Inspiration
This project was born out of a desire to provide doctors with a personal AI companion that leverages data analytics and machine learning to improve breast cancer treatment recommendations. Inspired by Hacklytics GT 2025, we aimed to develop a highly accurate predictive model to assist clinicians in identifying key risk factors and optimizing treatment decisions.
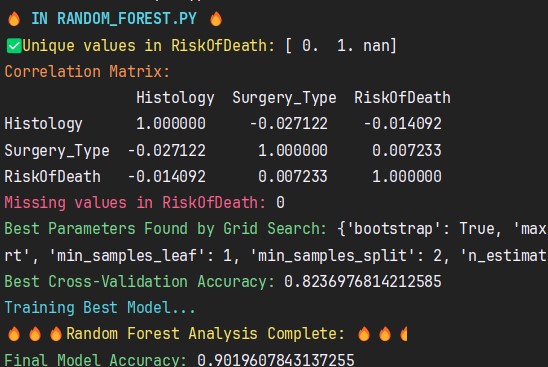
Through extensive machine learning training and fine-tuning, we developed an optimized Random Forest model that achieves over 90% accuracy in predicting patient survival outcomes, ensuring reliable and interpretable insights for clinicians.
What it does
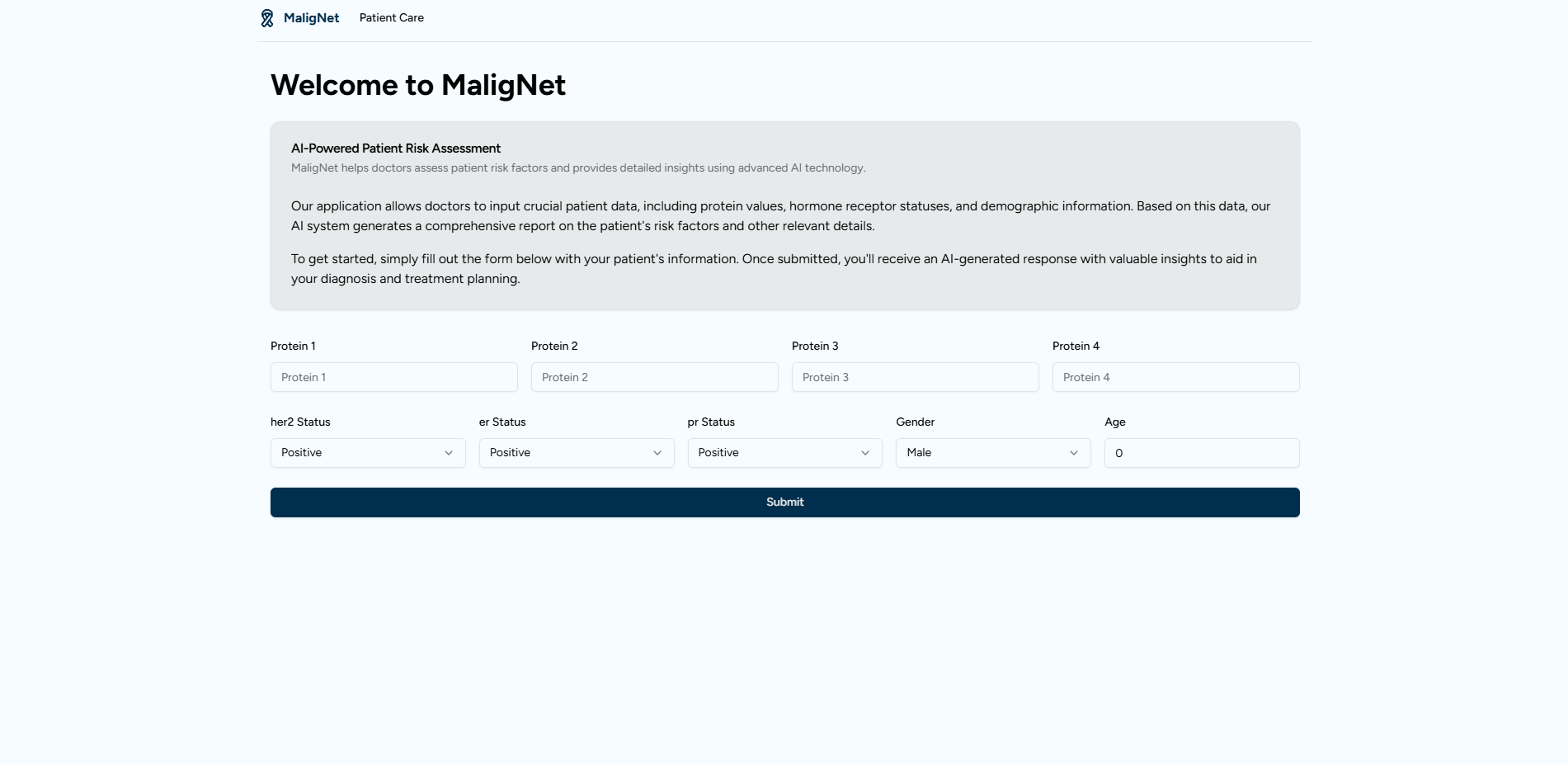
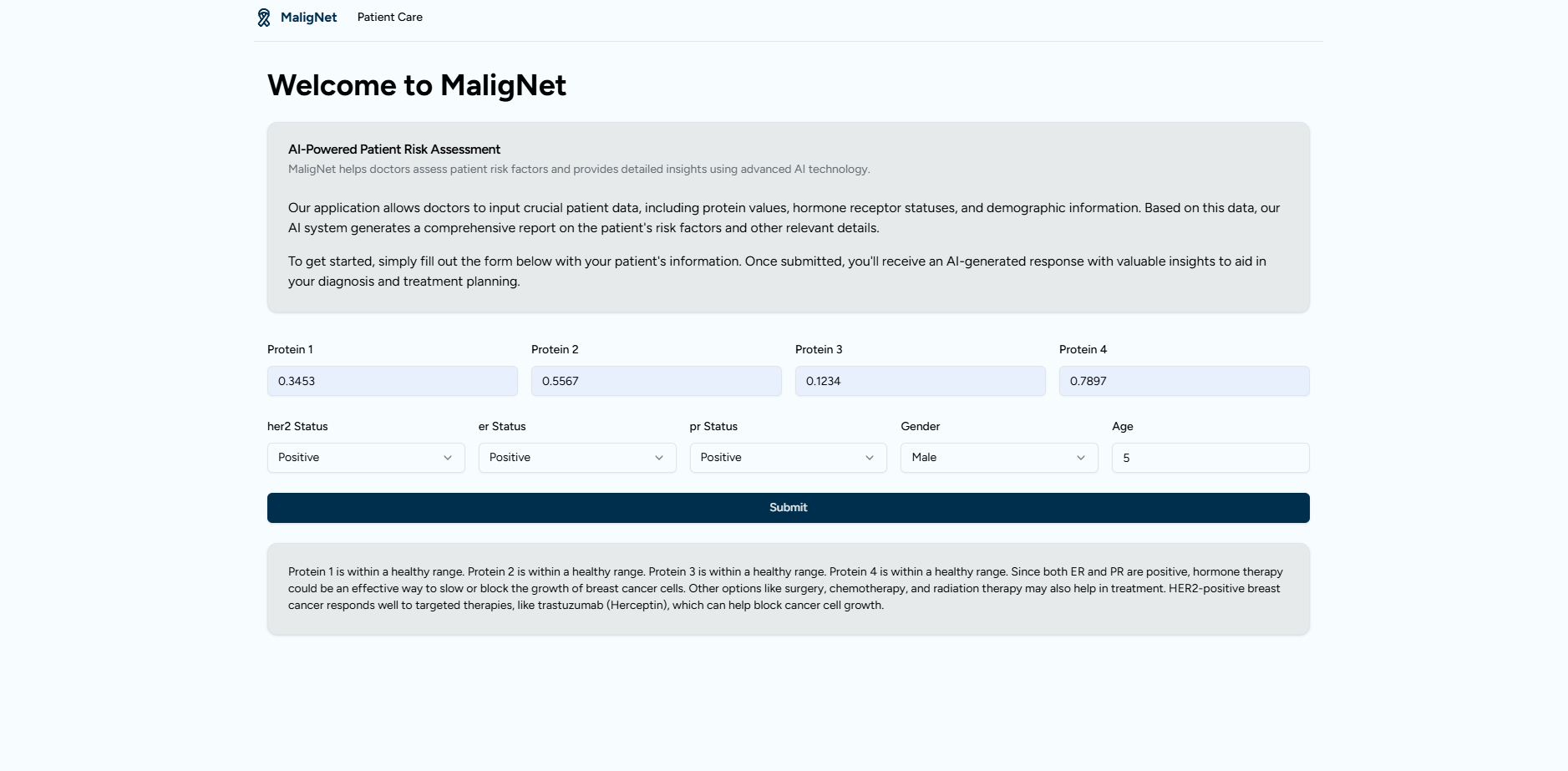
This project analyzes clinical and protein data to provide insights into breast cancer patient outcomes. The model:
- Predicts patient survival risk based on various clinical features.
- Identifies key contributing factors using feature importance analysis.
- Enhances clinical decision-making by offering data-driven insights.
How we built it
- Data Sourcing & Integration: We started with a well-known breast cancer dataset from Kaggle, which provided a solid foundation of biomarkers and clinical outcomes. This dataset was then combined with other relevant clinical data to form a comprehensive repository.
- Machine Learning & Analytics: Using Python, state-of-the-art machine learning frameworks, and leveraging Streamlit for visualization, we built and validated predictive models that translate raw data into actionable treatment insights.
- User Interface Development: Our front-end, developed with modern web technologies, leveraging Next.js, Shad/cn, and Typescript, offers an accessible and intuitive experience, allowing clinicians to easily interpret the recommendations.
- Backend Architecture: Designed for scalability and security, our backend efficiently manages data processing while safeguarding sensitive patient information by harnessing MongoDB for storage and Flask to handle API calls.
Challenges we ran into
- Dynamically connecting both frontend and backend successfully - (This feature will be implemented in the future).
- Balancing the Dataset: Implementing SMOTE was crucial to handle class imbalances in patient outcomes.
Hyperparameter Tuning: Optimizing n_estimators, max_depth, and feature selection was an iterative process.
Accomplishments that we're proud of
- Optimized Machine Learning Model: Achieved 90%+ accuracy with robust cross-validation performance.
- Feature Engineering Success: Created new features that significantly improved prediction accuracy.
- Beautiful Console Logging for ML Training: Developed a clear, structured debugging process for model interpretation.
- Interdisciplinary Collaboration: Brought together machine learning, software development, and UI design to enhance the final product.
What we learned
- Advanced ML Techniques: Fine-tuning Random Forest models significantly impacts accuracy.
- Readable Debugging: Clear console outputs improve workflow efficiency and model interpretability.
- UI/UX for Machine Learning: Making complex ML results accessible through intuitive visualizations enhances usability.
What's next for MaligNet
Use real-world inputs to fine-tune predictive algorithms, ensuring even more precise treatment recommendations. After this is developed, MaligNet plans to integrate generative AI to give a better tailored experience where healthcare teams can get further explanations, recommendations and even the opportunity to input data that is not specifically in the dataset. With the integration of gen AI, MaligNet also aims to make it multi-modal since these providers usually have information in multiple formats.
Link of ML Model Explanation link
Built With
- flask
- kaggle
- matplotlib
- next.js
- numpy
- pandas
- plotly
- python
- scikit-learn
- streamlit
- typescript


Log in or sign up for Devpost to join the conversation.