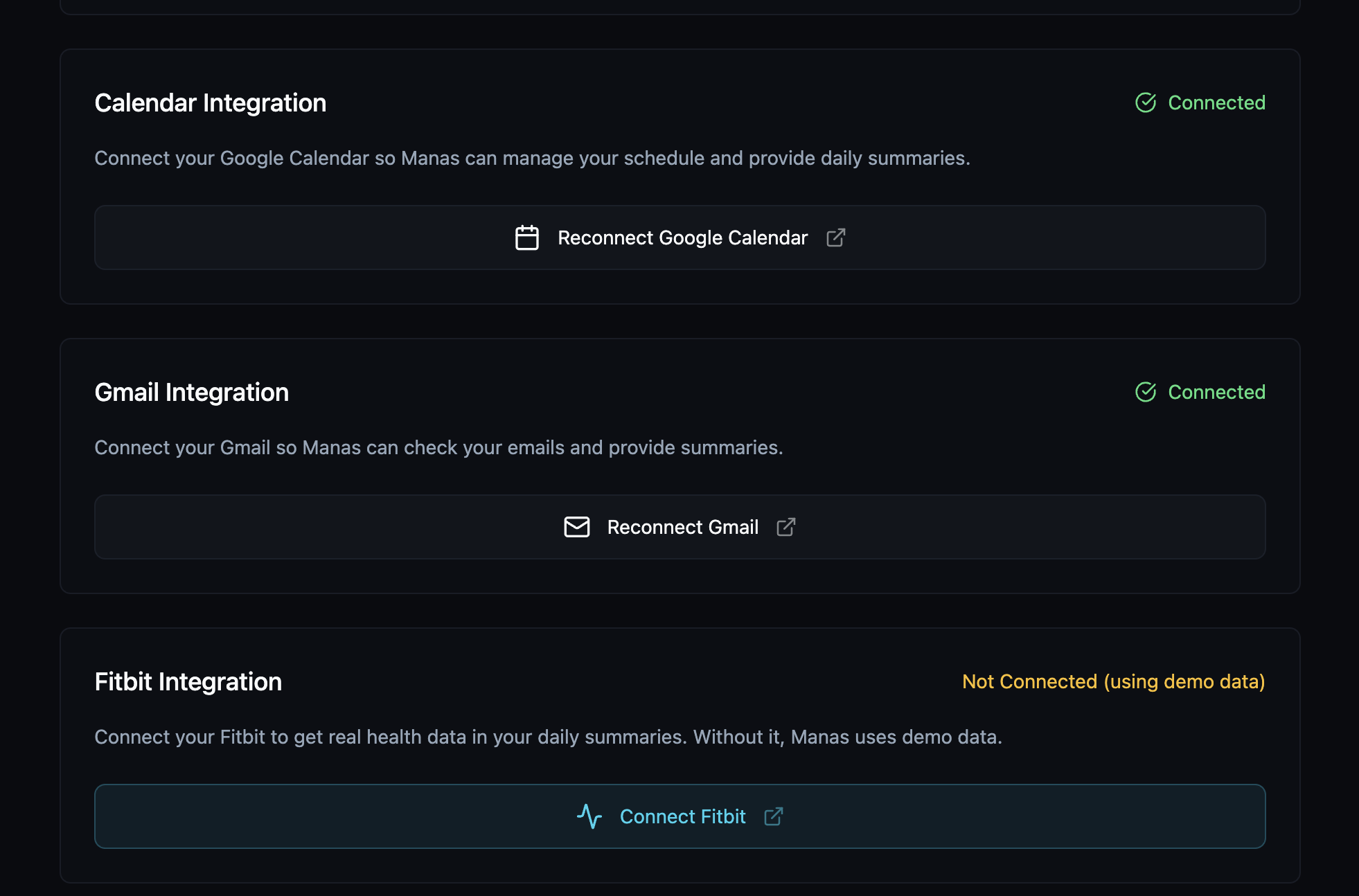
connections establishment screen
-
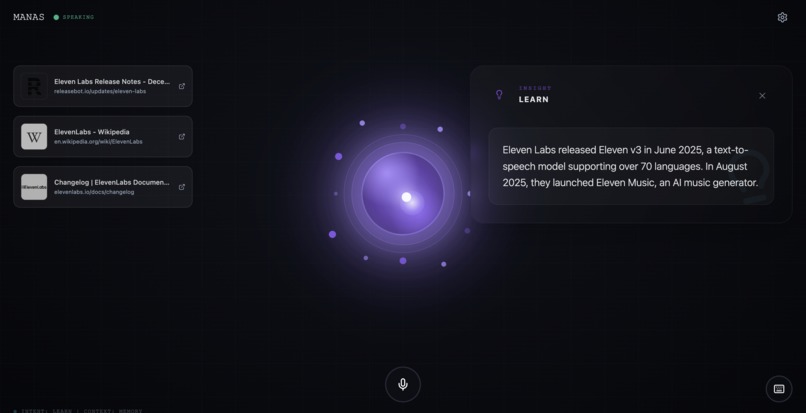
Web search with citations
-
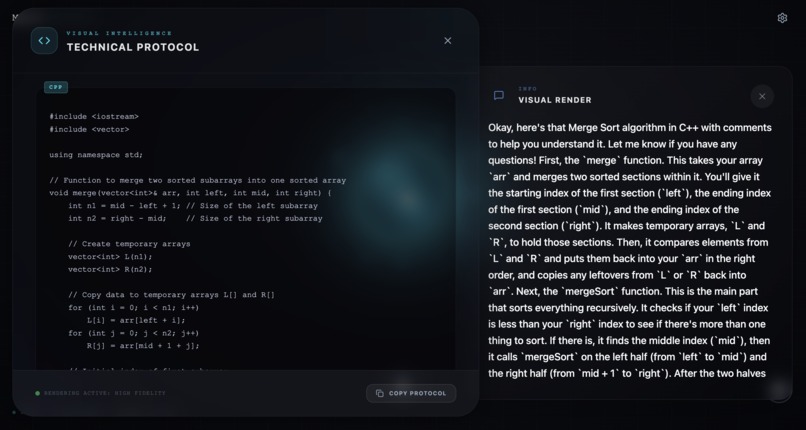
we can ask for code help also.
-

promo poster



MANAS is a voice-first personal AI assistant where users can interact entirely through speech: talk naturally, get an intelligent response, and hear it back in a high-quality human voice.
This project was built specifically to combine:
- Google Cloud AI for real-time speech understanding and intelligence
- ElevenLabs for natural, human-like voice output and personality
In practice, MANAS uses a low-latency pipeline:
- User speaks in the web app
- Google Cloud Speech-to-Text transcribes the audio (
WEBM_OPUS) with streaming recognition - Gemini handles intent classification + reasoning and generates the response
- ElevenLabs Text-to-Speech speaks the response back in a selectable voice (MP3), so MANAS feels conversational and human
What inspired us
Many “assistants” are still text-first: they require typing, clicking, and context switching. We wanted to prove that a voice-native experience can do real work—fast—by making the whole loop (listen → understand → act → speak) feel like a natural conversation.
What we built (voice-native features)
- Voice-driven UX: microphone-first interaction; the UI is built around speaking and listening.
- Intent-based intelligence: Gemini classifies what the user wants (tasks, calendar, email, news, learn, etc.) and routes to the right capability.
- Human voice output: ElevenLabs TTS produces natural speech with configurable voices.
- Action + memory (beyond chatting):
- task management (Firestore)
- calendar operations (Google Calendar via OAuth)
- email workflows (Gmail via OAuth)
- news briefings (News API + optional Gemini summarization)
- learning mode with citations (You.com search + Gemini)
- long-term memory (Mem0 + Qdrant-backed vector search)
- document/image analysis via file upload (Gemini grounded on provided files)
- Fitbit health data integration
How we built it (Google Cloud + ElevenLabs integration)
Google Cloud: speech understanding + trusted infrastructure
Google Cloud Speech-to-Text is the entry point for all voice interactions.
- We optimized for web audio with
WEBM_OPUSencoding, automatic punctuation, and streaming recognition. - The goal is fast, accurate transcripts that can power reliable intent detection.
- We optimized for web audio with
Gemini provides the “brain”:
- Intent classification: quick, structured JSON output so routing is predictable.
- Conversational responses: short, spoken-friendly replies by default.
- Document grounding: when a user uploads files, the system forces a focused analysis mode and answers based on the file content.
Firestore / Firebase provides secure persistence:
- user-scoped task storage
- user profile preferences (like preferred voice)
- OAuth credential storage for Google Calendar + Gmail
ElevenLabs: voice + personality
- ElevenLabs Text-to-Speech turns every assistant response into natural audio output (MP3).
- Users can choose from multiple voice IDs, enabling different personalities and tones.
- We also include a streaming-ready pathway to reduce perceived latency for longer responses.
Design (UX)
MANAS is designed as a voice-first interface, not a chatbot with a microphone icon.
- Immediate feedback loop: the UI shows listening/thinking/speaking states so users always know what’s happening.
- Spoken-first responses: responses are kept short for clarity when played aloud.
- Structured cards: when the assistant performs an action or returns structured data (news, citations, tasks), the UI presents it cleanly while the voice summarizes.
- Analysis mode: users can drop a document/image; the UI confirms “analysis mode active” and the assistant focuses on that content.
Challenges we faced
- End-to-end latency across STT → Gemini → tools → ElevenLabs TTS:
- Voice apps feel “broken” if they pause too long, so we used fast classification, short spoken responses, and streaming-friendly paths.
- Reliability of intent routing:
- We needed deterministic routing (JSON intent) while still sounding natural in conversation.
- Voice UX edge cases:
- Handling short/empty audio, microphone permission issues, and graceful fallbacks without breaking flow.
What we learned
- Voice is the product: quality isn’t only model accuracy—latency, feedback states, and the “feel” of the voice matter just as much.
- Structured orchestration is key: pairing Gemini reasoning with explicit tool routing makes the system useful beyond Q&A.
- Personality must be intentional: ElevenLabs provides the human voice, but the system must constrain responses to be spoken-friendly.
Potential impact
MANAS can meaningfully help communities where typing and screens are a barrier:
- Accessibility: voice-first workflows for users with visual or motor impairments.
- Field work + mobility: hands-free task management, scheduling, and information retrieval.
- Productivity: reduce friction for managing daily tasks, email triage, and quick planning.
Why the idea is unique
MANAS isn’t “STT + chatbot + TTS.” It’s a voice-native system built around:
- Google Cloud Speech-to-Text for real-time understanding
- Gemini for intent routing + reasoning
- ElevenLabs for natural, human-like voice output
- Tools + memory so the assistant can act, not just talk



Log in or sign up for Devpost to join the conversation.